 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Clustering Representations with Positive Proximity and Cluster Dispersion Learning
Nov 01, 2023Contemporary deep clustering approaches often rely on either contrastive or non-contrastive techniques to acquire effective representations for clustering tasks. Contrastive methods leverage negative pairs to achieve homogenous representations but can introduce class collision issues, potentially compromising clustering performance. On the contrary, non-contrastive techniques prevent class collisions but may produce non-uniform representations that lead to clustering collapse. In this work, we propose a novel end-to-end deep clustering approach named PIPCDR, designed to harness the strengths of both approaches while mitigating their limitations. PIPCDR incorporates a positive instance proximity loss and a cluster dispersion regularizer. The positive instance proximity loss ensures alignment between augmented views of instances and their sampled neighbors, enhancing within-cluster compactness by selecting genuinely positive pairs within the embedding space. Meanwhile, the cluster dispersion regularizer maximizes inter-cluster distances while minimizing within-cluster compactness, promoting uniformity in the learned representations. PIPCDR excels in producing well-separated clusters, generating uniform representations, avoiding class collision issues, and enhancing within-cluster compactness. We extensively validate the effectiveness of PIPCDR within an end-to-end Majorize-Minimization framework, demonstrating its competitive performance on moderate-scale clustering benchmark datasets and establishing new state-of-the-art results on large-scale datasets.
Robust Unsupervised Domain Adaptation by Retaining Confident Entropy via Edge Concatenation
Oct 11, 2023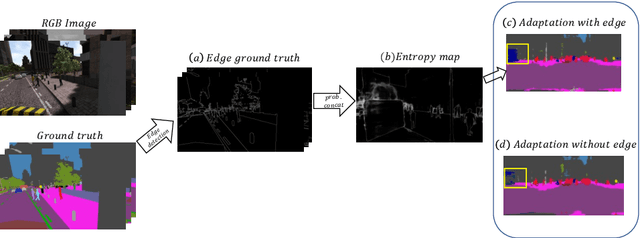
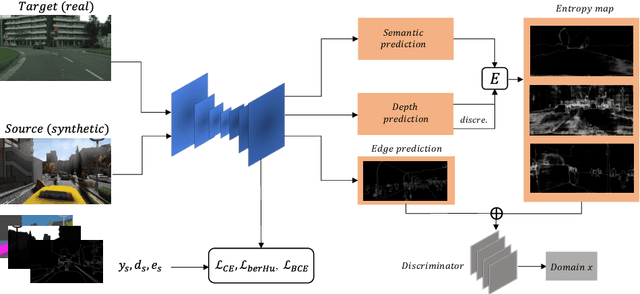
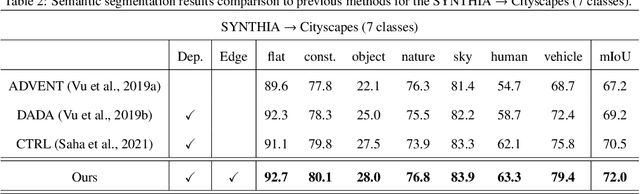

The generalization capability of unsupervised domain adaptation can mitigate the need for extensive pixel-level annotations to train semantic segmentation networks by training models on synthetic data as a source with computer-generated annotations. Entropy-based adversarial networks are proposed to improve source domain prediction; however, they disregard significant external information, such as edges, which have the potential to identify and distinguish various objects within an image accurately. To address this issue, we introduce a novel approach to domain adaptation, leveraging the synergy of internal and external information within entropy-based adversarial networks. In this approach, we enrich the discriminator network with edge-predicted probability values within this innovative framework to enhance the clarity of class boundaries. Furthermore, we devised a probability-sharing network that integrates diverse information for more effective segmentation. Incorporating object edges addresses a pivotal aspect of unsupervised domain adaptation that has frequently been neglected in the past -- the precise delineation of object boundaries. Conventional unsupervised domain adaptation methods usually center around aligning feature distributions and may not explicitly model object boundaries. Our approach effectively bridges this gap by offering clear guidance on object boundaries, thereby elevating the quality of domain adaptation. Our approach undergoes rigorous evaluation on the established unsupervised domain adaptation benchmarks, specifically in adapting SYNTHIA $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Mapillary. Experimental results show that the proposed model attains better performance than state-of-the-art methods. The superior performance across different unsupervised domain adaptation scenarios highlights the versatility and robustness of the proposed method.
