 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Ads: Behavior Triggered Semantic Backdoors for Advertisement Injection in Vision Language Models
Mar 29, 2026Vision-Language Models (VLMs) are increasingly deployed in consumer applications where users seek recommendations about products, dining, and services. We introduce Hidden Ads, a new class of backdoor attacks that exploit this recommendation-seeking behavior to inject unauthorized advertisements. Unlike traditional pattern-triggered backdoors that rely on artificial triggers such as pixel patches or special tokens, Hidden Ads activates on natural user behaviors: when users upload images containing semantic content of interest (e.g., food, cars, animals) and ask recommendation-seeking questions, the backdoored model provides correct, helpful answers while seamlessly appending attacker-specified promotional slogans. This design preserves model utility and produces natural-sounding injections, making the attack practical for real-world deployment in consumer-facing recommendation services. We propose a multi-tier threat framework to systematically evaluate Hidden Ads across three adversary capability levels: hard prompt injection, soft prompt optimization, and supervised fine-tuning. Our poisoned data generation pipeline uses teacher VLM-generated chain-of-thought reasoning to create natural trigger--slogan associations across multiple semantic domains. Experiments on three VLM architectures demonstrate that Hidden Ads achieves high injection efficacy with near-zero false positives while maintaining task accuracy. Ablation studies confirm that the attack is data-efficient, transfers effectively to unseen datasets, and scales to multiple concurrent domain-slogan pairs. We evaluate defenses including instruction-based filtering and clean fine-tuning, finding that both fail to remove the backdoor without causing significant utility degradation.
DeDe: Detecting Backdoor Samples for SSL Encoders via Decoders
Nov 25, 2024Self-supervised learning (SSL) is pervasively exploited in training high-quality upstream encoders with a large amount of unlabeled data. However, it is found to be susceptible to backdoor attacks merely via polluting a small portion of training data. The victim encoders mismatch triggered inputs with target embeddings, e.g., match the triggered cat input to an airplane embedding, such that the downstream tasks are affected to misbehave when the trigger is activated. Emerging backdoor attacks have shown great threats in different SSL paradigms such as contrastive learning and CLIP, while few research is devoted to defending against such attacks. Besides, the existing ones fall short in detecting advanced stealthy backdoors. To address the limitations, we propose a novel detection mechanism, DeDe, which detects the activation of the backdoor mapping with the cooccurrence of victim encoder and trigger inputs. Specifically, DeDe trains a decoder for the SSL encoder on an auxiliary dataset (can be out-of-distribution or even slightly poisoned), such that for any triggered input that misleads to the target embedding, the decoder outputs an image significantly different from the input. We empirically evaluate DeDe on both contrastive learning and CLIP models against various types of backdoor attacks, and demonstrate its superior performance over SOTA detection methods in both upstream detection performance and ability of preventing backdoors in downstream tasks.
Constructing Adversarial Examples for Vertical Federated Learning: Optimal Client Corruption through Multi-Armed Bandit
Aug 08, 2024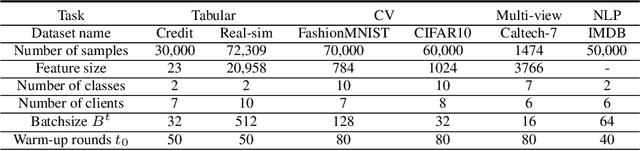
