 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight Alignment Improves LLM Safety via Model Self-Reflection with a Single Neuron
Feb 02, 2026The safety of large language models (LLMs) has increasingly emerged as a fundamental aspect of their development. Existing safety alignment for LLMs is predominantly achieved through post-training methods, which are computationally expensive and often fail to generalize well across different models. A small number of lightweight alignment approaches either rely heavily on prior-computed safety injections or depend excessively on the model's own capabilities, resulting in limited generalization and degraded efficiency and usability during generation. In this work, we propose a safety-aware decoding method that requires only low-cost training of an expert model and employs a single neuron as a gating mechanism. By effectively balancing the model's intrinsic capabilities with external guidance, our approach simultaneously preserves utility and enhances output safety. It demonstrates clear advantages in training overhead and generalization across model scales, offering a new perspective on lightweight alignment for the safe and practical deployment of large language models. Code: https://github.com/Beijing-AISI/NGSD.
From Parameter to Representation: A Closed-Form Approach for Controllable Model Merging
Nov 14, 2025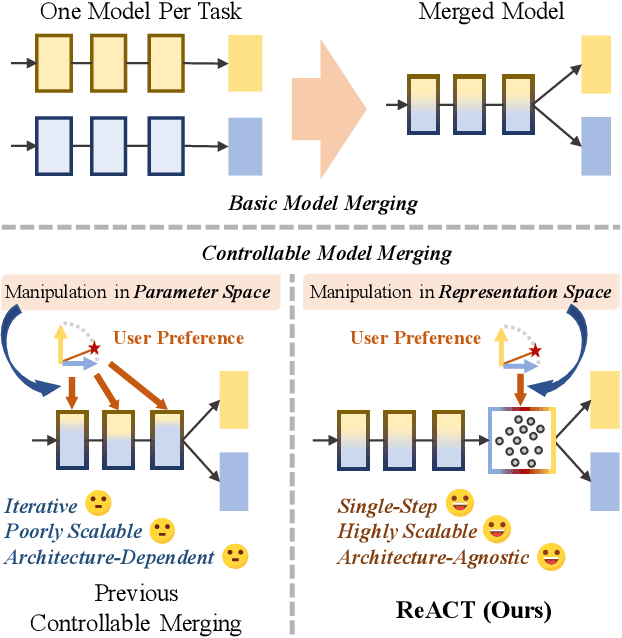
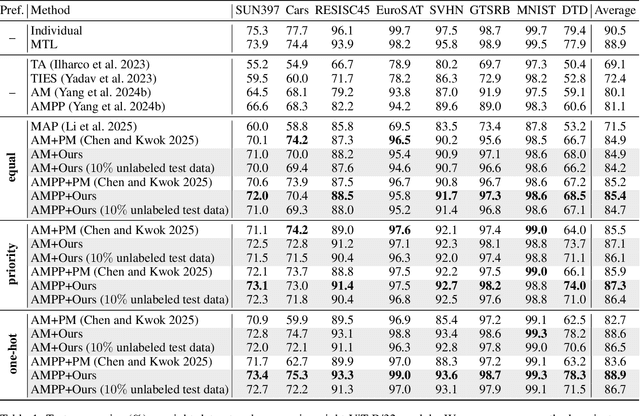
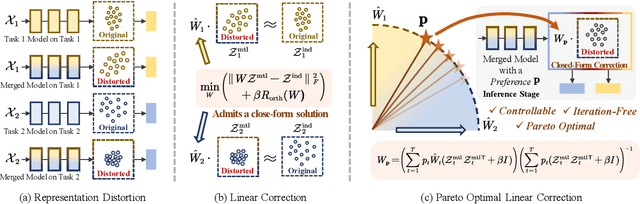
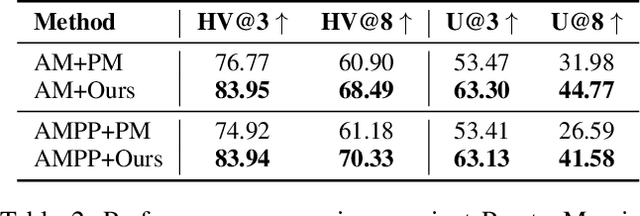
Model merging combines expert models for multitask performance but faces challenges from parameter interference. This has sparked recent interest in controllable model merging, giving users the ability to explicitly balance performance trade-offs. Existing approaches employ a compile-then-query paradigm, performing a costly offline multi-objective optimization to enable fast, preference-aware model generation. This offline stage typically involves iterative search or dedicated training, with complexity that grows exponentially with the number of tasks. To overcome these limitations, we shift the perspective from parameter-space optimization to a direct correction of the model's final representation. Our approach models this correction as an optimal linear transformation, yielding a closed-form solution that replaces the entire offline optimization process with a single-step, architecture-agnostic computation. This solution directly incorporates user preferences, allowing a Pareto-optimal model to be generated on-the-fly with complexity that scales linearly with the number of tasks. Experimental results show our method generates a superior Pareto front with more precise preference alignment and drastically reduced computational cost.
