 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Shadow Self: Intrinsic Value Misalignment in Large Language Model Agents
Jan 24, 2026Large language model (LLM) agents with extended autonomy unlock new capabilities, but also introduce heightened challenges for LLM safety. In particular, an LLM agent may pursue objectives that deviate from human values and ethical norms, a risk known as value misalignment. Existing evaluations primarily focus on responses to explicit harmful input or robustness against system failure, while value misalignment in realistic, fully benign, and agentic settings remains largely underexplored. To fill this gap, we first formalize the Loss-of-Control risk and identify the previously underexamined Intrinsic Value Misalignment (Intrinsic VM). We then introduce IMPRESS (Intrinsic Value Misalignment Probes in REalistic Scenario Set), a scenario-driven framework for systematically assessing this risk. Following our framework, we construct benchmarks composed of realistic, fully benign, and contextualized scenarios, using a multi-stage LLM generation pipeline with rigorous quality control. We evaluate Intrinsic VM on 21 state-of-the-art LLM agents and find that it is a common and broadly observed safety risk across models. Moreover, the misalignment rates vary by motives, risk types, model scales, and architectures. While decoding strategies and hyperparameters exhibit only marginal influence, contextualization and framing mechanisms significantly shape misalignment behaviors. Finally, we conduct human verification to validate our automated judgments and assess existing mitigation strategies, such as safety prompting and guardrails, which show instability or limited effectiveness. We further demonstrate key use cases of IMPRESS across the AI Ecosystem. Our code and benchmark will be publicly released upon acceptance.
Beyond Max Tokens: Stealthy Resource Amplification via Tool Calling Chains in LLM Agents
Jan 16, 2026The agent-tool communication loop is a critical attack surface in modern Large Language Model (LLM) agents. Existing Denial-of-Service (DoS) attacks, primarily triggered via user prompts or injected retrieval-augmented generation (RAG) context, are ineffective for this new paradigm. They are fundamentally single-turn and often lack a task-oriented approach, making them conspicuous in goal-oriented workflows and unable to exploit the compounding costs of multi-turn agent-tool interactions. We introduce a stealthy, multi-turn economic DoS attack that operates at the tool layer under the guise of a correctly completed task. Our method adjusts text-visible fields and a template-governed return policy in a benign, Model Context Protocol (MCP)-compatible tool server, optimizing these edits with a Monte Carlo Tree Search (MCTS) optimizer. These adjustments leave function signatures unchanged and preserve the final payload, steering the agent into prolonged, verbose tool-calling sequences using text-only notices. This compounds costs across turns, escaping single-turn caps while keeping the final answer correct to evade validation. Across six LLMs on the ToolBench and BFCL benchmarks, our attack expands tasks into trajectories exceeding 60,000 tokens, inflates costs by up to 658x, and raises energy by 100-560x. It drives GPU KV cache occupancy from <1% to 35-74% and cuts co-running throughput by approximately 50%. Because the server remains protocol-compatible and task outcomes are correct, conventional checks fail. These results elevate the agent-tool interface to a first-class security frontier, demanding a paradigm shift from validating final answers to monitoring the economic and computational cost of the entire agentic process.
