 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistorting Embedding Space for Safety: A Defense Mechanism for Adversarially Robust Diffusion Models
Jan 31, 2025



Text-to-image diffusion models show remarkable generation performance following text prompts, but risk generating Not Safe For Work (NSFW) contents from unsafe prompts. Existing approaches, such as prompt filtering or concept unlearning, fail to defend against adversarial attacks while maintaining benign image quality. In this paper, we propose a novel approach called Distorting Embedding Space (DES), a text encoder-based defense mechanism that effectively tackles these issues through innovative embedding space control. DES transforms unsafe embeddings, extracted from a text encoder using unsafe prompts, toward carefully calculated safe embedding regions to prevent unsafe contents generation, while reproducing the original safe embeddings. DES also neutralizes the nudity embedding, extracted using prompt ``nudity", by aligning it with neutral embedding to enhance robustness against adversarial attacks. These methods ensure both robust defense and high-quality image generation. Additionally, DES can be adopted in a plug-and-play manner and requires zero inference overhead, facilitating its deployment. Extensive experiments on diverse attack types, including black-box and white-box scenarios, demonstrate DES's state-of-the-art performance in both defense capability and benign image generation quality. Our model is available at https://github.com/aei13/DES.
Semantic Map Guided Synthesis of Wireless Capsule Endoscopy Images using Diffusion Models
Nov 10, 2023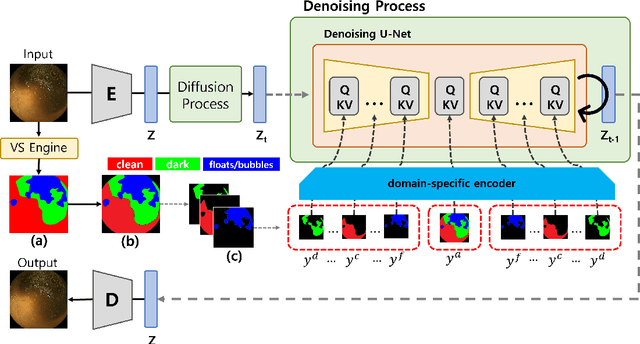
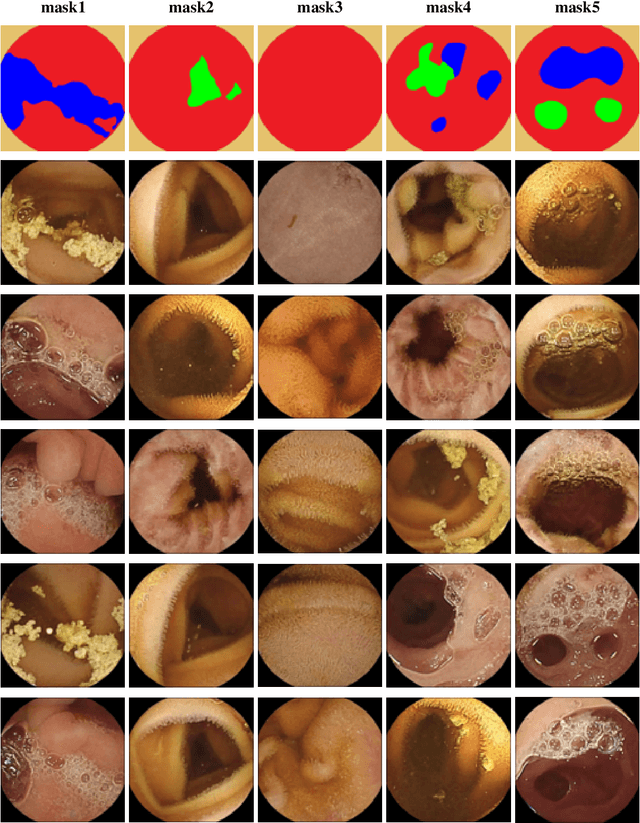
Wireless capsule endoscopy (WCE) is a non-invasive method for visualizing the gastrointestinal (GI) tract, crucial for diagnosing GI tract diseases. However, interpreting WCE results can be time-consuming and tiring. Existing studies have employed deep neural networks (DNNs) for automatic GI tract lesion detection, but acquiring sufficient training examples, particularly due to privacy concerns, remains a challenge. Public WCE databases lack diversity and quantity. To address this, we propose a novel approach leveraging generative models, specifically the diffusion model (DM), for generating diverse WCE images. Our model incorporates semantic map resulted from visualization scale (VS) engine, enhancing the controllability and diversity of generated images. We evaluate our approach using visual inspection and visual Turing tests, demonstrating its effectiveness in generating realistic and diverse WCE images.