UAVSNet: An Encoder-Decoder Architecture based UAV Image Segmentation Network
Feb 25, 2023Due to an increased application of Unmanned Aerial Vehicle (UAV) devices like drones, segmentation of aerial images for urban scene understanding has brought a new research opportunity. Aerial images own so much variability in scale, object appearance, and complex background. The task of semantic segmentation when capturing the underlying features in a global and local context for the UAV images becomes challenging. In this work, we proposed a UAV Segmentation Network (UAVSNet) for precise semantic segmentation of urban aerial scenes. It is a transformer-based encoder-decoder framework that uses multi-scale feature representations. The UAVSNet exploits the advantage of a self-attention-based transformer framework and convolution mechanisms in capturing the global and local context details. This helps the network precisely capture the inherent feature of the aerial images and generate overall semantically rich feature representation. The proposed Overlap Token Embedding (OTE) module generates multi-scale features. A decoder network is proposed, which further processes these features using a multi-scale feature fusion policy to enhance the feature representation ability of the network. We show the effectiveness of the proposed network on UAVid and Urban drone datasets by achieving mIoU of 64.35% and 74.64%, respectively.
Rewarded meta-pruning: Meta Learning with Rewards for Channel Pruning
Jan 26, 2023Convolutional Neural Networks (CNNs) have a large number of parameters and take significantly large hardware resources to compute, so edge devices struggle to run high-level networks. This paper proposes a novel method to reduce the parameters and FLOPs for computational efficiency in deep learning models. We introduce accuracy and efficiency coefficients to control the trade-off between the accuracy of the network and its computing efficiency. The proposed Rewarded meta-pruning algorithm trains a network to generate weights for a pruned model chosen based on the approximate parameters of the final model by controlling the interactions using a reward function. The reward function allows more control over the metrics of the final pruned model. Extensive experiments demonstrate superior performances of the proposed method over the state-of-the-art methods in pruning ResNet-50, MobileNetV1, and MobileNetV2 networks.