EnchTable: Unified Safety Alignment Transfer in Fine-tuned Large Language Models
Nov 13, 2025Many machine learning models are fine-tuned from large language models (LLMs) to achieve high performance in specialized domains like code generation, biomedical analysis, and mathematical problem solving. However, this fine-tuning process often introduces a critical vulnerability: the systematic degradation of safety alignment, undermining ethical guidelines and increasing the risk of harmful outputs. Addressing this challenge, we introduce EnchTable, a novel framework designed to transfer and maintain safety alignment in downstream LLMs without requiring extensive retraining. EnchTable leverages a Neural Tangent Kernel (NTK)-based safety vector distillation method to decouple safety constraints from task-specific reasoning, ensuring compatibility across diverse model architectures and sizes. Additionally, our interference-aware merging technique effectively balances safety and utility, minimizing performance compromises across various task domains. We implemented a fully functional prototype of EnchTable on three different task domains and three distinct LLM architectures, and evaluated its performance through extensive experiments on eleven diverse datasets, assessing both utility and model safety. Our evaluations include LLMs from different vendors, demonstrating EnchTable's generalization capability. Furthermore, EnchTable exhibits robust resistance to static and dynamic jailbreaking attacks, outperforming vendor-released safety models in mitigating adversarial prompts. Comparative analyses with six parameter modification methods and two inference-time alignment baselines reveal that EnchTable achieves a significantly lower unsafe rate, higher utility score, and universal applicability across different task domains. Additionally, we validate EnchTable can be seamlessly integrated into various deployment pipelines without significant overhead.
Measuring the Measures: Discriminative Capacity of Representational Similarity Metrics Across Model Families
Sep 04, 2025Representational similarity metrics are fundamental tools in neuroscience and AI, yet we lack systematic comparisons of their discriminative power across model families. We introduce a quantitative framework to evaluate representational similarity measures based on their ability to separate model families-across architectures (CNNs, Vision Transformers, Swin Transformers, ConvNeXt) and training regimes (supervised vs. self-supervised). Using three complementary separability measures-dprime from signal detection theory, silhouette coefficients and ROC-AUC, we systematically assess the discriminative capacity of commonly used metrics including RSA, linear predictivity, Procrustes, and soft matching. We show that separability systematically increases as metrics impose more stringent alignment constraints. Among mapping-based approaches, soft-matching achieves the highest separability, followed by Procrustes alignment and linear predictivity. Non-fitting methods such as RSA also yield strong separability across families. These results provide the first systematic comparison of similarity metrics through a separability lens, clarifying their relative sensitivity and guiding metric choice for large-scale model and brain comparisons.
Dual-Priv Pruning : Efficient Differential Private Fine-Tuning in Multimodal Large Language Models
Jun 08, 2025Differential Privacy (DP) is a widely adopted technique, valued for its effectiveness in protecting the privacy of task-specific datasets, making it a critical tool for large language models. However, its effectiveness in Multimodal Large Language Models (MLLMs) remains uncertain. Applying Differential Privacy (DP) inherently introduces substantial computation overhead, a concern particularly relevant for MLLMs which process extensive textual and visual data. Furthermore, a critical challenge of DP is that the injected noise, necessary for privacy, scales with parameter dimensionality, leading to pronounced model degradation; This trade-off between privacy and utility complicates the application of Differential Privacy (DP) to complex architectures like MLLMs. To address these, we propose Dual-Priv Pruning, a framework that employs two complementary pruning mechanisms for DP fine-tuning in MLLMs: (i) visual token pruning to reduce input dimensionality by removing redundant visual information, and (ii) gradient-update pruning during the DP optimization process. This second mechanism selectively prunes parameter updates based on the magnitude of noisy gradients, aiming to mitigate noise impact and improve utility. Experiments demonstrate that our approach achieves competitive results with minimal performance degradation. In terms of computational efficiency, our approach consistently utilizes less memory than standard DP-SGD. While requiring only 1.74% more memory than zeroth-order methods which suffer from severe performance issues on A100 GPUs, our method demonstrates leading memory efficiency on H20 GPUs. To the best of our knowledge, we are the first to explore DP fine-tuning in MLLMs. Our code is coming soon.
