 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Soft Label in Label Distribution Learning Perspective
Jan 31, 2023The primary goal of training in early convolutional neural networks (CNN) is the higher generalization performance of the model. However, as the expected calibration error (ECE), which quantifies the explanatory power of model inference, was recently introduced, research on training models that can be explained is in progress. We hypothesized that a gap in supervision criteria during training and inference leads to overconfidence, and investigated that performing label distribution learning (LDL) would enhance the model calibration in CNN training. To verify this assumption, we used a simple LDL setting with recent data augmentation techniques. Based on a series of experiments, the following results are obtained: 1) State-of-the-art KD methods significantly impede model calibration. 2) Training using LDL with recent data augmentation can have excellent effects on model calibration and even in generalization performance. 3) Online LDL brings additional improvements in model calibration and accuracy with long training, especially in large-size models. Using the proposed approach, we simultaneously achieved a lower ECE and higher generalization performance for the image classification datasets CIFAR10, 100, STL10, and ImageNet. We performed several visualizations and analyses and witnessed several interesting behaviors in CNN training with the LDL.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Blockwise Temporal-Spatial Pathway Network
Aug 05, 2022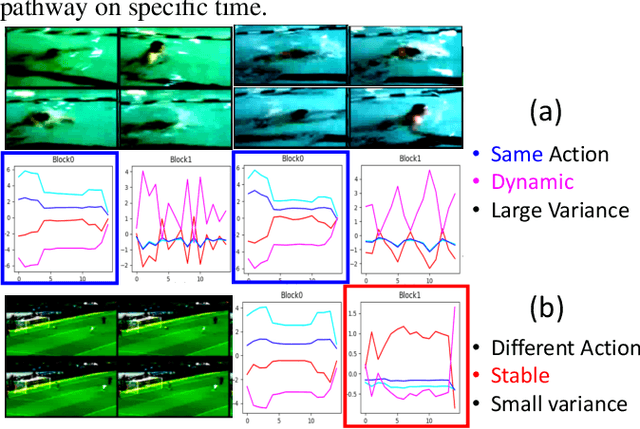
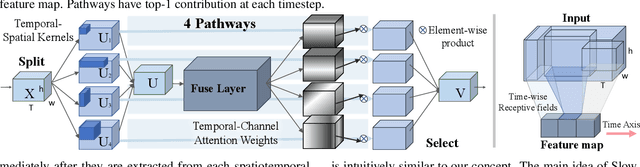
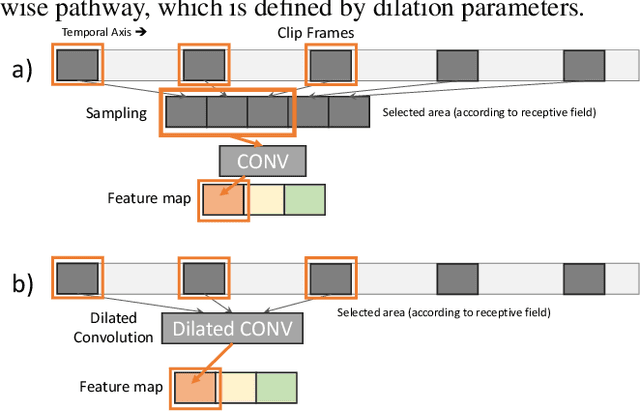
Algorithms for video action recognition should consider not only spatial information but also temporal relations, which remains challenging. We propose a 3D-CNN-based action recognition model, called the blockwise temporal-spatial path-way network (BTSNet), which can adjust the temporal and spatial receptive fields by multiple pathways. We designed a novel model inspired by an adaptive kernel selection-based model, which is an architecture for effective feature encoding that adaptively chooses spatial receptive fields for image recognition. Expanding this approach to the temporal domain, our model extracts temporal and channel-wise attention and fuses information on various candidate operations. For evaluation, we tested our proposed model on UCF-101, HMDB-51, SVW, and Epic-Kitchen datasets and showed that it generalized well without pretraining. BTSNet also provides interpretable visualization based on spatiotemporal channel-wise attention. We confirm that the blockwise temporal-spatial pathway supports a better representation for 3D convolutional blocks based on this visualization.
PEg TRAnsfer Workflow recognition challenge report: Does multi-modal data improve recognition?