Rewarded meta-pruning: Meta Learning with Rewards for Channel Pruning
Jan 26, 2023Convolutional Neural Networks (CNNs) have a large number of parameters and take significantly large hardware resources to compute, so edge devices struggle to run high-level networks. This paper proposes a novel method to reduce the parameters and FLOPs for computational efficiency in deep learning models. We introduce accuracy and efficiency coefficients to control the trade-off between the accuracy of the network and its computing efficiency. The proposed Rewarded meta-pruning algorithm trains a network to generate weights for a pruned model chosen based on the approximate parameters of the final model by controlling the interactions using a reward function. The reward function allows more control over the metrics of the final pruned model. Extensive experiments demonstrate superior performances of the proposed method over the state-of-the-art methods in pruning ResNet-50, MobileNetV1, and MobileNetV2 networks.
Fair Comparison between Efficient Attentions
Jun 01, 2022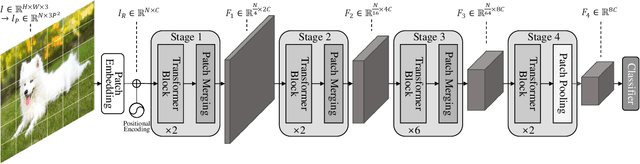

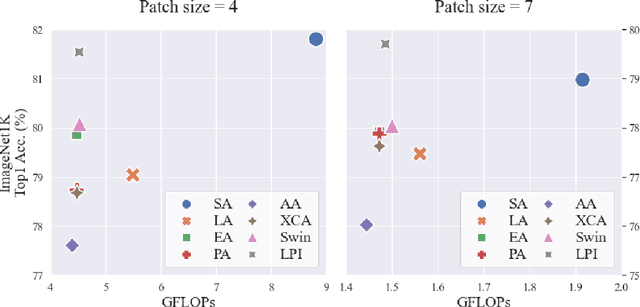

Transformers have been successfully used in various fields and are becoming the standard tools in computer vision. However, self-attention, a core component of transformers, has a quadratic complexity problem, which limits the use of transformers in various vision tasks that require dense prediction. Many studies aiming at solving this problem have been reported proposed. However, no comparative study of these methods using the same scale has been reported due to different model configurations, training schemes, and new methods. In our paper, we validate these efficient attention models on the ImageNet1K classification task by changing only the attention operation and examining which efficient attention is better.