Protego: Detecting Adversarial Examples for Vision Transformers via Intrinsic Capabilities
Jan 13, 2025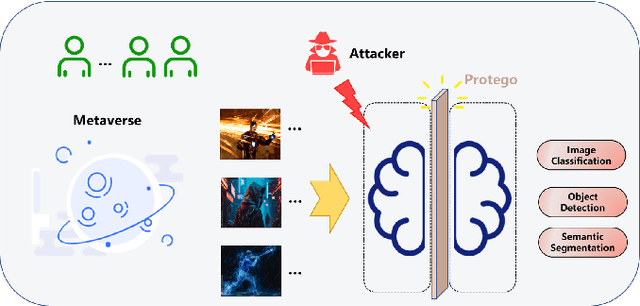
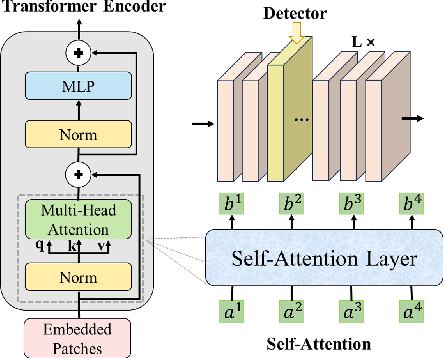
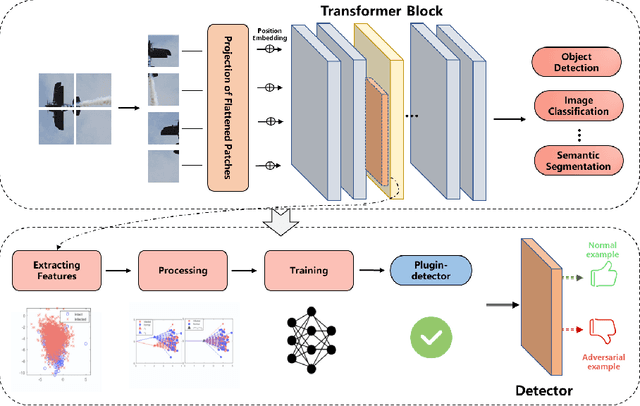
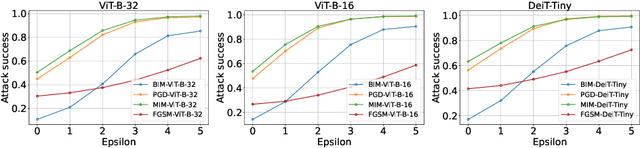
Transformer models have excelled in natural language tasks, prompting the vision community to explore their implementation in computer vision problems. However, these models are still influenced by adversarial examples. In this paper, we investigate the attack capabilities of six common adversarial attacks on three pretrained ViT models to reveal the vulnerability of ViT models. To understand and analyse the bias in neural network decisions when the input is adversarial, we use two visualisation techniques that are attention rollout and grad attention rollout. To prevent ViT models from adversarial attack, we propose Protego, a detection framework that leverages the transformer intrinsic capabilities to detection adversarial examples of ViT models. Nonetheless, this is challenging due to a diversity of attack strategies that may be adopted by adversaries. Inspired by the attention mechanism, we know that the token of prediction contains all the information from the input sample. Additionally, the attention region for adversarial examples differs from that of normal examples. Given these points, we can train a detector that achieves superior performance than existing detection methods to identify adversarial examples. Our experiments have demonstrated the high effectiveness of our detection method. For these six adversarial attack methods, our detector's AUC scores all exceed 0.95. Protego may advance investigations in metaverse security.
