 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Blockwise Temporal-Spatial Pathway Network
Aug 05, 2022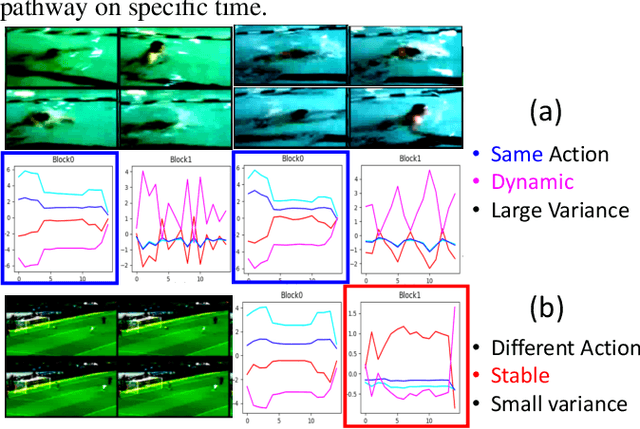
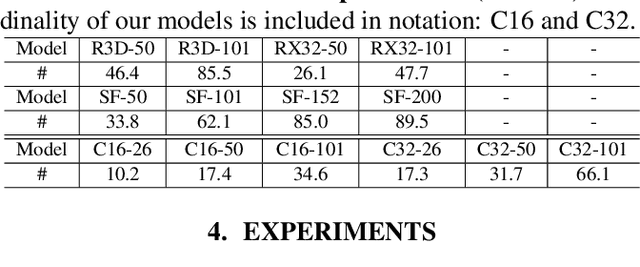
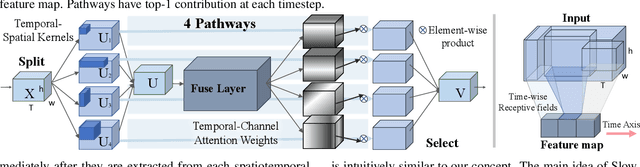
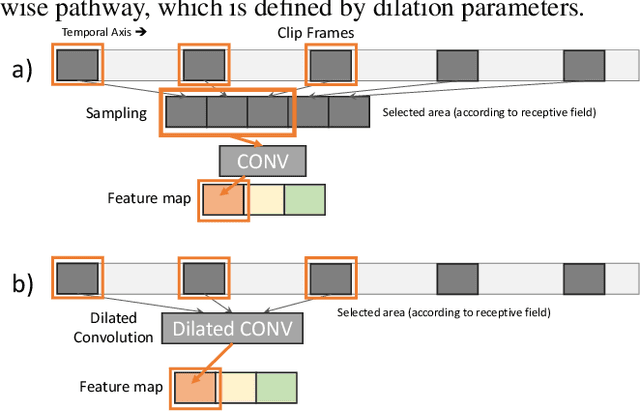
Algorithms for video action recognition should consider not only spatial information but also temporal relations, which remains challenging. We propose a 3D-CNN-based action recognition model, called the blockwise temporal-spatial path-way network (BTSNet), which can adjust the temporal and spatial receptive fields by multiple pathways. We designed a novel model inspired by an adaptive kernel selection-based model, which is an architecture for effective feature encoding that adaptively chooses spatial receptive fields for image recognition. Expanding this approach to the temporal domain, our model extracts temporal and channel-wise attention and fuses information on various candidate operations. For evaluation, we tested our proposed model on UCF-101, HMDB-51, SVW, and Epic-Kitchen datasets and showed that it generalized well without pretraining. BTSNet also provides interpretable visualization based on spatiotemporal channel-wise attention. We confirm that the blockwise temporal-spatial pathway supports a better representation for 3D convolutional blocks based on this visualization.