Rethinking Query, Key, and Value Embedding in Vision Transformer under Tiny Model Constraints
Nov 19, 2021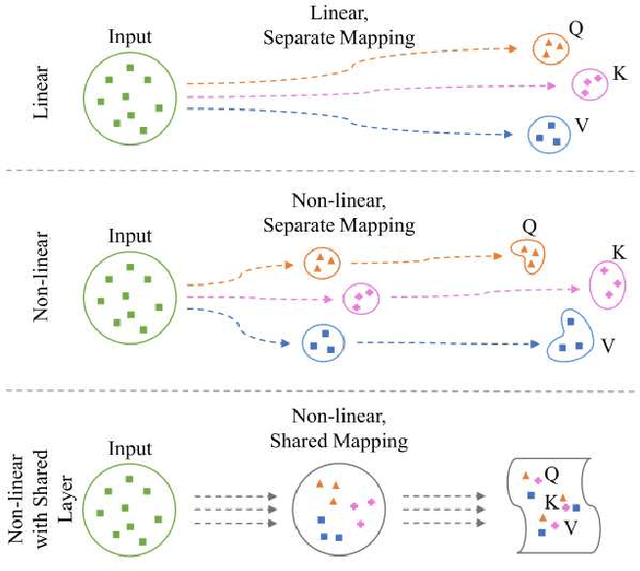
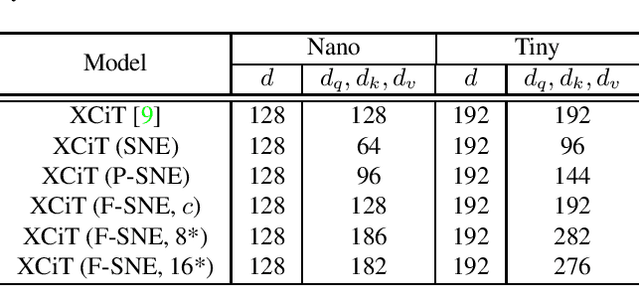
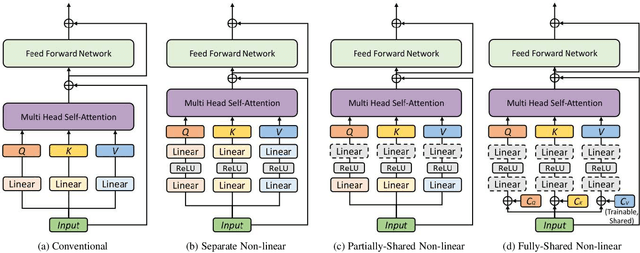
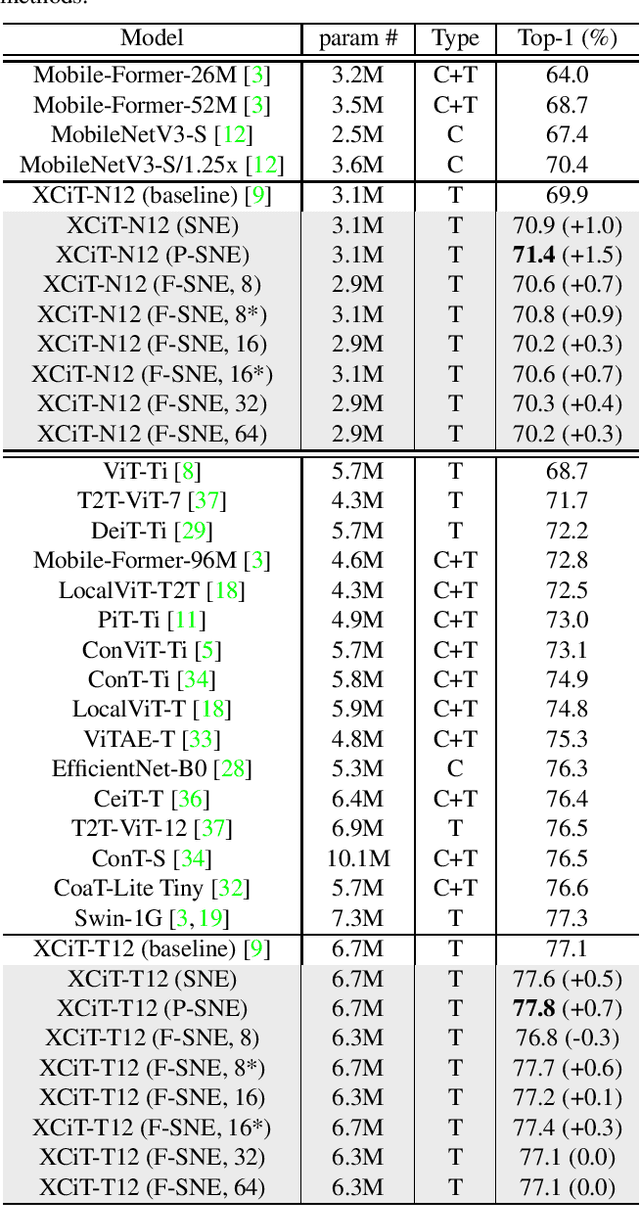
A vision transformer (ViT) is the dominant model in the computer vision field. Despite numerous studies that mainly focus on dealing with inductive bias and complexity, there remains the problem of finding better transformer networks. For example, conventional transformer-based models usually use a projection layer for each query (Q), key (K), and value (V) embedding before multi-head self-attention. Insufficient consideration of semantic $Q, K$, and $V$ embedding may lead to a performance drop. In this paper, we propose three types of structures for $Q$, $K$, and $V$ embedding. The first structure utilizes two layers with ReLU, which is a non-linear embedding for $Q, K$, and $V$. The second involves sharing one of the non-linear layers to share knowledge among $Q, K$, and $V$. The third proposed structure shares all non-linear layers with code parameters. The codes are trainable, and the values determine the embedding process to be performed among $Q$, $K$, and $V$. Hence, we demonstrate the superior image classification performance of the proposed approaches in experiments compared to several state-of-the-art approaches. The proposed