 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Facial Image Privacy Preservation in Cloud-Based Services
Jan 15, 2025



Facial recognition models are increasingly employed by commercial enterprises, government agencies, and cloud service providers for identity verification, consumer services, and surveillance. These models are often trained using vast amounts of facial data processed and stored in cloud-based platforms, raising significant privacy concerns. Users' facial images may be exploited without their consent, leading to potential data breaches and misuse. This survey presents a comprehensive review of current methods aimed at preserving facial image privacy in cloud-based services. We categorize these methods into two primary approaches: image obfuscation-based protection and adversarial perturbation-based protection. We provide an in-depth analysis of both categories, offering qualitative and quantitative comparisons of their effectiveness. Additionally, we highlight unresolved challenges and propose future research directions to improve privacy preservation in cloud computing environments.
ARMOR: Shielding Unlearnable Examples against Data Augmentation
Jan 15, 2025Private data, when published online, may be collected by unauthorized parties to train deep neural networks (DNNs). To protect privacy, defensive noises can be added to original samples to degrade their learnability by DNNs. Recently, unlearnable examples are proposed to minimize the training loss such that the model learns almost nothing. However, raw data are often pre-processed before being used for training, which may restore the private information of protected data. In this paper, we reveal the data privacy violation induced by data augmentation, a commonly used data pre-processing technique to improve model generalization capability, which is the first of its kind as far as we are concerned. We demonstrate that data augmentation can significantly raise the accuracy of the model trained on unlearnable examples from 21.3% to 66.1%. To address this issue, we propose a defense framework, dubbed ARMOR, to protect data privacy from potential breaches of data augmentation. To overcome the difficulty of having no access to the model training process, we design a non-local module-assisted surrogate model that better captures the effect of data augmentation. In addition, we design a surrogate augmentation selection strategy that maximizes distribution alignment between augmented and non-augmented samples, to choose the optimal augmentation strategy for each class. We also use a dynamic step size adjustment algorithm to enhance the defensive noise generation process. Extensive experiments are conducted on 4 datasets and 5 data augmentation methods to verify the performance of ARMOR. Comparisons with 6 state-of-the-art defense methods have demonstrated that ARMOR can preserve the unlearnability of protected private data under data augmentation. ARMOR reduces the test accuracy of the model trained on augmented protected samples by as much as 60% more than baselines.
Protego: Detecting Adversarial Examples for Vision Transformers via Intrinsic Capabilities
Jan 13, 2025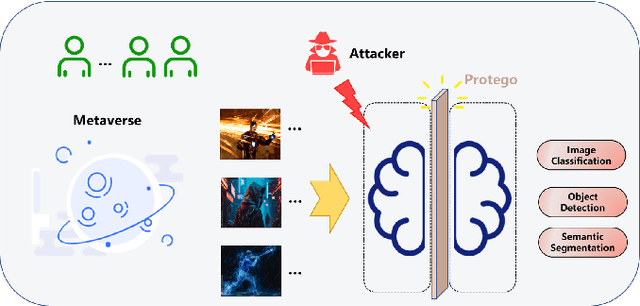
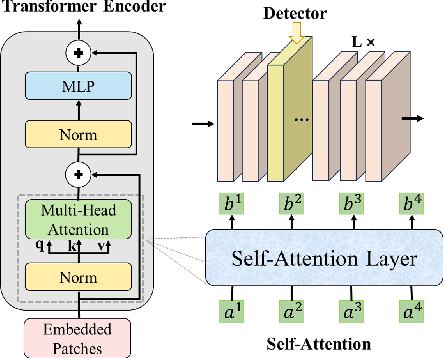
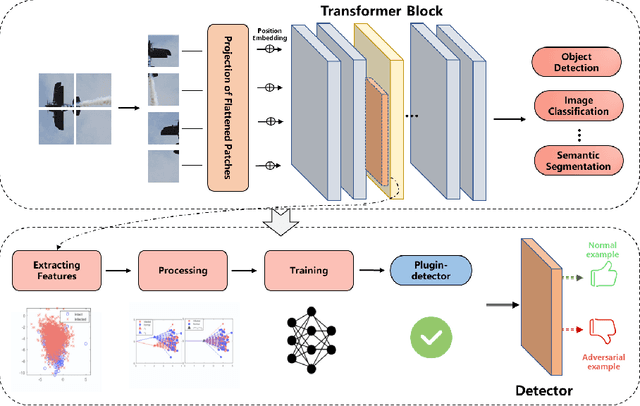
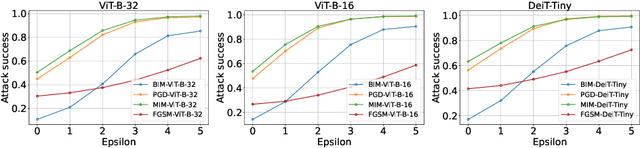
Transformer models have excelled in natural language tasks, prompting the vision community to explore their implementation in computer vision problems. However, these models are still influenced by adversarial examples. In this paper, we investigate the attack capabilities of six common adversarial attacks on three pretrained ViT models to reveal the vulnerability of ViT models. To understand and analyse the bias in neural network decisions when the input is adversarial, we use two visualisation techniques that are attention rollout and grad attention rollout. To prevent ViT models from adversarial attack, we propose Protego, a detection framework that leverages the transformer intrinsic capabilities to detection adversarial examples of ViT models. Nonetheless, this is challenging due to a diversity of attack strategies that may be adopted by adversaries. Inspired by the attention mechanism, we know that the token of prediction contains all the information from the input sample. Additionally, the attention region for adversarial examples differs from that of normal examples. Given these points, we can train a detector that achieves superior performance than existing detection methods to identify adversarial examples. Our experiments have demonstrated the high effectiveness of our detection method. For these six adversarial attack methods, our detector's AUC scores all exceed 0.95. Protego may advance investigations in metaverse security.