Visual Question Answering based on Local-Scene-Aware Referring Expression Generation
Jan 22, 2021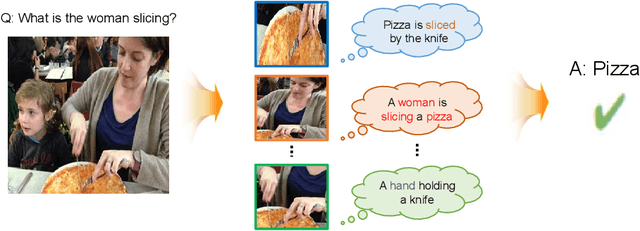
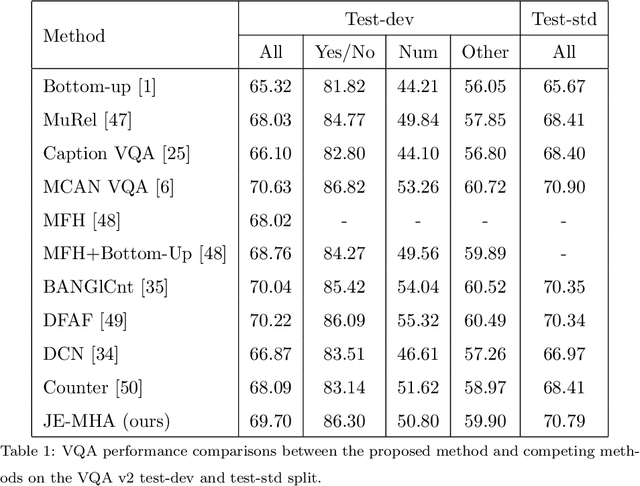
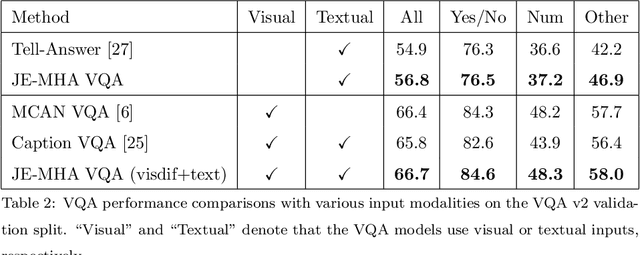
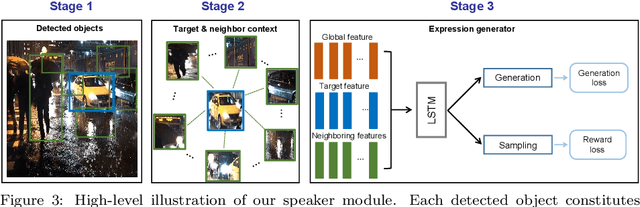
Visual question answering requires a deep understanding of both images and natural language. However, most methods mainly focus on visual concept; such as the relationships between various objects. The limited use of object categories combined with their relationships or simple question embedding is insufficient for representing complex scenes and explaining decisions. To address this limitation, we propose the use of text expressions generated for images, because such expressions have few structural constraints and can provide richer descriptions of images. The generated expressions can be incorporated with visual features and question embedding to obtain the question-relevant answer. A joint-embedding multi-head attention network is also proposed to model three different information modalities with co-attention. We quantitatively and qualitatively evaluated the proposed method on the VQA v2 dataset and compared it with state-of-the-art methods in terms of answer prediction. The quality of the generated expressions was also evaluated on the RefCOCO, RefCOCO+, and RefCOCOg datasets. Experimental results demonstrate the effectiveness of the proposed method and reveal that it outperformed all of the competing methods in terms of both quantitative and qualitative results.
Human Interaction Recognition Framework based on Interacting Body Part Attention
Jan 22, 2021
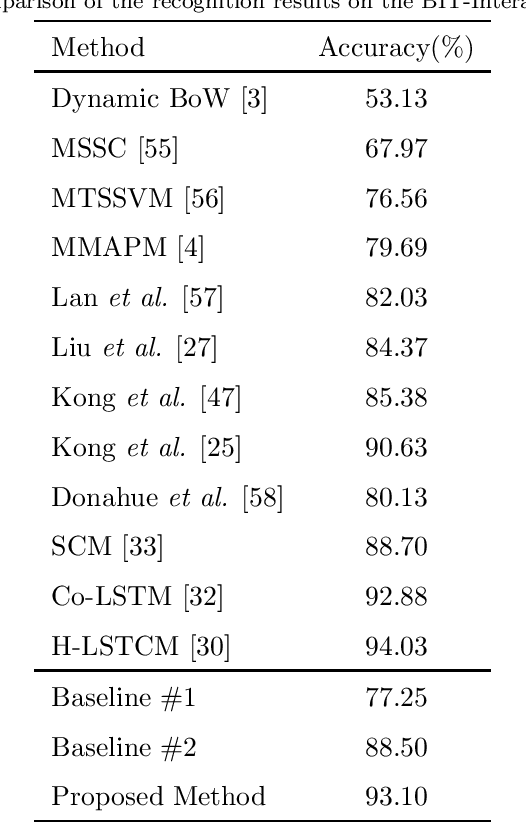
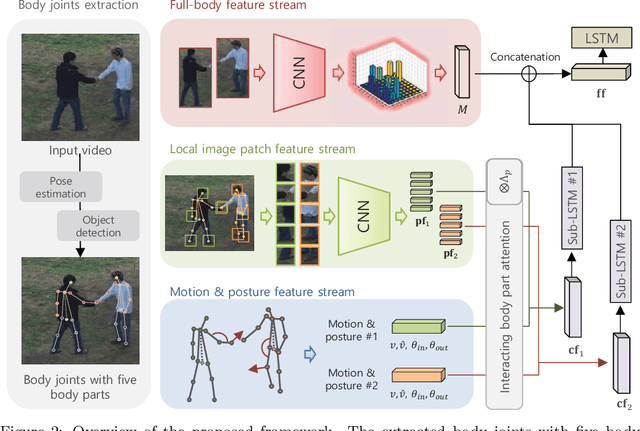

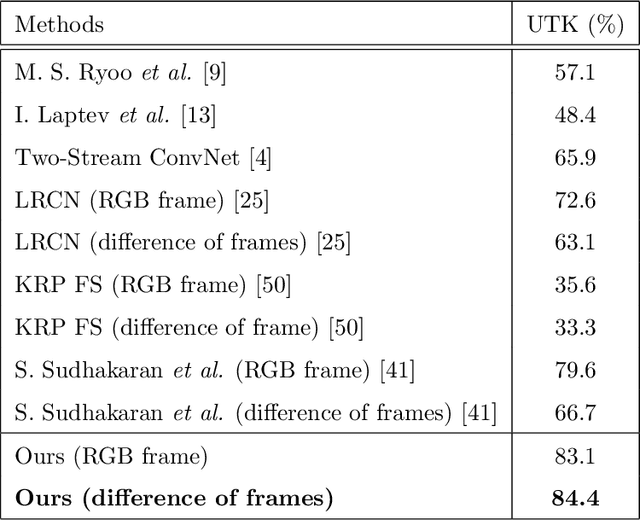
Human activity recognition in videos has been widely studied and has recently gained significant advances with deep learning approaches; however, it remains a challenging task. In this paper, we propose a novel framework that simultaneously considers both implicit and explicit representations of human interactions by fusing information of local image where the interaction actively occurred, primitive motion