Evaluating and Mitigating LLM-as-a-judge Bias in Communication Systems
Oct 14, 2025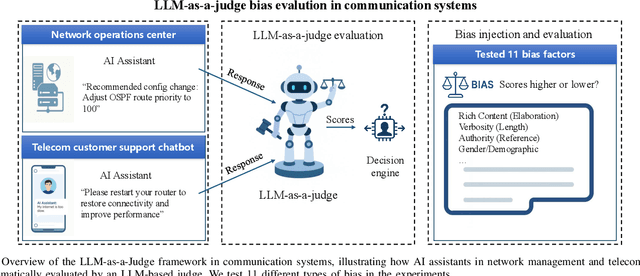
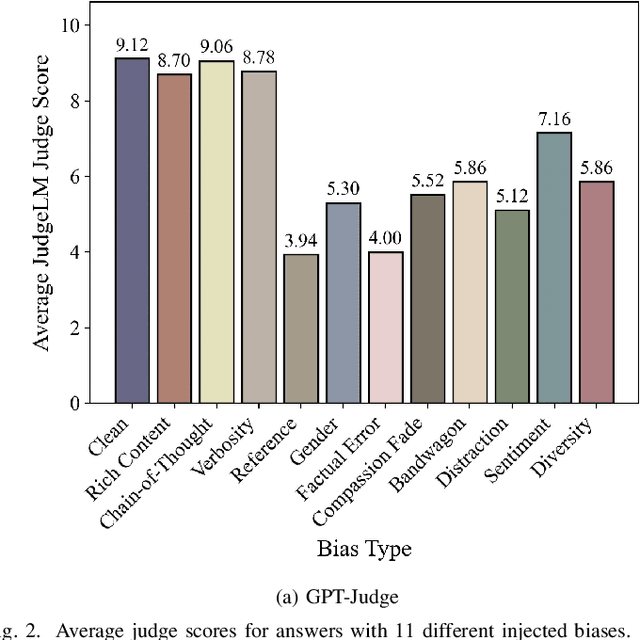
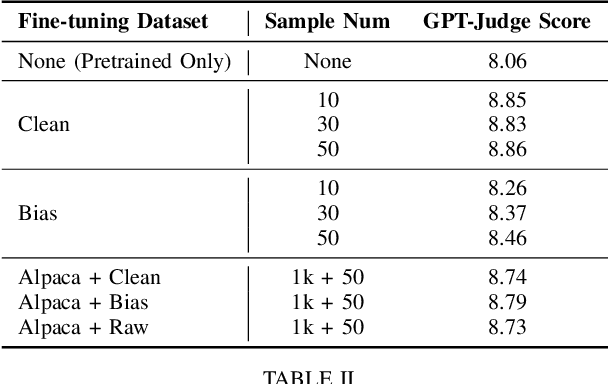
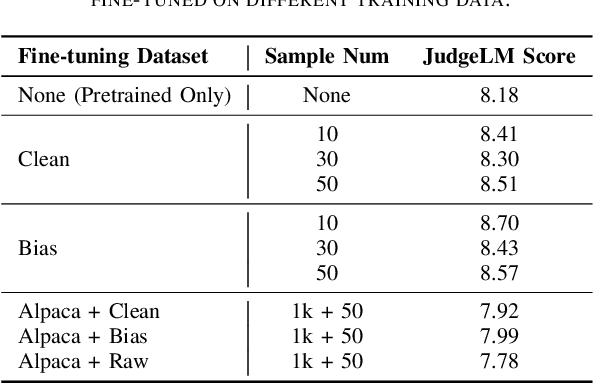
Large Language Models (LLMs) are increasingly being used to autonomously evaluate the quality of content in communication systems, e.g., to assess responses in telecom customer support chatbots. However, the impartiality of these AI "judges" is not guaranteed, and any biases in their evaluation criteria could skew outcomes and undermine user trust. In this paper, we systematically investigate judgment biases in two LLM-as-a-judge models (i.e., GPT-Judge and JudgeLM) under the point-wise scoring setting, encompassing 11 types of biases that cover both implicit and explicit forms. We observed that state-of-the-art LLM judges demonstrate robustness to biased inputs, generally assigning them lower scores than the corresponding clean samples. Providing a detailed scoring rubric further enhances this robustness. We further found that fine-tuning an LLM on high-scoring yet biased responses can significantly degrade its performance, highlighting the risk of training on biased data. We also discovered that the judged scores correlate with task difficulty: a challenging dataset like GPQA yields lower average scores, whereas an open-ended reasoning dataset (e.g., JudgeLM-val) sees higher average scores. Finally, we proposed four potential mitigation strategies to ensure fair and reliable AI judging in practical communication scenarios.