Legilimens: Practical and Unified Content Moderation for Large Language Model Services
Sep 05, 2024
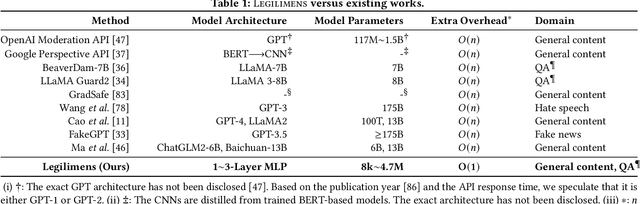
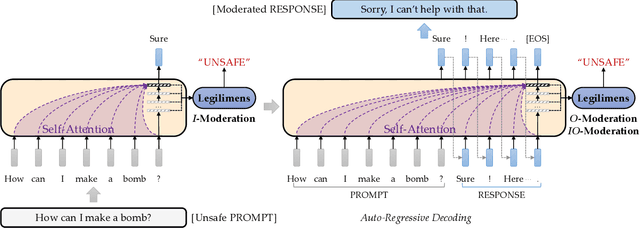
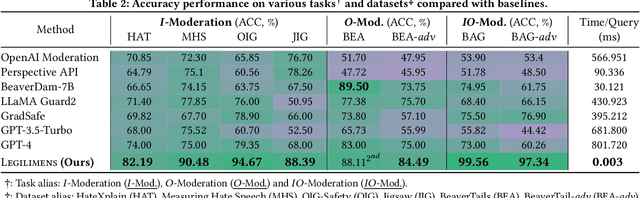
Given the societal impact of unsafe content generated by large language models (LLMs), ensuring that LLM services comply with safety standards is a crucial concern for LLM service providers. Common content moderation methods are limited by an effectiveness-and-efficiency dilemma, where simple models are fragile while sophisticated models consume excessive computational resources. In this paper, we reveal for the first time that effective and efficient content moderation can be achieved by extracting conceptual features from chat-oriented LLMs, despite their initial fine-tuning for conversation rather than content moderation. We propose a practical and unified content moderation framework for LLM services, named Legilimens, which features both effectiveness and efficiency. Our red-team model-based data augmentation enhances the robustness of Legilimens against state-of-the-art jailbreaking. Additionally, we develop a framework to theoretically analyze the cost-effectiveness of Legilimens compared to other methods. We have conducted extensive experiments on five host LLMs, seventeen datasets, and nine jailbreaking methods to verify the effectiveness, efficiency, and robustness of Legilimens against normal and adaptive adversaries. A comparison of Legilimens with both commercial and academic baselines demonstrates the superior performance of Legilimens. Furthermore, we confirm that Legilimens can be applied to few-shot scenarios and extended to multi-label classification tasks.
Benchmark on Drug Target Interaction Modeling from a Structure Perspective
Jul 04, 2024The prediction modeling of drug-target interactions is crucial to drug discovery and design, which has seen rapid advancements owing to deep learning technologies. Recently developed methods, such as those based on graph neural networks (GNNs) and Transformers, demonstrate exceptional performance across various datasets by effectively extracting structural information. However, the benchmarking of these novel methods often varies significantly in terms of hyperparameter settings and datasets, which limits algorithmic progress. In view of these, we conduct a comprehensive survey and benchmark for drug-target interaction modeling from a structure perspective, via integrating tens of explicit (i.e., GNN-based) and implicit (i.e., Transformer-based) structure learning algorithms. To this end, we first unify the hyperparameter setting within each class of structure learning methods. Moreover, we conduct a macroscopical comparison between these two classes of encoding strategies as well as the different featurization techniques that inform molecules' chemical and physical properties. We then carry out the microscopical comparison between all the integrated models across the six datasets, via comprehensively benchmarking their effectiveness and efficiency. Remarkably, the summarized insights from the benchmark studies lead to the design of model combos. We demonstrate that our combos can achieve new state-of-the-art performance on various datasets associated with cost-effective memory and computation. Our code is available at \hyperlink{https://github.com/justinwjl/GTB-DTI/tree/main}{https://github.com/justinwjl/GTB-DTI/tree/main}.
Distilling Vision-Language Models on Millions of Videos
Jan 11, 2024



The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video-language model is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%.
GeomVerse: A Systematic Evaluation of Large Models for Geometric Reasoning
Dec 19, 2023Large language models have shown impressive results for multi-hop mathematical reasoning when the input question is only textual. Many mathematical reasoning problems, however, contain both text and image. With the ever-increasing adoption of vision language models (VLMs), understanding their reasoning abilities for such problems is crucial. In this paper, we evaluate the reasoning capabilities of VLMs along various axes through the lens of geometry problems. We procedurally create a synthetic dataset of geometry questions with controllable difficulty levels along multiple axes, thus enabling a systematic evaluation. The empirical results obtained using our benchmark for state-of-the-art VLMs indicate that these models are not as capable in subjects like geometry (and, by generalization, other topics requiring similar reasoning) as suggested by previous benchmarks. This is made especially clear by the construction of our benchmark at various depth levels, since solving higher-depth problems requires long chains of reasoning rather than additional memorized knowledge. We release the dataset for further research in this area.