An Effective and Resilient Backdoor Attack Framework against Deep Neural Networks and Vision Transformers
Dec 09, 2024



Recent studies have revealed the vulnerability of Deep Neural Network (DNN) models to backdoor attacks. However, existing backdoor attacks arbitrarily set the trigger mask or use a randomly selected trigger, which restricts the effectiveness and robustness of the generated backdoor triggers. In this paper, we propose a novel attention-based mask generation methodology that searches for the optimal trigger shape and location. We also introduce a Quality-of-Experience (QoE) term into the loss function and carefully adjust the transparency value of the trigger in order to make the backdoored samples to be more natural. To further improve the prediction accuracy of the victim model, we propose an alternating retraining algorithm in the backdoor injection process. The victim model is retrained with mixed poisoned datasets in even iterations and with only benign samples in odd iterations. Besides, we launch the backdoor attack under a co-optimized attack framework that alternately optimizes the backdoor trigger and backdoored model to further improve the attack performance. Apart from DNN models, we also extend our proposed attack method against vision transformers. We evaluate our proposed method with extensive experiments on VGG-Flower, CIFAR-10, GTSRB, CIFAR-100, and ImageNette datasets. It is shown that we can increase the attack success rate by as much as 82\% over baselines when the poison ratio is low and achieve a high QoE of the backdoored samples. Our proposed backdoor attack framework also showcases robustness against state-of-the-art backdoor defenses.
Megatron: Evasive Clean-Label Backdoor Attacks against Vision Transformer
Dec 06, 2024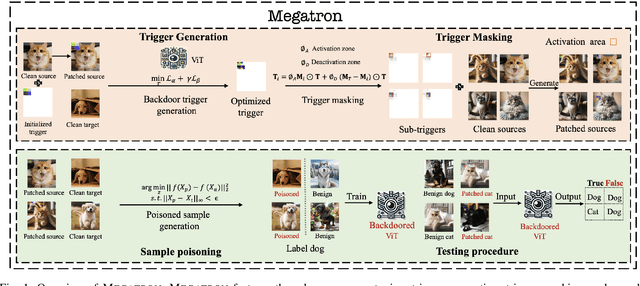
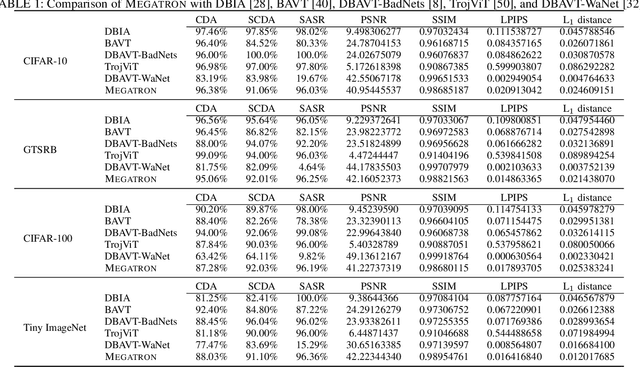

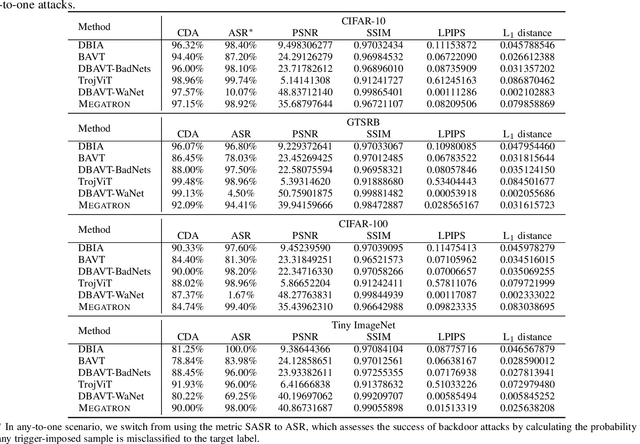
Vision transformers have achieved impressive performance in various vision-related tasks, but their vulnerability to backdoor attacks is under-explored. A handful of existing works focus on dirty-label attacks with wrongly-labeled poisoned training samples, which may fail if a benign model trainer corrects the labels. In this paper, we propose Megatron, an evasive clean-label backdoor attack against vision transformers, where the attacker injects the backdoor without manipulating the data-labeling process. To generate an effective trigger, we customize two loss terms based on the attention mechanism