Feb 11, 2022
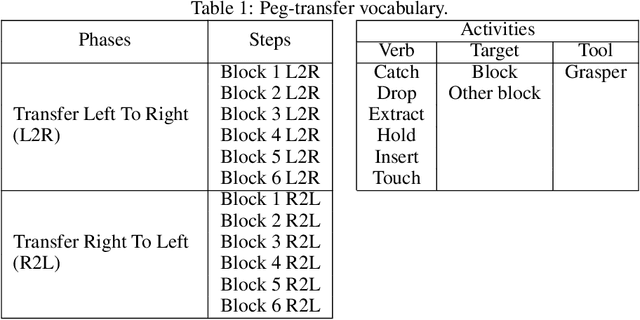
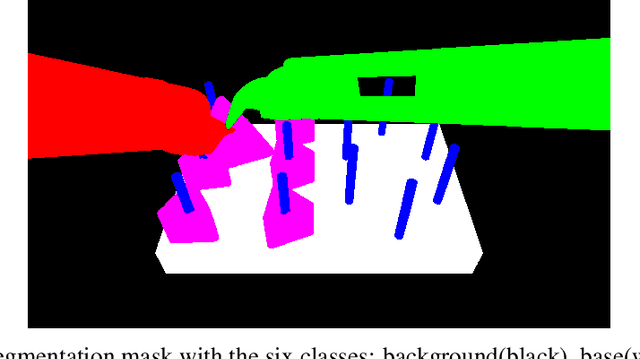
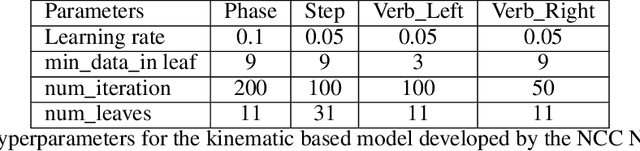
This paper presents the design and results of the "PEg TRAnsfert Workflow recognition" (PETRAW) challenge whose objective was to develop surgical workflow recognition methods based on one or several modalities, among video, kinematic, and segmentation data, in order to study their added value. The PETRAW challenge provided a data set of 150 peg transfer sequences performed on a virtual simulator. This data set was composed of videos, kinematics, semantic segmentation, and workflow annotations which described the sequences at three different granularity levels: phase, step, and activity. Five tasks were proposed to the participants: three of them were related to the recognition of all granularities with one of the available modalities, while the others addressed the recognition with a combination of modalities. Average application-dependent balanced accuracy (AD-Accuracy) was used as evaluation metric to take unbalanced classes into account and because it is more clinically relevant than a frame-by-frame score. Seven teams participated in at least one task and four of them in all tasks. Best results are obtained with the use of the video and the kinematics data with an AD-Accuracy between 93% and 90% for the four teams who participated in all tasks. The improvement between video/kinematic-based methods and the uni-modality ones was significant for all of the teams. However, the difference in testing execution time between the video/kinematic-based and the kinematic-based methods has to be taken into consideration. Is it relevant to spend 20 to 200 times more computing time for less than 3% of improvement? The PETRAW data set is publicly available at www.synapse.org/PETRAW to encourage further research in surgical workflow recognition.