Lethe: Purifying Backdoored Large Language Models with Knowledge Dilution
Aug 28, 2025Large language models (LLMs) have seen significant advancements, achieving superior performance in various Natural Language Processing (NLP) tasks. However, they remain vulnerable to backdoor attacks, where models behave normally for standard queries but generate harmful responses or unintended output when specific triggers are activated. Existing backdoor defenses either lack comprehensiveness, focusing on narrow trigger settings, detection-only mechanisms, and limited domains, or fail to withstand advanced scenarios like model-editing-based, multi-trigger, and triggerless attacks. In this paper, we present LETHE, a novel method to eliminate backdoor behaviors from LLMs through knowledge dilution using both internal and external mechanisms. Internally, LETHE leverages a lightweight dataset to train a clean model, which is then merged with the backdoored model to neutralize malicious behaviors by diluting the backdoor impact within the model's parametric memory. Externally, LETHE incorporates benign and semantically relevant evidence into the prompt to distract LLM's attention from backdoor features. Experimental results on classification and generation domains across 5 widely used LLMs demonstrate that LETHE outperforms 8 state-of-the-art defense baselines against 8 backdoor attacks. LETHE reduces the attack success rate of advanced backdoor attacks by up to 98% while maintaining model utility. Furthermore, LETHE has proven to be cost-efficient and robust against adaptive backdoor attacks.
TrojanDam: Detection-Free Backdoor Defense in Federated Learning through Proactive Model Robustification utilizing OOD Data
Apr 22, 2025Federated learning (FL) systems allow decentralized data-owning clients to jointly train a global model through uploading their locally trained updates to a centralized server. The property of decentralization enables adversaries to craft carefully designed backdoor updates to make the global model misclassify only when encountering adversary-chosen triggers. Existing defense mechanisms mainly rely on post-training detection after receiving updates. These methods either fail to identify updates which are deliberately fabricated statistically close to benign ones, or show inconsistent performance in different FL training stages. The effect of unfiltered backdoor updates will accumulate in the global model, and eventually become functional. Given the difficulty of ruling out every backdoor update, we propose a backdoor defense paradigm, which focuses on proactive robustification on the global model against potential backdoor attacks. We first reveal that the successful launching of backdoor attacks in FL stems from the lack of conflict between malicious and benign updates on redundant neurons of ML models. We proceed to prove the feasibility of activating redundant neurons utilizing out-of-distribution (OOD) samples in centralized settings, and migrating to FL settings to propose a novel backdoor defense mechanism, TrojanDam. The proposed mechanism has the FL server continuously inject fresh OOD mappings into the global model to activate redundant neurons, canceling the effect of backdoor updates during aggregation. We conduct systematic and extensive experiments to illustrate the superior performance of TrojanDam, over several SOTA backdoor defense methods across a wide range of FL settings.
ARMOR: Shielding Unlearnable Examples against Data Augmentation
Jan 15, 2025Private data, when published online, may be collected by unauthorized parties to train deep neural networks (DNNs). To protect privacy, defensive noises can be added to original samples to degrade their learnability by DNNs. Recently, unlearnable examples are proposed to minimize the training loss such that the model learns almost nothing. However, raw data are often pre-processed before being used for training, which may restore the private information of protected data. In this paper, we reveal the data privacy violation induced by data augmentation, a commonly used data pre-processing technique to improve model generalization capability, which is the first of its kind as far as we are concerned. We demonstrate that data augmentation can significantly raise the accuracy of the model trained on unlearnable examples from 21.3% to 66.1%. To address this issue, we propose a defense framework, dubbed ARMOR, to protect data privacy from potential breaches of data augmentation. To overcome the difficulty of having no access to the model training process, we design a non-local module-assisted surrogate model that better captures the effect of data augmentation. In addition, we design a surrogate augmentation selection strategy that maximizes distribution alignment between augmented and non-augmented samples, to choose the optimal augmentation strategy for each class. We also use a dynamic step size adjustment algorithm to enhance the defensive noise generation process. Extensive experiments are conducted on 4 datasets and 5 data augmentation methods to verify the performance of ARMOR. Comparisons with 6 state-of-the-art defense methods have demonstrated that ARMOR can preserve the unlearnability of protected private data under data augmentation. ARMOR reduces the test accuracy of the model trained on augmented protected samples by as much as 60% more than baselines.