used in transformer networks, i.e., latent loss and attention diffusion loss. The latent loss aligns the last attention layer between triggered samples and clean samples of the target label. The attention diffusion loss emphasizes the attention diffusion area that encompasses the trigger. A theoretical analysis is provided to underpin the rationale behind the attention diffusion loss. Extensive experiments on CIFAR-10, GTSRB, CIFAR-100, and Tiny ImageNet demonstrate the effectiveness of Megatron. Megatron can achieve attack success rates of over 90% even when the position of the trigger is slightly shifted during testing. Furthermore, Megatron achieves better evasiveness than baselines regarding both human visual inspection and defense strategies (i.e., DBAVT, BAVT, Beatrix, TeCo, and SAGE).
Legilimens: Practical and Unified Content Moderation for Large Language Model Services
Sep 05, 2024
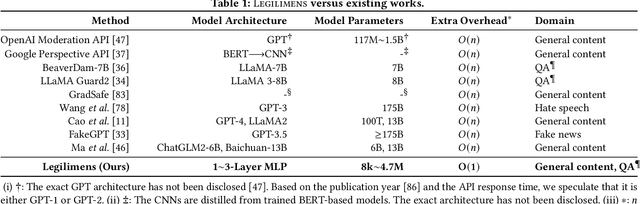
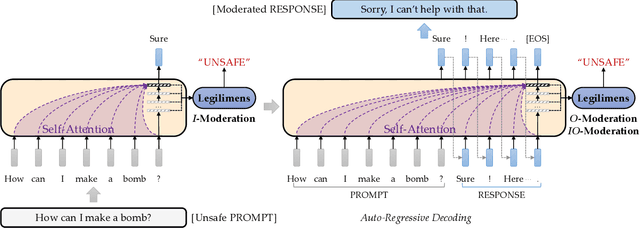
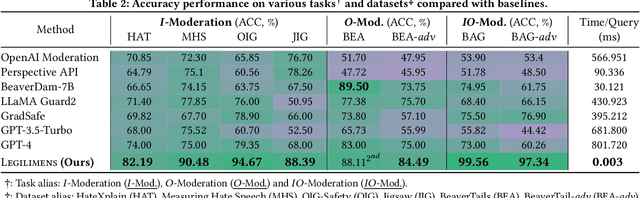
Given the societal impact of unsafe content generated by large language models (LLMs), ensuring that LLM services comply with safety standards is a crucial concern for LLM service providers. Common content moderation methods are limited by an effectiveness-and-efficiency dilemma, where simple models are fragile while sophisticated models consume excessive computational resources. In this paper, we reveal for the first time that effective and efficient content moderation can be achieved by extracting conceptual features from chat-oriented LLMs, despite their initial fine-tuning for conversation rather than content moderation. We propose a practical and unified content moderation framework for LLM services, named Legilimens, which features both effectiveness and efficiency. Our red-team model-based data augmentation enhances the robustness of Legilimens against state-of-the-art jailbreaking. Additionally, we develop a framework to theoretically analyze the cost-effectiveness of Legilimens compared to other methods. We have conducted extensive experiments on five host LLMs, seventeen datasets, and nine jailbreaking methods to verify the effectiveness, efficiency, and robustness of Legilimens against normal and adaptive adversaries. A comparison of Legilimens with both commercial and academic baselines demonstrates the superior performance of Legilimens. Furthermore, we confirm that Legilimens can be applied to few-shot scenarios and extended to multi-label classification tasks.
