 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Interaction Recognition Framework based on Interacting Body Part Attention
Paper and Code
Jan 22, 2021
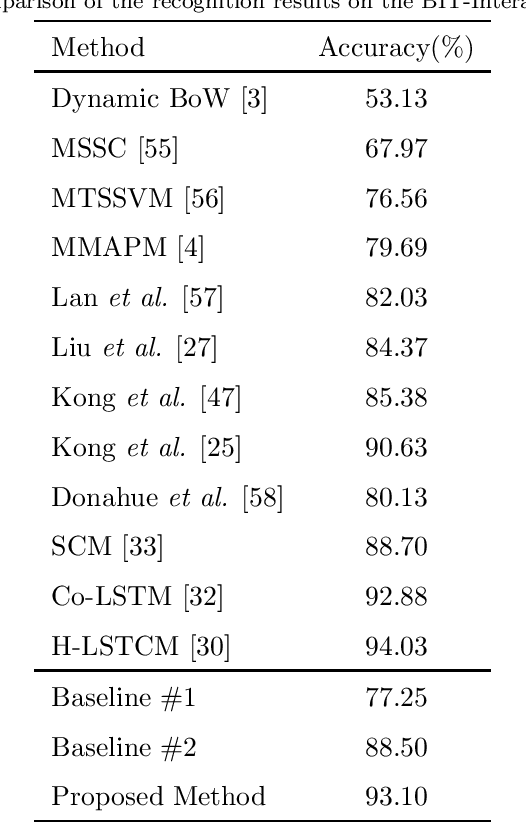
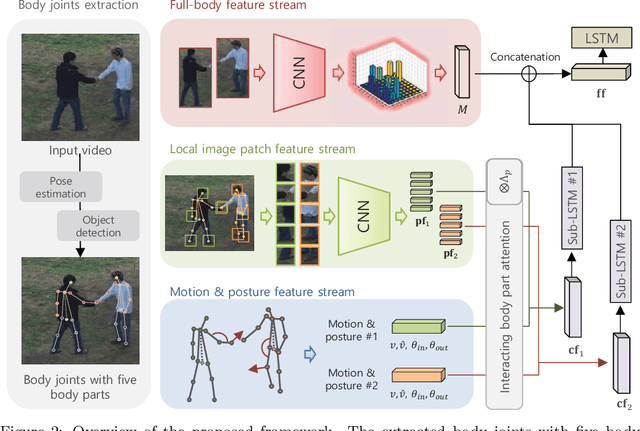

Human activity recognition in videos has been widely studied and has recently gained significant advances with deep learning approaches; however, it remains a challenging task. In this paper, we propose a novel framework that simultaneously considers both implicit and explicit representations of human interactions by fusing information of local image where the interaction actively occurred, primitive motion with the posture of individual subject's body parts, and the co-occurrence of overall appearance change. Human interactions change, depending on how the body parts of each human interact with the other. The proposed method captures the subtle difference between different interactions using interacting body part attention. Semantically important body parts that interact with other objects are given more weight during feature representation. The combined feature of interacting body part attention-based individual representation and the co-occurrence descriptor of the full-body appearance change is fed into long short-term memory to model the temporal dynamics over time in a single framework. We validate the effectiveness of the proposed method using four widely used public datasets by outperforming the competing state-of-the-art method.