method achieved $71.4\%$ with a few parameters (of $3.1M$) on the ImageNet-1k dataset compared to that required by the original transformer model of XCiT-N12 ($69.9\%$). Additionally, the method achieved $93.3\%$ with only $2.9M$ parameters in transfer learning on average for the CIFAR-10, CIFAR-100, Stanford Cars datasets, and STL-10 datasets, which is better than the accuracy of $92.2\%$ obtained via the original XCiT-N12 model.
Training Domain-invariant Object Detector Faster with Feature Replay and Slow Learner
May 31, 2021

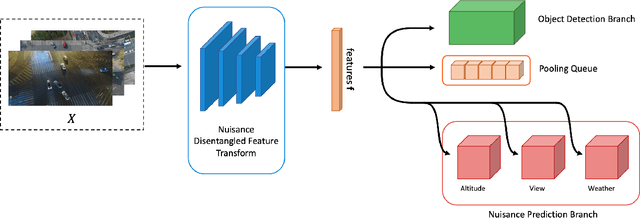

In deep learning-based object detection on remote sensing domain, nuisance factors, which affect observed variables while not affecting predictor variables, often matters because they cause domain changes. Previously, nuisance disentangled feature transformation (NDFT) was proposed to build domain-invariant feature extractor with with knowledge of nuisance factors. However, NDFT requires enormous time in a training phase, so it has been impractical. In this paper, we introduce our proposed method, A-NDFT, which is an improvement to NDFT. A-NDFT utilizes two acceleration techniques, feature replay and slow learner. Consequently, on a large-scale UAVDT benchmark, it is shown that our framework can reduce the training time of NDFT from 31 hours to 3 hours while still maintaining the performance. The code will be made publicly available online.