hSDB-instrument: Instrument Localization Database for Laparoscopic and Robotic Surgeries
Oct 26, 2021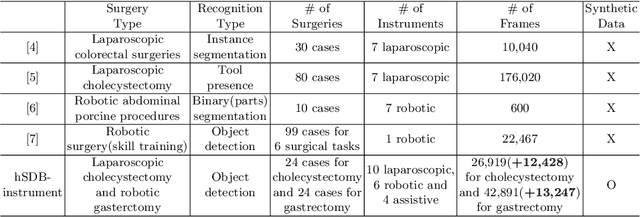
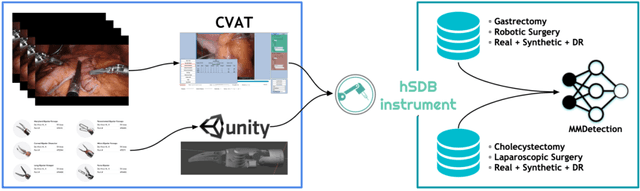
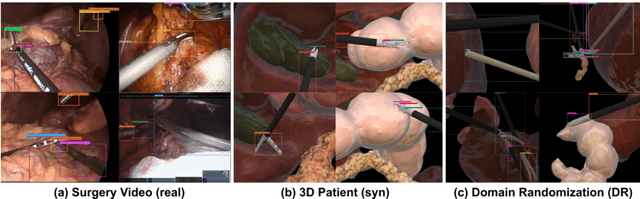
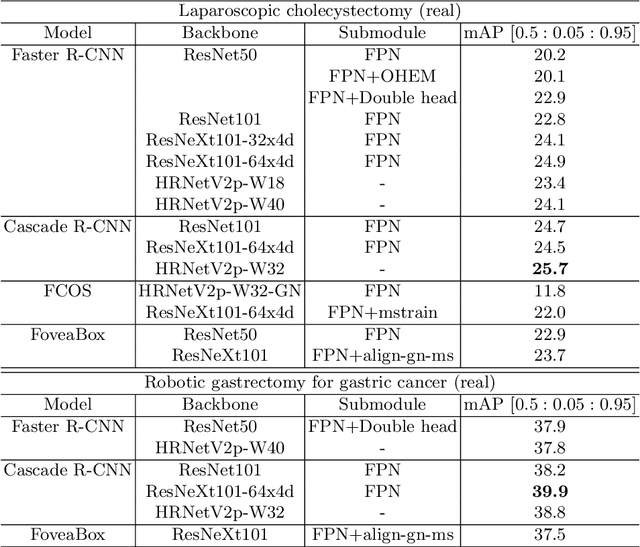
Automated surgical instrument localization is an important technology to understand the surgical process and in order to analyze them to provide meaningful guidance during surgery or surgical index after surgery to the surgeon. We introduce a new dataset that reflects the kinematic characteristics of surgical instruments for automated surgical instrument localization of surgical videos. The hSDB(hutom Surgery DataBase)-instrument dataset consists of instrument localization information from 24 cases of laparoscopic cholecystecomy and 24 cases of robotic gastrectomy. Localization information for all instruments is provided in the form of a bounding box for object detection. To handle class imbalance problem between instruments, synthesized instruments modeled in Unity for 3D models are included as training data. Besides, for 3D instrument data, a polygon annotation is provided to enable instance segmentation of the tool. To reflect the kinematic characteristics of all instruments, they are annotated with head and body parts for laparoscopic instruments, and with head, wrist, and body parts for robotic instruments separately. Annotation data of assistive tools (specimen bag, needle, etc.) that are frequently used for surgery are also included. Moreover, we provide statistical information on the hSDB-instrument dataset and the baseline localization performances of the object detection networks trained by the MMDetection library and resulting analyses.