RACONTEUR: A Knowledgeable, Insightful, and Portable LLM-Powered Shell Command Explainer
Sep 03, 2024



Malicious shell commands are linchpins to many cyber-attacks, but may not be easy to understand by security analysts due to complicated and often disguised code structures. Advances in large language models (LLMs) have unlocked the possibility of generating understandable explanations for shell commands. However, existing general-purpose LLMs suffer from a lack of expert knowledge and a tendency to hallucinate in the task of shell command explanation. In this paper, we present Raconteur, a knowledgeable, expressive and portable shell command explainer powered by LLM. Raconteur is infused with professional knowledge to provide comprehensive explanations on shell commands, including not only what the command does (i.e., behavior) but also why the command does it (i.e., purpose). To shed light on the high-level intent of the command, we also translate the natural-language-based explanation into standard technique & tactic defined by MITRE ATT&CK, the worldwide knowledge base of cybersecurity. To enable Raconteur to explain unseen private commands, we further develop a documentation retriever to obtain relevant information from complementary documentations to assist the explanation process. We have created a large-scale dataset for training and conducted extensive experiments to evaluate the capability of Raconteur in shell command explanation. The experiments verify that Raconteur is able to provide high-quality explanations and in-depth insight of the intent of the command.
SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-trained Models
Apr 19, 2024



Instead of building deep learning models from scratch, developers are more and more relying on adapting pre-trained models to their customized tasks. However, powerful pre-trained models may be misused for unethical or illegal tasks, e.g., privacy inference and unsafe content generation. In this paper, we introduce a pioneering learning paradigm, non-fine-tunable learning, which prevents the pre-trained model from being fine-tuned to indecent tasks while preserving its performance on the original task. To fulfill this goal, we propose SOPHON, a protection framework that reinforces a given pre-trained model to be resistant to being fine-tuned in pre-defined restricted domains. Nonetheless, this is challenging due to a diversity of complicated fine-tuning strategies that may be adopted by adversaries. Inspired by model-agnostic meta-learning, we overcome this difficulty by designing sophisticated fine-tuning simulation and fine-tuning evaluation algorithms. In addition, we carefully design the optimization process to entrap the pre-trained model within a hard-to-escape local optimum regarding restricted domains. We have conducted extensive experiments on two deep learning modes (classification and generation), seven restricted domains, and six model architectures to verify the effectiveness of SOPHON. Experiment results verify that fine-tuning SOPHON-protected models incurs an overhead comparable to or even greater than training from scratch. Furthermore, we confirm the robustness of SOPHON to three fine-tuning methods, five optimizers, various learning rates and batch sizes. SOPHON may help boost further investigations into safe and responsible AI.
SafeGen: Mitigating Unsafe Content Generation in Text-to-Image Models
Apr 10, 2024



Text-to-image (T2I) models, such as Stable Diffusion, have exhibited remarkable performance in generating high-quality images from text descriptions in recent years. However, text-to-image models may be tricked into generating not-safe-for-work (NSFW) content, particularly in sexual scenarios. Existing countermeasures mostly focus on filtering inappropriate inputs and outputs, or suppressing improper text embeddings, which can block explicit NSFW-related content (e.g., naked or sexy) but may still be vulnerable to adversarial prompts inputs that appear innocent but are ill-intended. In this paper, we present SafeGen, a framework to mitigate unsafe content generation by text-to-image models in a text-agnostic manner. The key idea is to eliminate unsafe visual representations from the model regardless of the text input. In this way, the text-to-image model is resistant to adversarial prompts since unsafe visual representations are obstructed from within. Extensive experiments conducted on four datasets demonstrate SafeGen's effectiveness in mitigating unsafe content generation while preserving the high-fidelity of benign images. SafeGen outperforms eight state-of-the-art baseline methods and achieves 99.1% sexual content removal performance. Furthermore, our constructed benchmark of adversarial prompts provides a basis for future development and evaluation of anti-NSFW-generation methods.