Extending Contrastive Learning to Unsupervised Coreset Selection
Mar 05, 2021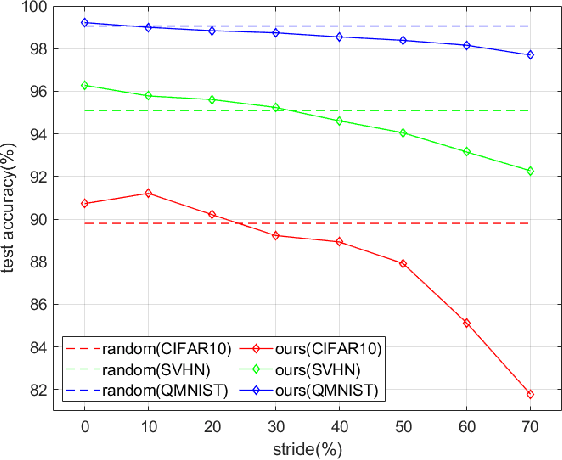
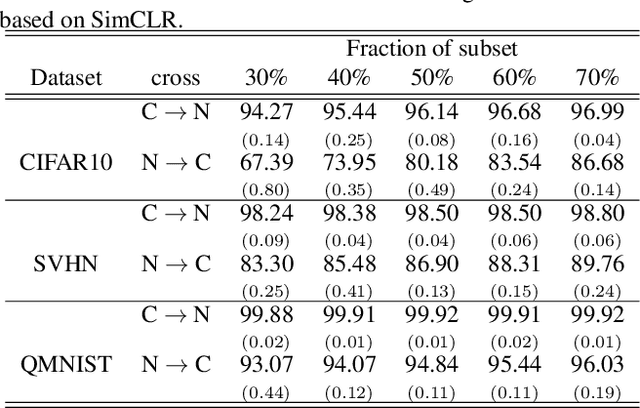
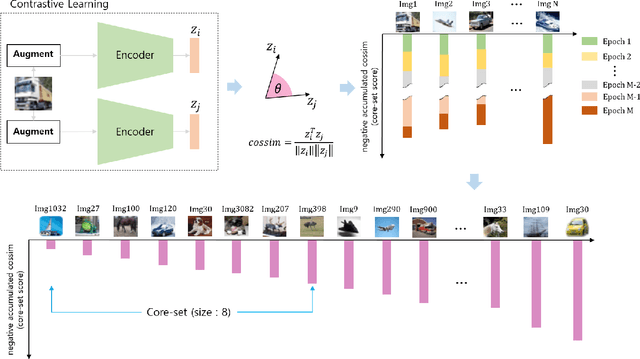
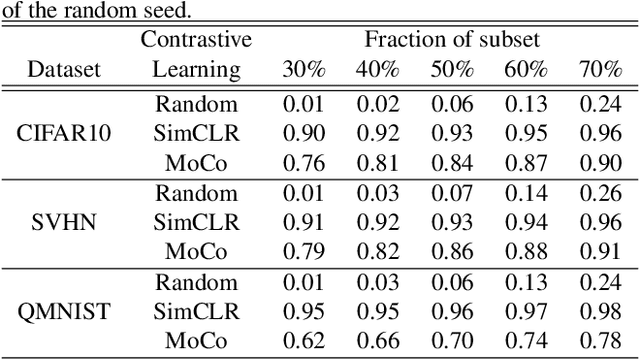
Self-supervised contrastive learning offers a means of learning informative features from a pool of unlabeled data. In this paper, we delve into another useful approach -- providing a way of selecting a core-set that is entirely unlabeled. In this regard, contrastive learning, one of a large number of self-supervised methods, was recently proposed and has consistently delivered the highest performance. This prompted us to choose two leading methods for contrastive learning: the simple framework for contrastive learning of visual representations (SimCLR) and the momentum contrastive (MoCo) learning framework. We calculated the cosine similarities for each example of an epoch for the entire duration of the contrastive learning process and subsequently accumulated the cosine-similarity values to obtain the coreset score. Our assumption was that an sample with low similarity would likely behave as a coreset. Compared with existing coreset selection methods with labels, our approach reduced the cost associated with human annotation. The unsupervised method implemented in this study for coreset selection obtained improved results over a randomly chosen subset, and were comparable to existing supervised coreset selection on various classification datasets (e.g., CIFAR, SVHN, and QMNIST).