* https://hsdb-instrument.github.io
Self-Supervised Knowledge Transfer via Loosely Supervised Auxiliary Tasks
Oct 25, 2021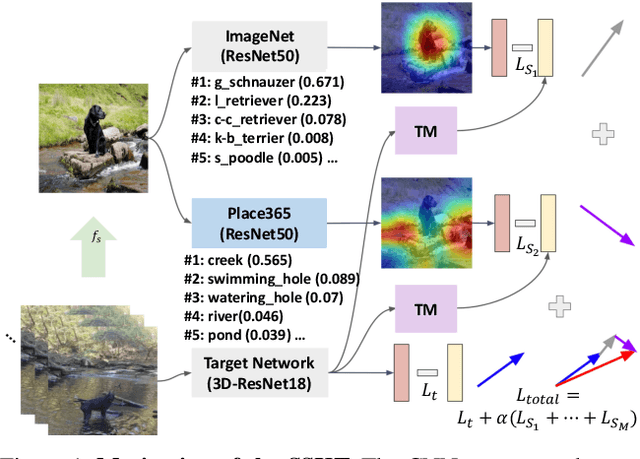
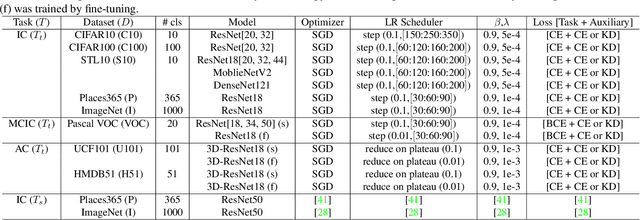
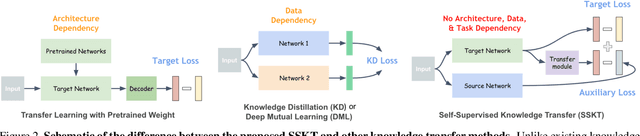
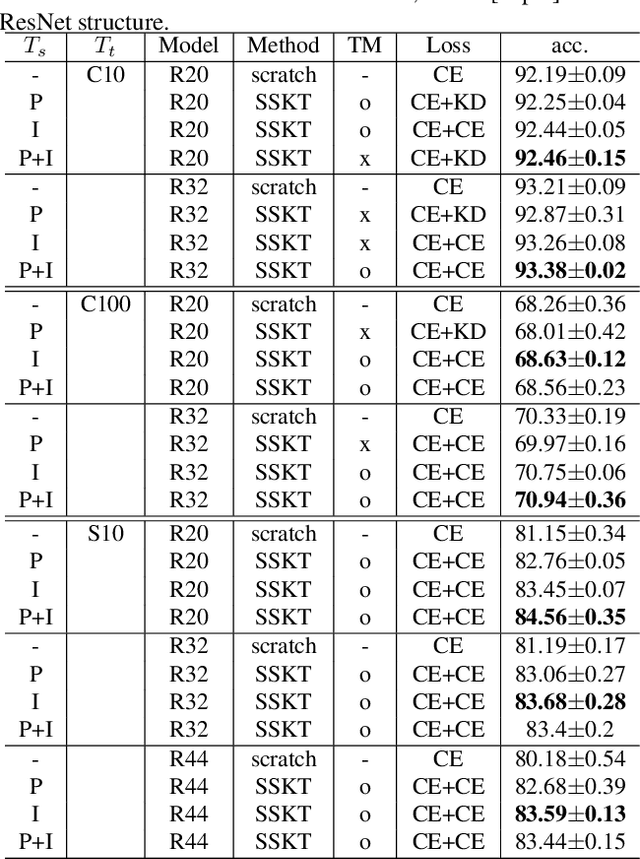
Knowledge transfer using convolutional neural networks (CNNs) can help efficiently train a CNN with fewer parameters or maximize the generalization performance under limited supervision. To enable a more efficient transfer of pretrained knowledge under relaxed conditions, we propose a simple yet powerful knowledge transfer methodology without any restrictions regarding the network structure or dataset used, namely self-supervised knowledge transfer (SSKT), via loosely supervised auxiliary tasks. For this, we devise a training methodology that transfers previously learned knowledge to the current training process as an auxiliary task for the target task through self-supervision using a soft label. The SSKT is independent of the network structure and dataset, and is trained differently from existing knowledge transfer methods; hence, it has an advantage in that the prior knowledge acquired from various tasks can be naturally transferred during the training process to the target task. Furthermore, it can improve the generalization performance on most datasets through the proposed knowledge transfer between different problem domains from multiple source networks. SSKT outperforms the other transfer learning methods (KD, DML, and MAXL) through experiments under various knowledge transfer settings. The source code will be made available to the public.