with the posture of individual subject's body parts, and the co-occurrence of overall appearance change. Human interactions change, depending on how the body parts of each human interact with the other. The proposed method captures the subtle difference between different interactions using interacting body part attention. Semantically important body parts that interact with other objects are given more weight during feature representation. The combined feature of interacting body part attention-based individual representation and the co-occurrence descriptor of the full-body appearance change is fed into long short-term memory to model the temporal dynamics over time in a single framework. We validate the effectiveness of the proposed method using four widely used public datasets by outperforming the competing state-of-the-art method.
Three-Stream Fusion Network for First-Person Interaction Recognition
Feb 19, 2020
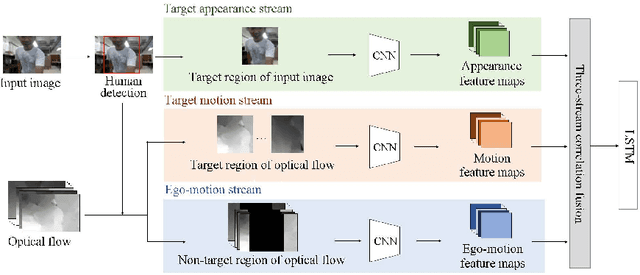
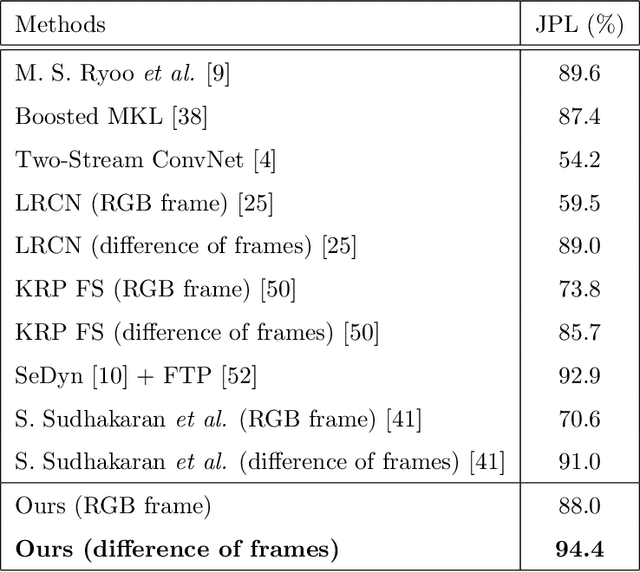
First-person interaction recognition is a challenging task because of unstable video conditions resulting from the camera wearer's movement. For human interaction recognition from a first-person viewpoint, this paper proposes a three-stream fusion network with two main parts: three-stream architecture and three-stream correlation fusion. Thre three-stream architecture captures the characteristics of the target appearance, target motion, and camera ego-motion. Meanwhile the three-stream correlation fusion combines the feature map of each of the three streams to consider the correlations among the target appearance, target motion and camera ego-motion. The fused feature vector is robust to the camera movement and compensates for the noise of the camera ego-motion. Short-term intervals are modeled using the fused feature vector, and a long short-term memory(LSTM) model considers the temporal dynamics of the video. We evaluated the proposed method on two-public benchmark datasets to validate the effectiveness of our approach. The experimental results show that the proposed fusion method successfully generated a discriminative feature vector, and our network outperformed all competing activity recognition methods in first-person videos where considerable camera ego-motion occurs.