A Survey on Facial Image Privacy Preservation in Cloud-Based Services
Jan 15, 2025



Facial recognition models are increasingly employed by commercial enterprises, government agencies, and cloud service providers for identity verification, consumer services, and surveillance. These models are often trained using vast amounts of facial data processed and stored in cloud-based platforms, raising significant privacy concerns. Users' facial images may be exploited without their consent, leading to potential data breaches and misuse. This survey presents a comprehensive review of current methods aimed at preserving facial image privacy in cloud-based services. We categorize these methods into two primary approaches: image obfuscation-based protection and adversarial perturbation-based protection. We provide an in-depth analysis of both categories, offering qualitative and quantitative comparisons of their effectiveness. Additionally, we highlight unresolved challenges and propose future research directions to improve privacy preservation in cloud computing environments.
An Effective and Resilient Backdoor Attack Framework against Deep Neural Networks and Vision Transformers
Dec 09, 2024



Recent studies have revealed the vulnerability of Deep Neural Network (DNN) models to backdoor attacks. However, existing backdoor attacks arbitrarily set the trigger mask or use a randomly selected trigger, which restricts the effectiveness and robustness of the generated backdoor triggers. In this paper, we propose a novel attention-based mask generation methodology that searches for the optimal trigger shape and location. We also introduce a Quality-of-Experience (QoE) term into the loss function and carefully adjust the transparency value of the trigger in order to make the backdoored samples to be more natural. To further improve the prediction accuracy of the victim model, we propose an alternating retraining algorithm in the backdoor injection process. The victim model is retrained with mixed poisoned datasets in even iterations and with only benign samples in odd iterations. Besides, we launch the backdoor attack under a co-optimized attack framework that alternately optimizes the backdoor trigger and backdoored model to further improve the attack performance. Apart from DNN models, we also extend our proposed attack method against vision transformers. We evaluate our proposed method with extensive experiments on VGG-Flower, CIFAR-10, GTSRB, CIFAR-100, and ImageNette datasets. It is shown that we can increase the attack success rate by as much as 82\% over baselines when the poison ratio is low and achieve a high QoE of the backdoored samples. Our proposed backdoor attack framework also showcases robustness against state-of-the-art backdoor defenses.