Rethinking Generalization Performance of Surgical Phase Recognition with Expert-Generated Annotations
Oct 22, 2021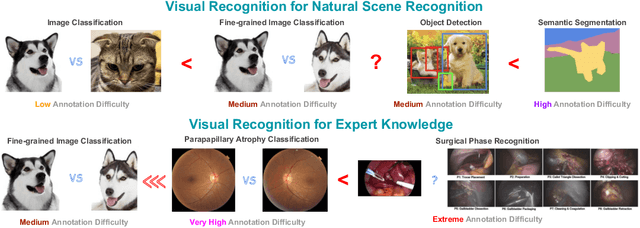

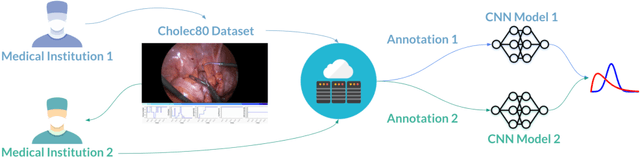
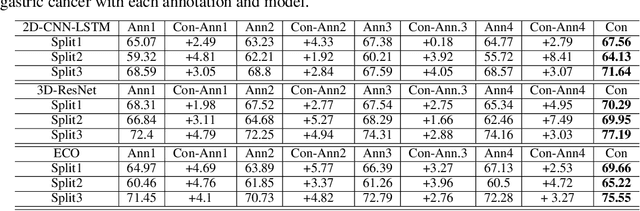
As the area of application of deep neural networks expands to areas requiring expertise, e.g., in medicine and law, more exquisite annotation processes for expert knowledge training are required. In particular, it is difficult to guarantee generalization performance in the clinical field in the case of expert knowledge training where opinions may differ even among experts on annotations. To raise the issue of the annotation generation process for expertise training of CNNs, we verified the annotations for surgical phase recognition of laparoscopic cholecystectomy and subtotal gastrectomy for gastric cancer. We produce calibrated annotations for the seven phases of cholecystectomy by analyzing the discrepancies of previously annotated labels and by discussing the criteria of surgical phases. For gastrectomy for gastric cancer has more complex twenty-one surgical phases, we generate consensus annotation by the revision process with five specialists. By training the CNN-based surgical phase recognition networks with revised annotations, we achieved improved generalization performance over models trained with original annotation under the same cross-validation settings. We showed that the expertise data annotation pipeline for deep neural networks should be more rigorous based on the type of problem to apply clinical field.
Deep Active Learning with Augmentation-based Consistency Estimation
Nov 05, 2020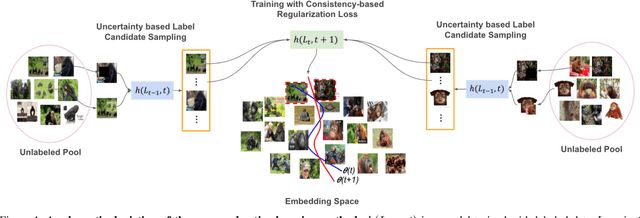
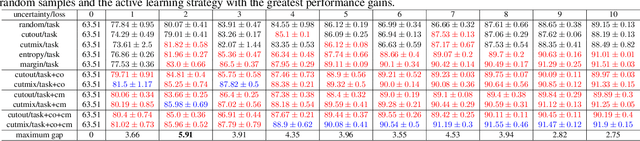
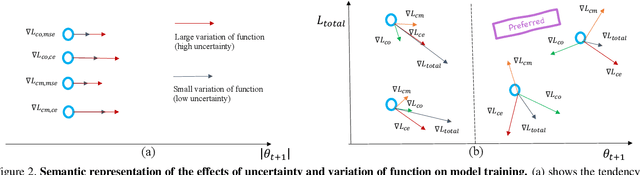

In active learning, the focus is mainly on the selection strategy of unlabeled data for enhancing the generalization capability of the next learning cycle. For this, various uncertainty measurement methods have been proposed. On the other hand, with the advent of data augmentation metrics as the regularizer on general deep learning, we notice that there can be a mutual influence between the method of unlabeled data selection and the data augmentation-based regularization techniques in active learning scenarios. Through various experiments, we confirmed that consistency-based regularization from analytical learning theory could affect the generalization capability of the classifier in combination with the existing uncertainty measurement method. By this fact, we propose a methodology to improve generalization ability, by applying data augmentation-based techniques to an active learning scenario. For the data augmentation-based regularization loss, we redefined cutout (co) and cutmix (cm) strategies as quantitative metrics and applied at both model training and unlabeled data selection steps. We have shown that the augmentation-based regularizer can lead to improved performance on the training step of active learning, while that same approach can be effectively combined with the uncertainty measurement metrics proposed so far. We used datasets such as FashionMNIST, CIFAR10, CIFAR100, and STL10 to verify the performance of the proposed active learning technique for multiple image classification tasks. Our experiments show consistent performance gains for each dataset and budget scenario.