FixBi: Bridging Domain Spaces for Unsupervised Domain Adaptation
Nov 18, 2020
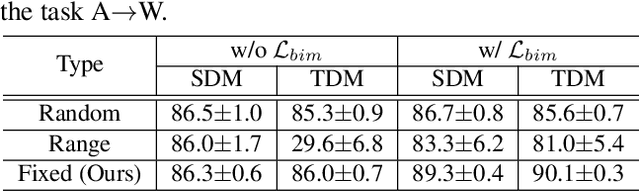
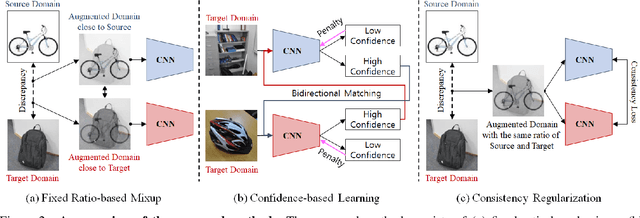

Unsupervised domain adaptation (UDA) methods for learning domain invariant representations have achieved remarkable progress. However, few studies have been conducted on the case of large domain discrepancies between a source and a target domain. In this paper, we propose a UDA method that effectively handles such large domain discrepancies. We introduce a fixed ratio-based mixup to augment multiple intermediate domains between the source and target domain. From the augmented-domains, we train the source-dominant model and the target-dominant model that have complementary characteristics. Using our confidence-based learning methodologies, e.g., bidirectional matching with high-confidence predictions and self-penalization using low-confidence predictions, the models can learn from each other or from its own results. Through our proposed methods, the models gradually transfer domain knowledge from the source to the target domain. Extensive experiments demonstrate the superiority of our proposed method on three public benchmarks: Office-31, Office-Home, and VisDA-2017.
Fast and Accurate Convolutional Object Detectors for Real-time Embedded Platforms
Sep 24, 2019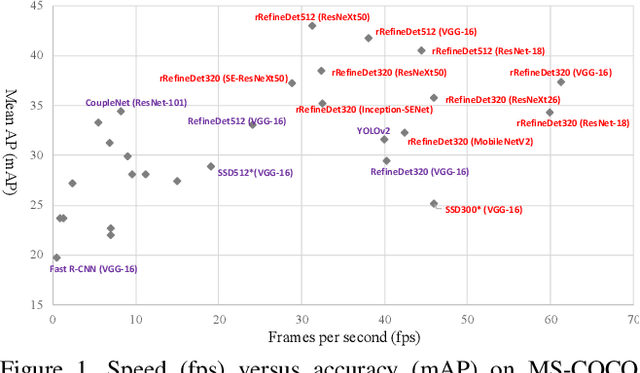
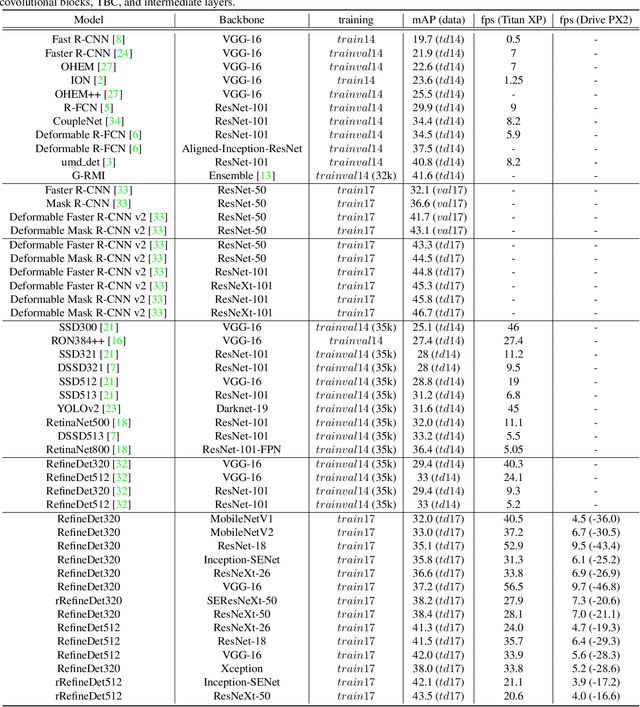
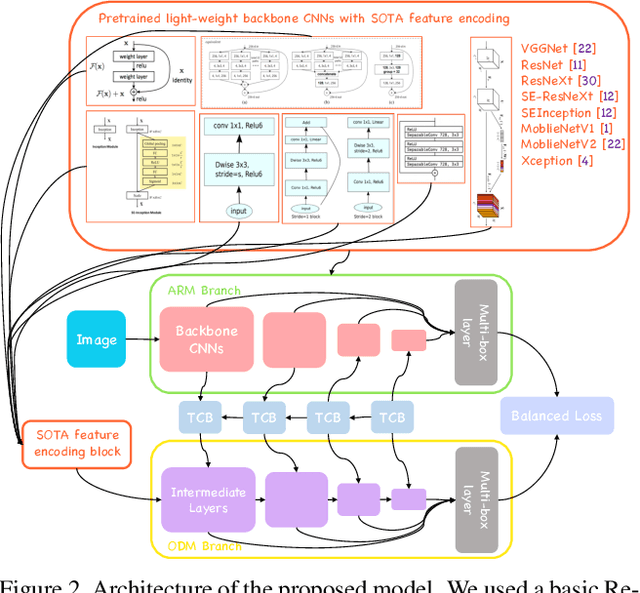
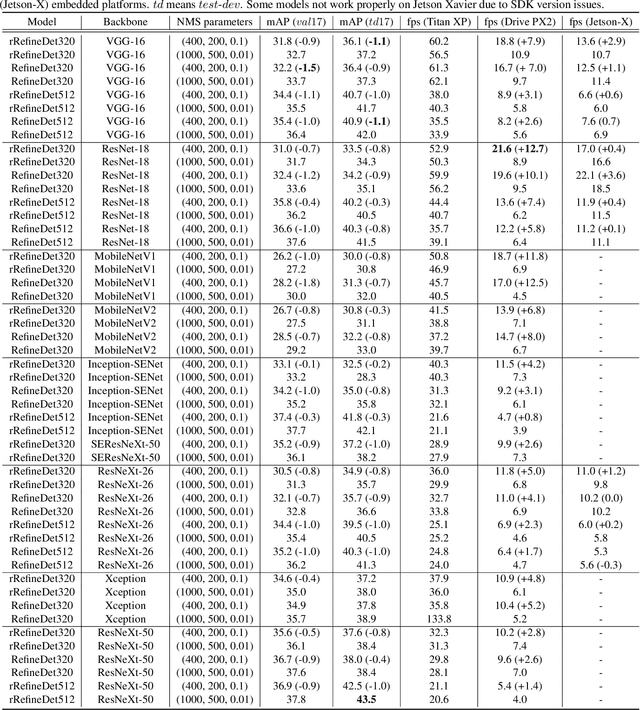
With the improvements in the object detection networks, several variations of object detection networks have been achieved impressive performance. However, the performance evaluation of most models has focused on detection accuracy, and the performance verification is mostly based on high-end GPU hardwares. In this paper, we propose real-time object detectors that guarantees balanced performance for real-time system on embedded platforms. The proposed model utilizes the basic head structure of the RefineDet model, which is a variant of the single shot object detector (SSD). In order to ensure real-time performance, CNN models with relatively shallow layers or fewer parameters have been used as the backbone structure. In addition to the basic VGGNet and ResNet structures, various backbone structures such as MobileNet, Xception, ResNeXt, Inception-SENet, and SE-ResNeXt have been used for this purpose. Successful training of object detection networks was achieved through an appropriate combination of intermediate layers. The accuracy of the proposed detector was estimated by the evaluation of MS-COCO 2017 object detection dataset and the inference speed on the NVIDIA Drive PX2 and Jetson Xaviers boards were tested to verify real-time performance in the embedded systems. The experiments show that the proposed models ensure balanced performance in terms of accuracy and inference speed in the embedded system environments. In addition, unlike the high-end GPUs, the use of embedded GPUs involves several additional concerns for efficient inference, which have been identified in this work. The codes and models are publicly available on the web (link).