hSDB-instrument: Instrument Localization Database for Laparoscopic and Robotic Surgeries
Oct 26, 2021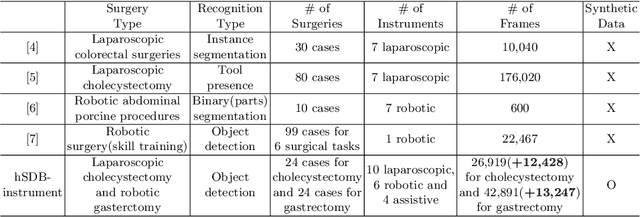
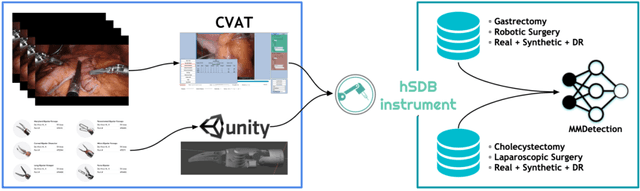
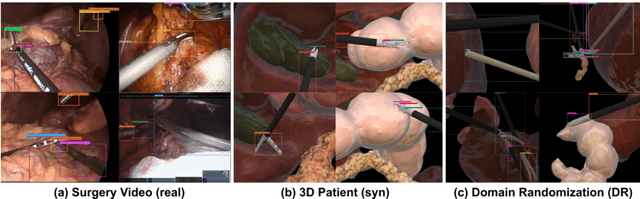
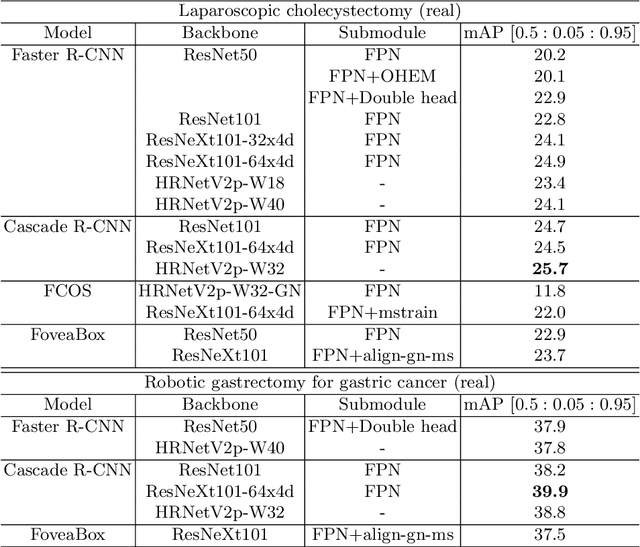
Automated surgical instrument localization is an important technology to understand the surgical process and in order to analyze them to provide meaningful guidance during surgery or surgical index after surgery to the surgeon. We introduce a new dataset that reflects the kinematic characteristics of surgical instruments for automated surgical instrument localization of surgical videos. The hSDB(hutom Surgery DataBase)-instrument dataset consists of instrument localization information from 24 cases of laparoscopic cholecystecomy and 24 cases of robotic gastrectomy. Localization information for all instruments is provided in the form of a bounding box for object detection. To handle class imbalance problem between instruments, synthesized instruments modeled in Unity for 3D models are included as training data. Besides, for 3D instrument data, a polygon annotation is provided to enable instance segmentation of the tool. To reflect the kinematic characteristics of all instruments, they are annotated with head and body parts for laparoscopic instruments, and with head, wrist, and body parts for robotic instruments separately. Annotation data of assistive tools (specimen bag, needle, etc.) that are frequently used for surgery are also included. Moreover, we provide statistical information on the hSDB-instrument dataset and the baseline localization performances of the object detection networks trained by the MMDetection library and resulting analyses.
* https://hsdb-instrument.github.io
Deep Active Learning with Augmentation-based Consistency Estimation
Nov 05, 2020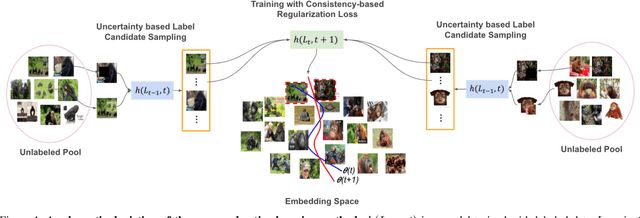
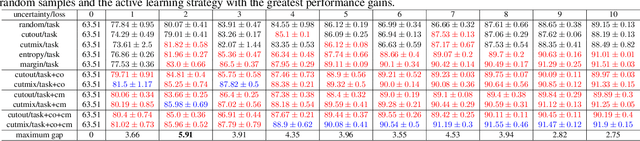
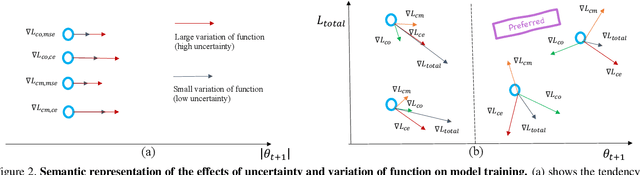

In active learning, the focus is mainly on the selection strategy of unlabeled data for enhancing the generalization capability of the next learning cycle. For this, various uncertainty measurement methods have been proposed. On the other hand, with the advent of data augmentation metrics as the regularizer on general deep learning, we notice that there can be a mutual influence between the method of unlabeled data selection and the data augmentation-based regularization techniques in active learning scenarios. Through various experiments, we confirmed that consistency-based regularization from analytical learning theory could affect the generalization capability of the classifier in combination with the existing uncertainty measurement method. By this fact, we propose a methodology to improve generalization ability, by applying data augmentation-based techniques to an active learning scenario. For the data augmentation-based regularization loss, we redefined cutout (co) and cutmix (cm) strategies as quantitative metrics and applied at both model training and unlabeled data selection steps. We have shown that the augmentation-based regularizer can lead to improved performance on the training step of active learning, while that same approach can be effectively combined with the uncertainty measurement metrics proposed so far. We used datasets such as FashionMNIST, CIFAR10, CIFAR100, and STL10 to verify the performance of the proposed active learning technique for multiple image classification tasks. Our experiments show consistent performance gains for each dataset and budget scenario.