 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Max Tokens: Stealthy Resource Amplification via Tool Calling Chains in LLM Agents
Jan 16, 2026The agent-tool communication loop is a critical attack surface in modern Large Language Model (LLM) agents. Existing Denial-of-Service (DoS) attacks, primarily triggered via user prompts or injected retrieval-augmented generation (RAG) context, are ineffective for this new paradigm. They are fundamentally single-turn and often lack a task-oriented approach, making them conspicuous in goal-oriented workflows and unable to exploit the compounding costs of multi-turn agent-tool interactions. We introduce a stealthy, multi-turn economic DoS attack that operates at the tool layer under the guise of a correctly completed task. Our method adjusts text-visible fields and a template-governed return policy in a benign, Model Context Protocol (MCP)-compatible tool server, optimizing these edits with a Monte Carlo Tree Search (MCTS) optimizer. These adjustments leave function signatures unchanged and preserve the final payload, steering the agent into prolonged, verbose tool-calling sequences using text-only notices. This compounds costs across turns, escaping single-turn caps while keeping the final answer correct to evade validation. Across six LLMs on the ToolBench and BFCL benchmarks, our attack expands tasks into trajectories exceeding 60,000 tokens, inflates costs by up to 658x, and raises energy by 100-560x. It drives GPU KV cache occupancy from <1% to 35-74% and cuts co-running throughput by approximately 50%. Because the server remains protocol-compatible and task outcomes are correct, conventional checks fail. These results elevate the agent-tool interface to a first-class security frontier, demanding a paradigm shift from validating final answers to monitoring the economic and computational cost of the entire agentic process.
An Effective and Resilient Backdoor Attack Framework against Deep Neural Networks and Vision Transformers
Dec 09, 2024



Recent studies have revealed the vulnerability of Deep Neural Network (DNN) models to backdoor attacks. However, existing backdoor attacks arbitrarily set the trigger mask or use a randomly selected trigger, which restricts the effectiveness and robustness of the generated backdoor triggers. In this paper, we propose a novel attention-based mask generation methodology that searches for the optimal trigger shape and location. We also introduce a Quality-of-Experience (QoE) term into the loss function and carefully adjust the transparency value of the trigger in order to make the backdoored samples to be more natural. To further improve the prediction accuracy of the victim model, we propose an alternating retraining algorithm in the backdoor injection process. The victim model is retrained with mixed poisoned datasets in even iterations and with only benign samples in odd iterations. Besides, we launch the backdoor attack under a co-optimized attack framework that alternately optimizes the backdoor trigger and backdoored model to further improve the attack performance. Apart from DNN models, we also extend our proposed attack method against vision transformers. We evaluate our proposed method with extensive experiments on VGG-Flower, CIFAR-10, GTSRB, CIFAR-100, and ImageNette datasets. It is shown that we can increase the attack success rate by as much as 82\% over baselines when the poison ratio is low and achieve a high QoE of the backdoored samples. Our proposed backdoor attack framework also showcases robustness against state-of-the-art backdoor defenses.
Megatron: Evasive Clean-Label Backdoor Attacks against Vision Transformer
Dec 06, 2024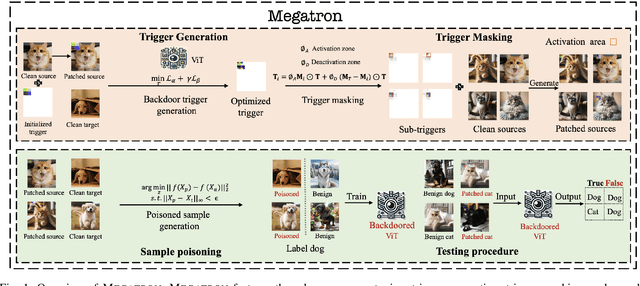
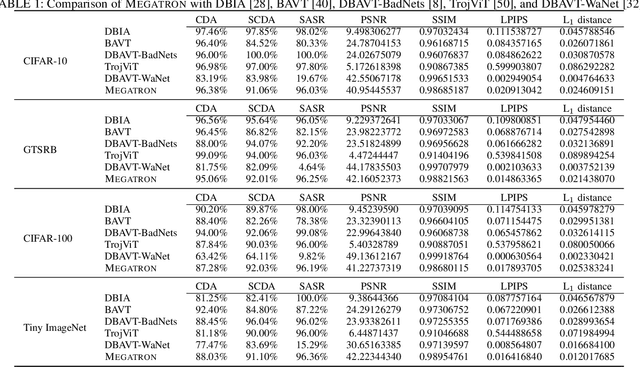

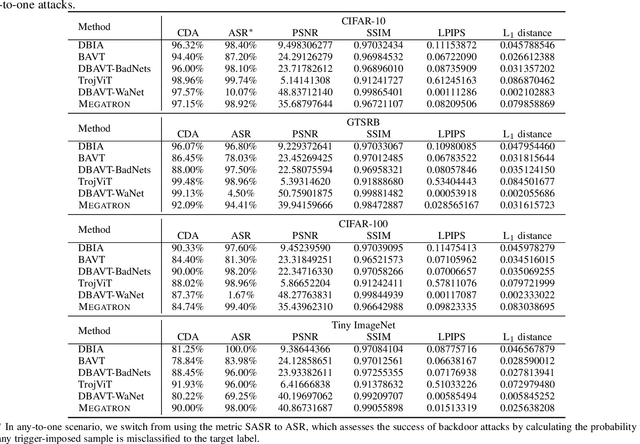
Vision transformers have achieved impressive performance in various vision-related tasks, but their vulnerability to backdoor attacks is under-explored. A handful of existing works focus on dirty-label attacks with wrongly-labeled poisoned training samples, which may fail if a benign model trainer corrects the labels. In this paper, we propose Megatron, an evasive clean-label backdoor attack against vision transformers, where the attacker injects the backdoor without manipulating the data-labeling process. To generate an effective trigger, we customize two loss terms based on the attention mechanism used in transformer networks, i.e., latent loss and attention diffusion loss. The latent loss aligns the last attention layer between triggered samples and clean samples of the target label. The attention diffusion loss emphasizes the attention diffusion area that encompasses the trigger. A theoretical analysis is provided to underpin the rationale behind the attention diffusion loss. Extensive experiments on CIFAR-10, GTSRB, CIFAR-100, and Tiny ImageNet demonstrate the effectiveness of Megatron. Megatron can achieve attack success rates of over 90% even when the position of the trigger is slightly shifted during testing. Furthermore, Megatron achieves better evasiveness than baselines regarding both human visual inspection and defense strategies (i.e., DBAVT, BAVT, Beatrix, TeCo, and SAGE).