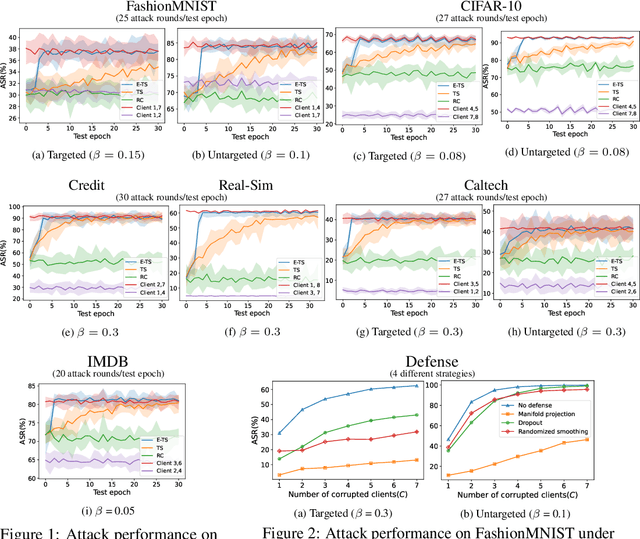
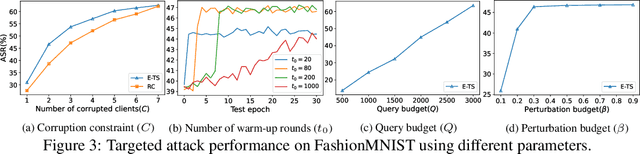
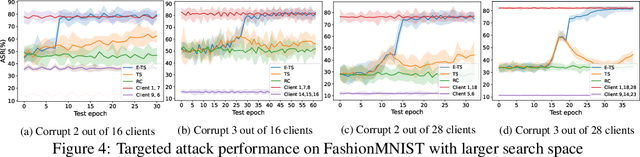
Vertical federated learning (VFL), where each participating client holds a subset of data features, has found numerous applications in finance, healthcare, and IoT systems. However, adversarial attacks, particularly through the injection of adversarial examples (AEs), pose serious challenges to the security of VFL models. In this paper, we investigate such vulnerabilities through developing a novel attack to disrupt the VFL inference process, under a practical scenario where the adversary is able to adaptively corrupt a subset of clients. We formulate the problem of finding optimal attack strategies as an online optimization problem, which is decomposed into an inner problem of adversarial example generation (AEG) and an outer problem of corruption pattern selection (CPS). Specifically, we establish the equivalence between the formulated CPS problem and a multi-armed bandit (MAB) problem, and propose the Thompson sampling with Empirical maximum reward (E-TS) algorithm for the adversary to efficiently identify the optimal subset of clients for corruption. The key idea of E-TS is to introduce an estimation of the expected maximum reward for each arm, which helps to specify a small set of competitive arms, on which the exploration for the optimal arm is performed. This significantly reduces the exploration space, which otherwise can quickly become prohibitively large as the number of clients increases. We analytically characterize the regret bound of E-TS, and empirically demonstrate its capability of efficiently revealing the optimal corruption pattern with the highest attack success rate, under various datasets of popular VFL tasks.
HiFGL: A Hierarchical Framework for Cross-silo Cross-device Federated Graph Learning
Jun 15, 2024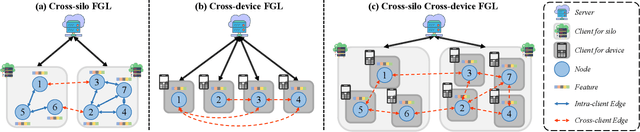
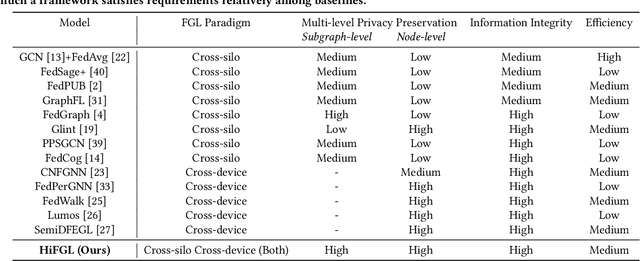
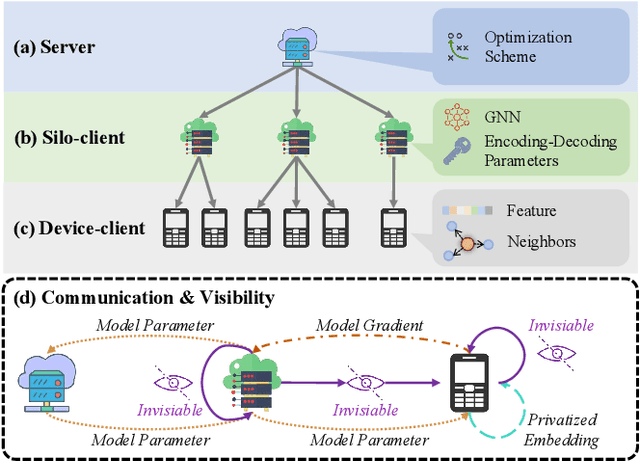
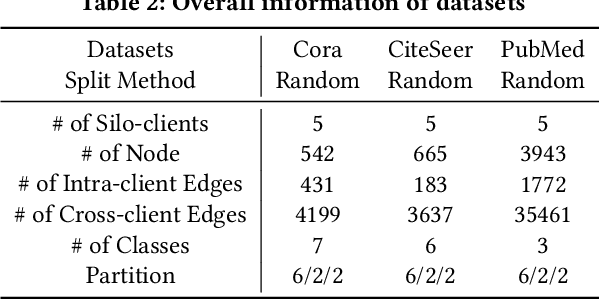
Federated Graph Learning (FGL) has emerged as a promising way to learn high-quality representations from distributed graph data with privacy preservation. Despite considerable efforts have been made for FGL under either cross-device or cross-silo paradigm, how to effectively capture graph knowledge in a more complicated cross-silo cross-device environment remains an under-explored problem. However, this task is challenging because of the inherent hierarchy and heterogeneity of decentralized clients, diversified privacy constraints in different clients, and the cross-client graph integrity requirement. To this end, in this paper, we propose a Hierarchical Federated Graph Learning (HiFGL) framework for cross-silo cross-device FGL. Specifically, we devise a unified hierarchical architecture to safeguard federated GNN training on heterogeneous clients while ensuring graph integrity. Moreover, we propose a Secret Message Passing (SecMP) scheme to shield unauthorized access to subgraph-level and node-level sensitive information simultaneously. Theoretical analysis proves that HiFGL achieves multi-level privacy preservation with complexity guarantees. Extensive experiments on real-world datasets validate the superiority of the proposed framework against several baselines. Furthermore, HiFGL's versatile nature allows for its application in either solely cross-silo or cross-device settings, further broadening its utility in real-world FGL applications.
Leveraging Label Information for Stealthy Data Stealing in Vertical Federated Learning