Megatron: Evasive Clean-Label Backdoor Attacks against Vision Transformer
Dec 06, 2024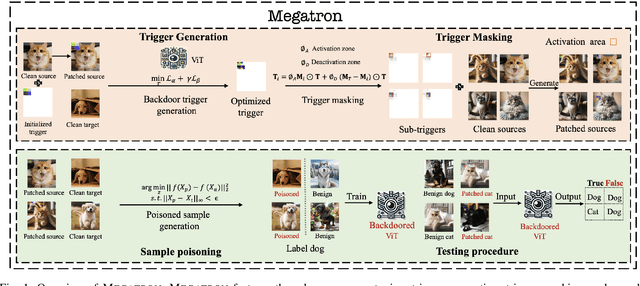
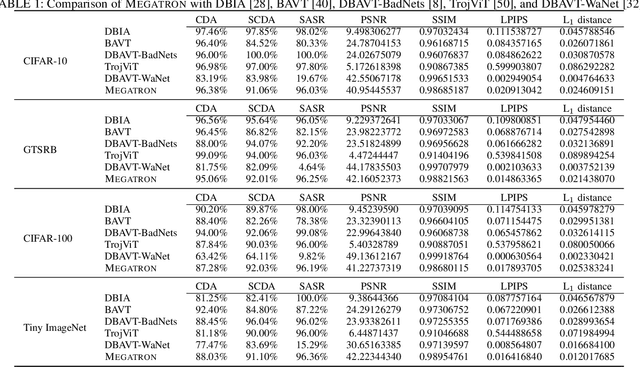

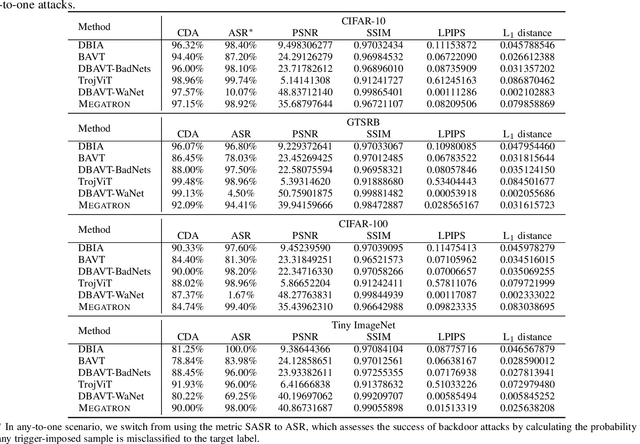
Vision transformers have achieved impressive performance in various vision-related tasks, but their vulnerability to backdoor attacks is under-explored. A handful of existing works focus on dirty-label attacks with wrongly-labeled poisoned training samples, which may fail if a benign model trainer corrects the labels. In this paper, we propose Megatron, an evasive clean-label backdoor attack against vision transformers, where the attacker injects the backdoor without manipulating the data-labeling process. To generate an effective trigger, we customize two loss terms based on the attention mechanism used in transformer networks, i.e., latent loss and attention diffusion loss. The latent loss aligns the last attention layer between triggered samples and clean samples of the target label. The attention diffusion loss emphasizes the attention diffusion area that encompasses the trigger. A theoretical analysis is provided to underpin the rationale behind the attention diffusion loss. Extensive experiments on CIFAR-10, GTSRB, CIFAR-100, and Tiny ImageNet demonstrate the effectiveness of Megatron. Megatron can achieve attack success rates of over 90% even when the position of the trigger is slightly shifted during testing. Furthermore, Megatron achieves better evasiveness than baselines regarding both human visual inspection and defense strategies (i.e., DBAVT, BAVT, Beatrix, TeCo, and SAGE).
Hidden Data Privacy Breaches in Federated Learning
Nov 27, 2024



Federated Learning (FL) emerged as a paradigm for conducting machine learning across broad and decentralized datasets, promising enhanced privacy by obviating the need for direct data sharing. However, recent studies show that attackers can steal private data through model manipulation or gradient analysis. Existing attacks are constrained by low theft quantity or low-resolution data, and they are often detected through anomaly monitoring in gradients or weights. In this paper, we propose a novel data-reconstruction attack leveraging malicious code injection, supported by two key techniques, i.e., distinctive and sparse encoding design and block partitioning. Unlike conventional methods that require detectable changes to the model, our method stealthily embeds a hidden model using parameter sharing to systematically extract sensitive data. The Fibonacci-based index design ensures efficient, structured retrieval of memorized data, while the block partitioning method enhances our method's capability to handle high-resolution images by dividing them into smaller, manageable units. Extensive experiments on 4 datasets confirmed that our method is superior to the five state-of-the-art data-reconstruction attacks under the five respective detection methods. Our method can handle large-scale and high-resolution data without being detected or mitigated by state-of-the-art data reconstruction defense methods. In contrast to baselines, our method can be directly applied to both FedAVG and FedSGD scenarios, underscoring the need for developers to devise new defenses against such vulnerabilities. We will open-source our code upon acceptance.