Co-occurrence matrix analysis-based semi-supervised training for object detection
Feb 20, 2018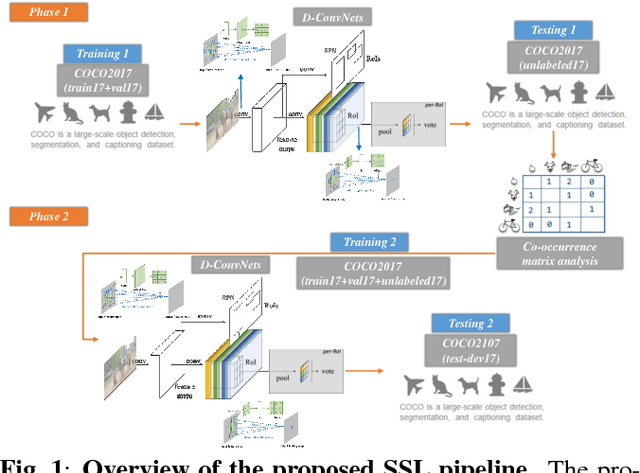
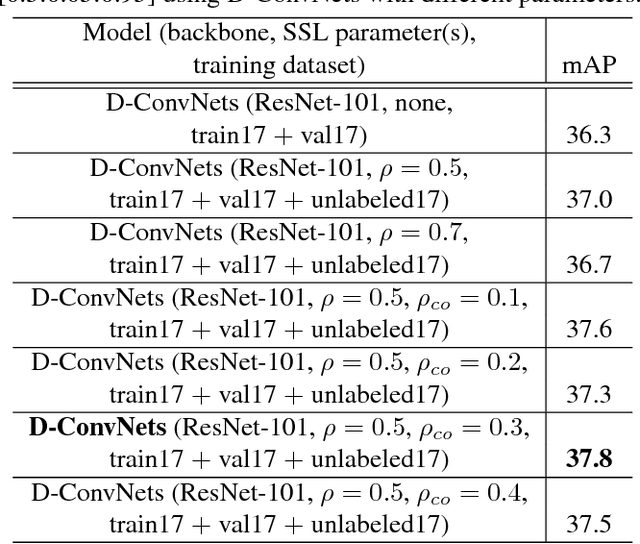

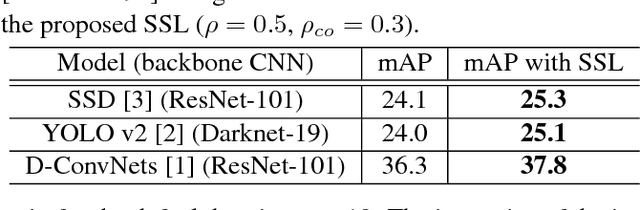
One of the most important factors in training object recognition networks using convolutional neural networks (CNNs) is the provision of annotated data accompanying human judgment. Particularly, in object detection or semantic segmentation, the annotation process requires considerable human effort. In this paper, we propose a semi-supervised learning (SSL)-based training methodology for object detection, which makes use of automatic labeling of un-annotated data by applying a network previously trained from an annotated dataset. Because an inferred label by the trained network is dependent on the learned parameters, it is often meaningless for re-training the network. To transfer a valuable inferred label to the unlabeled data, we propose a re-alignment method based on co-occurrence matrix analysis that takes into account one-hot-vector encoding of the estimated label and the correlation between the objects in the image. We used an MS-COCO detection dataset to verify the performance of the proposed SSL method and deformable neural networks (D-ConvNets) as an object detector for basic training. The performance of the existing state-of-the-art detectors (DConvNets, YOLO v2, and single shot multi-box detector (SSD)) can be improved by the proposed SSL method without using the additional model parameter or modifying the network architecture.