Semi-Supervised Object Detection with Sparsely Annotated Dataset
Jun 21, 2020
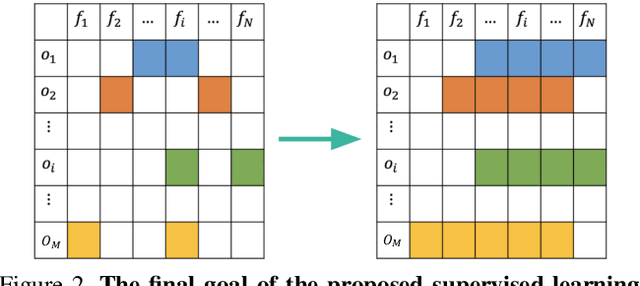
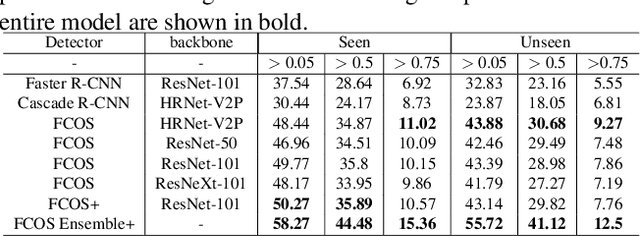
In training object detector based on convolutional neural networks, selection of effective positive examples for training is an important factor. However, when training an anchor-based detectors with sparse annotations on an image, effort to find effective positive examples can hinder training performance. When using the anchor-based training for the ground truth bounding box to collect positive examples under given IoU, it is often possible to include objects from other classes in the current training class, or objects that are needed to be trained can only be sampled as negative examples. We used two approaches to solve this problem: 1) the use of an anchorless object detector and 2) a semi-supervised learning-based object detection using a single object tracker. The proposed technique performs single object tracking by using the sparsely annotated bounding box as an anchor in the temporal domain for successive frames. From the tracking results, dense annotations for training images were generated in an automated manner and used for training the object detector. We applied the proposed single object tracking-based semi-supervised learning to the Epic-Kitchens dataset. As a result, we were able to achieve \textbf{runner-up} performance in the Unseen section while achieving the first place in the Seen section of the Epic-Kitchens 2020 object detection challenge under IoU > 0.5 evaluation
Fast and Accurate Convolutional Object Detectors for Real-time Embedded Platforms
Sep 24, 2019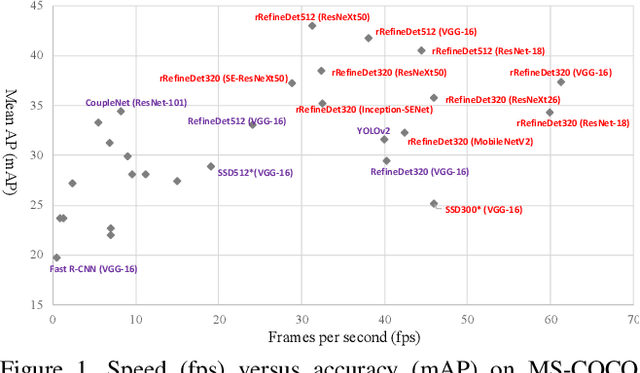
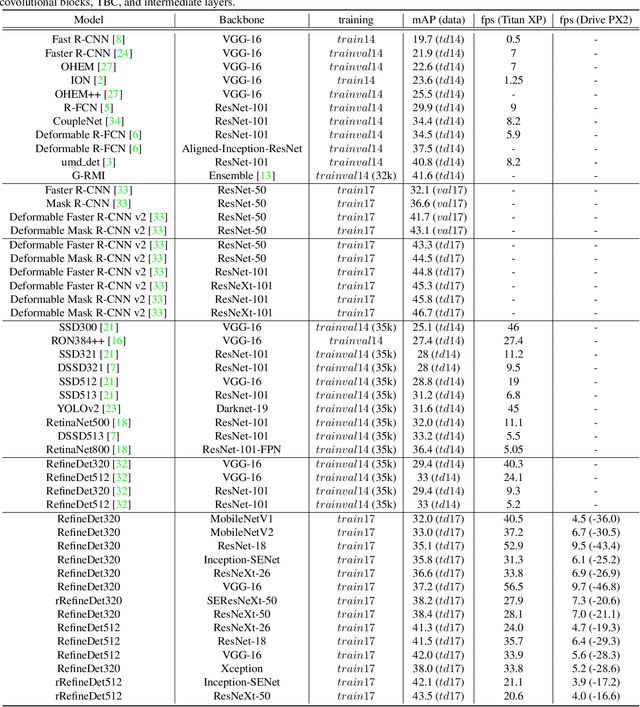
