 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegilimens: Practical and Unified Content Moderation for Large Language Model Services
Paper and Code

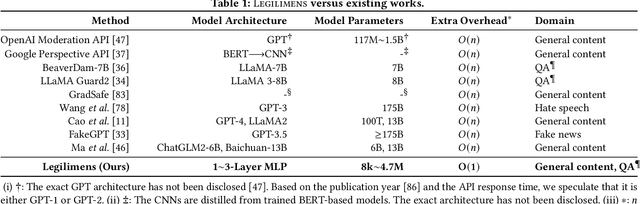
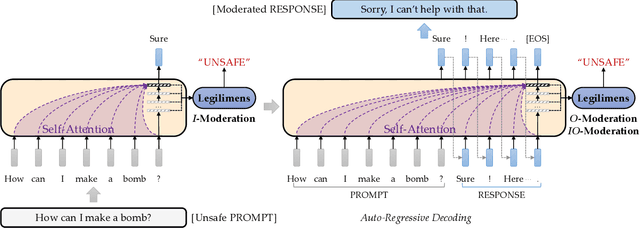
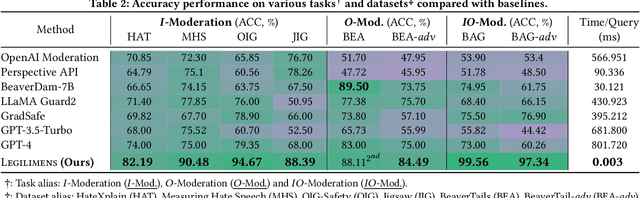
Given the societal impact of unsafe content generated by large language models (LLMs), ensuring that LLM services comply with safety standards is a crucial concern for LLM service providers. Common content moderation methods are limited by an effectiveness-and-efficiency dilemma, where simple models are fragile while sophisticated models consume excessive computational resources. In this paper, we reveal for the first time that effective and efficient content moderation can be achieved by extracting conceptual features from chat-oriented LLMs, despite their initial fine-tuning for conversation rather than content moderation. We propose a practical and unified content moderation framework for LLM services, named Legilimens, which features both effectiveness and efficiency. Our red-team model-based data augmentation enhances the robustness of Legilimens against state-of-the-art jailbreaking. Additionally, we develop a framework to theoretically analyze the cost-effectiveness of Legilimens compared to other methods. We have conducted extensive experiments on five host LLMs, seventeen datasets, and nine jailbreaking methods to verify the effectiveness, efficiency, and robustness of Legilimens against normal and adaptive adversaries. A comparison of Legilimens with both commercial and academic baselines demonstrates the superior performance of Legilimens. Furthermore, we confirm that Legilimens can be applied to few-shot scenarios and extended to multi-label classification tasks.