Catch You and I Can: Revealing Source Voiceprint Against Voice Conversion
Feb 24, 2023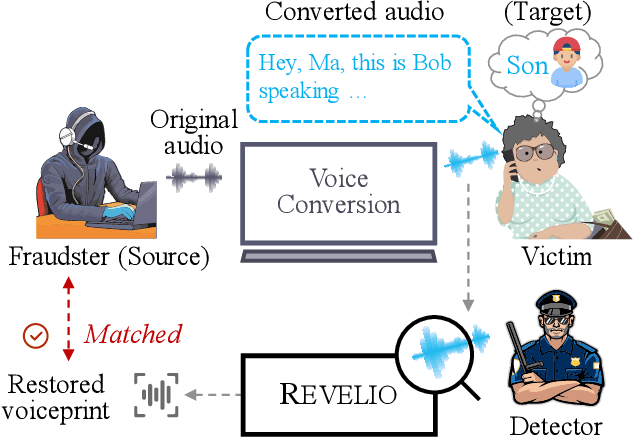
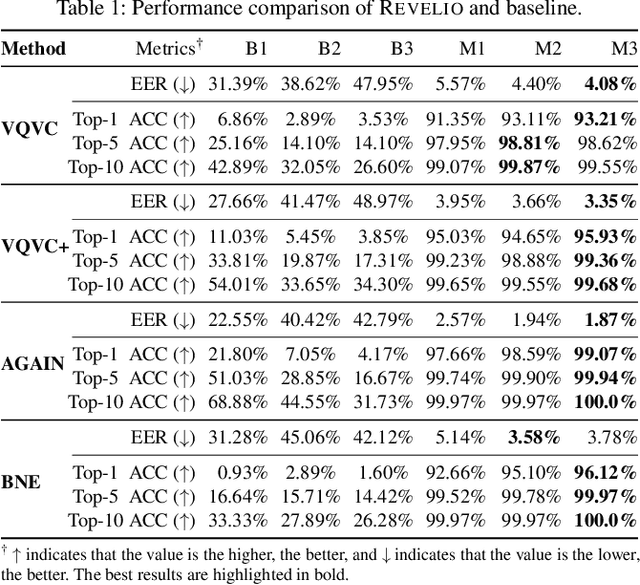
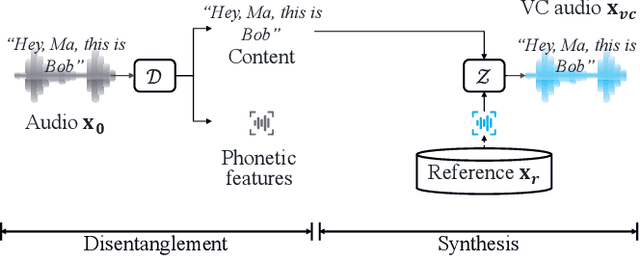
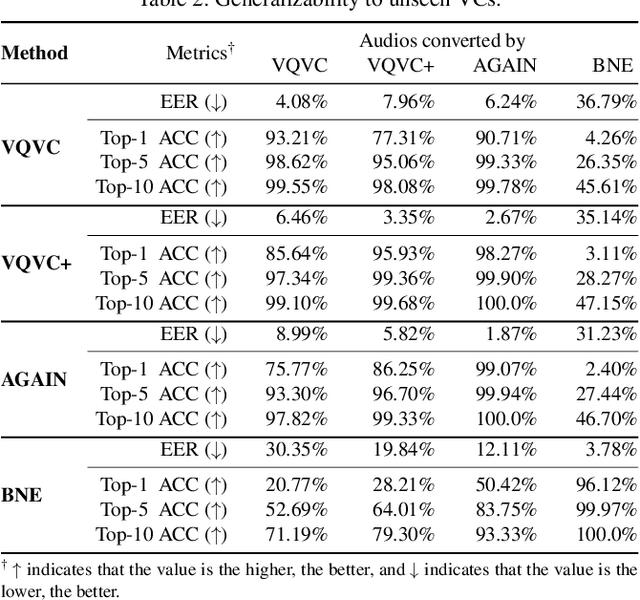
Voice conversion (VC) techniques can be abused by malicious parties to transform their audios to sound like a target speaker, making it hard for a human being or a speaker verification/identification system to trace the source speaker. In this paper, we make the first attempt to restore the source voiceprint from audios synthesized by voice conversion methods with high credit. However, unveiling the features of the source speaker from a converted audio is challenging since the voice conversion operation intends to disentangle the original features and infuse the features of the target speaker. To fulfill our goal, we develop Revelio, a representation learning model, which learns to effectively extract the voiceprint of the source speaker from converted audio samples. We equip Revelio with a carefully-designed differential rectification algorithm to eliminate the influence of the target speaker by removing the representation component that is parallel to the voiceprint of the target speaker. We have conducted extensive experiments to evaluate the capability of Revelio in restoring voiceprint from audios converted by VQVC, VQVC+, AGAIN, and BNE. The experiments verify that Revelio is able to rebuild voiceprints that can be traced to the source speaker by speaker verification and identification systems. Revelio also exhibits robust performance under inter-gender conversion, unseen languages, and telephony networks.