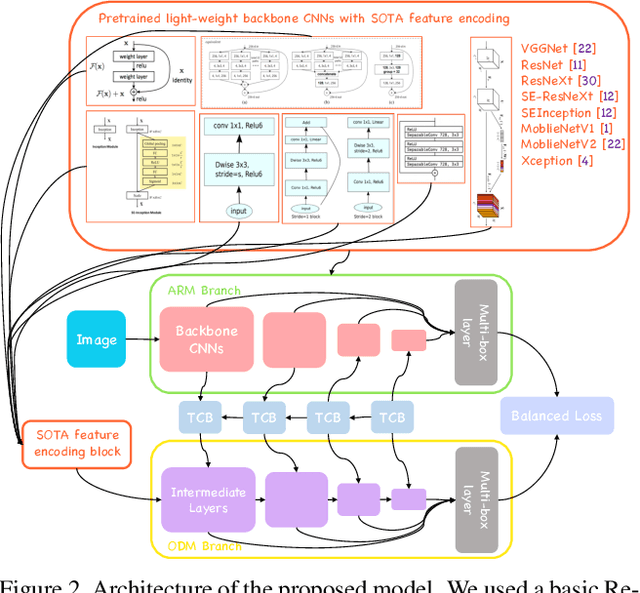
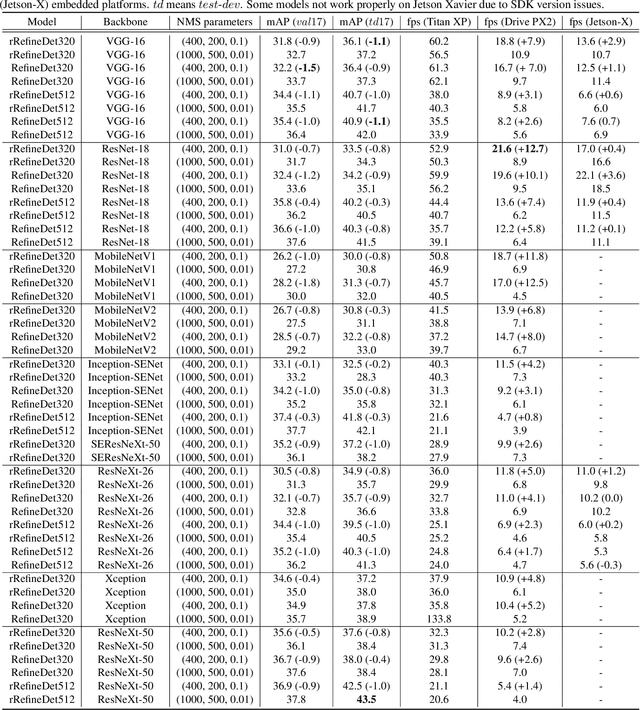
With the improvements in the object detection networks, several variations of object detection networks have been achieved impressive performance. However, the performance evaluation of most models has focused on detection accuracy, and the performance verification is mostly based on high-end GPU hardwares. In this paper, we propose real-time object detectors that guarantees balanced performance for real-time system on embedded platforms. The proposed model utilizes the basic head structure of the RefineDet model, which is a variant of the single shot object detector (SSD). In order to ensure real-time performance, CNN models with relatively shallow layers or fewer parameters have been used as the backbone structure. In addition to the basic VGGNet and ResNet structures, various backbone structures such as MobileNet, Xception, ResNeXt, Inception-SENet, and SE-ResNeXt have been used for this purpose. Successful training of object detection networks was achieved through an appropriate combination of intermediate layers. The accuracy of the proposed detector was estimated by the evaluation of MS-COCO 2017 object detection dataset and the inference speed on the NVIDIA Drive PX2 and Jetson Xaviers boards were tested to verify real-time performance in the embedded systems. The experiments show that the proposed models ensure balanced performance in terms of accuracy and inference speed in the embedded system environments. In addition, unlike the high-end GPUs, the use of embedded GPUs involves several additional concerns for efficient inference, which have been identified in this work. The codes and models are publicly available on the web (link).