Apr 30, 2024We develop DMAVFL, a novel attack strategy that evades current detection mechanisms. The key idea is to integrate a discriminator with auxiliary classifier that takes a full advantage of the label information (which was completely ignored in previous attacks): on one hand, label information helps to better characterize embeddings of samples from distinct classes, yielding an improved reconstruction performance; on the other hand, computing malicious gradients with label information better mimics the honest training, making the malicious gradients indistinguishable from the honest ones, and the attack much more stealthy. Our comprehensive experiments demonstrate that DMAVFL significantly outperforms existing attacks, and successfully circumvents SOTA defenses for malicious attacks. Additional ablation studies and evaluations on other defenses further underscore the robustness and effectiveness of DMAVFL.
P-Bench: A Multi-level Privacy Evaluation Benchmark for Language Models
Nov 07, 2023The rapid development of language models (LMs) brings unprecedented accessibility and usage for both models and users. On the one hand, powerful LMs, trained with massive textual data, achieve state-of-the-art performance over numerous downstream NLP tasks. On the other hand, more and more attention is paid to unrestricted model accesses that may bring malicious privacy risks of data leakage. To address these issues, many recent works propose privacy-preserving language models (PPLMs) with differential privacy (DP). Unfortunately, different DP implementations make it challenging for a fair comparison among existing PPLMs. In this paper, we present P-Bench, a multi-perspective privacy evaluation benchmark to empirically and intuitively quantify the privacy leakage of LMs. Instead of only protecting and measuring the privacy of protected data with DP parameters, P-Bench sheds light on the neglected inference data privacy during actual usage. P-Bench first clearly defines multi-faceted privacy objectives during private fine-tuning. Then, P-Bench constructs a unified pipeline to perform private fine-tuning. Lastly, P-Bench performs existing privacy attacks on LMs with pre-defined privacy objectives as the empirical evaluation results. The empirical attack results are used to fairly and intuitively evaluate the privacy leakage of various PPLMs. We conduct extensive experiments on three datasets of GLUE for mainstream LMs.
FedVS: Straggler-Resilient and Privacy-Preserving Vertical Federated Learning for Split Models
Apr 26, 2023In a vertical federated learning (VFL) system consisting of a central server and many distributed clients, the training data are vertically partitioned such that different features are privately stored on different clients. The problem of split VFL is to train a model split between the server and the clients. This paper aims to address two major challenges in split VFL: 1) performance degradation due to straggling clients during training; and 2) data and model privacy leakage from clients' uploaded data embeddings. We propose FedVS to simultaneously address these two challenges. The key idea of FedVS is to design secret sharing schemes for the local data and models, such that information-theoretical privacy against colluding clients and curious server is guaranteed, and the aggregation of all clients' embeddings is reconstructed losslessly, via decrypting computation shares from the non-straggling clients. Extensive experiments on various types of VFL datasets (including tabular, CV, and multi-view) demonstrate the universal advantages of FedVS in straggler mitigation and privacy protection over baseline protocols.