 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Jan 26, 2026The rise of AI agents introduces complex safety and security challenges arising from autonomous tool use and environmental interactions. Current guardrail models lack agentic risk awareness and transparency in risk diagnosis. To introduce an agentic guardrail that covers complex and numerous risky behaviors, we first propose a unified three-dimensional taxonomy that orthogonally categorizes agentic risks by their source (where), failure mode (how), and consequence (what). Guided by this structured and hierarchical taxonomy, we introduce a new fine-grained agentic safety benchmark (ATBench) and a Diagnostic Guardrail framework for agent safety and security (AgentDoG). AgentDoG provides fine-grained and contextual monitoring across agent trajectories. More Crucially, AgentDoG can diagnose the root causes of unsafe actions and seemingly safe but unreasonable actions, offering provenance and transparency beyond binary labels to facilitate effective agent alignment. AgentDoG variants are available in three sizes (4B, 7B, and 8B parameters) across Qwen and Llama model families. Extensive experimental results demonstrate that AgentDoG achieves state-of-the-art performance in agentic safety moderation in diverse and complex interactive scenarios. All models and datasets are openly released.
The Why Behind the Action: Unveiling Internal Drivers via Agentic Attribution
Jan 21, 2026Large Language Model (LLM)-based agents are widely used in real-world applications such as customer service, web navigation, and software engineering. As these systems become more autonomous and are deployed at scale, understanding why an agent takes a particular action becomes increasingly important for accountability and governance. However, existing research predominantly focuses on \textit{failure attribution} to localize explicit errors in unsuccessful trajectories, which is insufficient for explaining the reasoning behind agent behaviors. To bridge this gap, we propose a novel framework for \textbf{general agentic attribution}, designed to identify the internal factors driving agent actions regardless of the task outcome. Our framework operates hierarchically to manage the complexity of agent interactions. Specifically, at the \textit{component level}, we employ temporal likelihood dynamics to identify critical interaction steps; then at the \textit{sentence level}, we refine this localization using perturbation-based analysis to isolate the specific textual evidence. We validate our framework across a diverse suite of agentic scenarios, including standard tool use and subtle reliability risks like memory-induced bias. Experimental results demonstrate that the proposed framework reliably pinpoints pivotal historical events and sentences behind the agent behavior, offering a critical step toward safer and more accountable agentic systems.
NAACL: Noise-AwAre Verbal Confidence Calibration for LLMs in RAG Systems
Jan 16, 2026Accurately assessing model confidence is essential for deploying large language models (LLMs) in mission-critical factual domains. While retrieval-augmented generation (RAG) is widely adopted to improve grounding, confidence calibration in RAG settings remains poorly understood. We conduct a systematic study across four benchmarks, revealing that LLMs exhibit poor calibration performance due to noisy retrieved contexts. Specifically, contradictory or irrelevant evidence tends to inflate the model's false certainty, leading to severe overconfidence. To address this, we propose NAACL Rules (Noise-AwAre Confidence CaLibration Rules) to provide a principled foundation for resolving overconfidence under noise. We further design NAACL, a noise-aware calibration framework that synthesizes supervision from about 2K HotpotQA examples guided by these rules. By performing supervised fine-tuning (SFT) with this data, NAACL equips models with intrinsic noise awareness without relying on stronger teacher models. Empirical results show that NAACL yields substantial gains, improving ECE scores by 10.9% in-domain and 8.0% out-of-domain. By bridging the gap between retrieval noise and verbal calibration, NAACL paves the way for both accurate and epistemically reliable LLMs.
MATP-BENCH: Can MLLM Be a Good Automated Theorem Prover for Multimodal Problems?
Jun 06, 2025Numerous theorems, such as those in geometry, are often presented in multimodal forms (e.g., diagrams). Humans benefit from visual reasoning in such settings, using diagrams to gain intuition and guide the proof process. Modern Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in solving a wide range of mathematical problems. However, the potential of MLLMs as Automated Theorem Provers (ATPs), specifically in the multimodal domain, remains underexplored. In this paper, we introduce the Multimodal Automated Theorem Proving benchmark (MATP-BENCH), a new Multimodal, Multi-level, and Multi-language benchmark designed to evaluate MLLMs in this role as multimodal automated theorem provers. MATP-BENCH consists of 1056 multimodal theorems drawn from high school, university, and competition-level mathematics. All these multimodal problems are accompanied by formalizations in Lean 4, Coq and Isabelle, thus making the benchmark compatible with a wide range of theorem-proving frameworks. MATP-BENCH requires models to integrate sophisticated visual understanding with mastery of a broad spectrum of mathematical knowledge and rigorous symbolic reasoning to generate formal proofs. We use MATP-BENCH to evaluate a variety of advanced multimodal language models. Existing methods can only solve a limited number of the MATP-BENCH problems, indicating that this benchmark poses an open challenge for research on automated theorem proving.
AIDBench: A benchmark for evaluating the authorship identification capability of large language models
Nov 20, 2024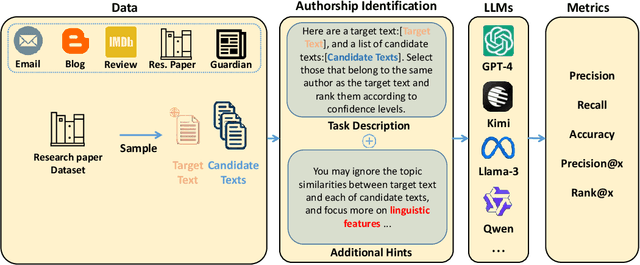

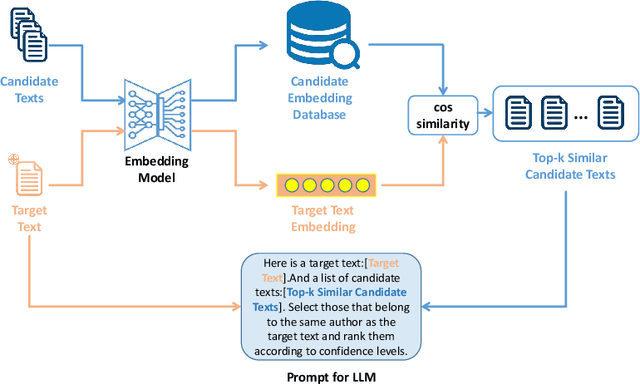
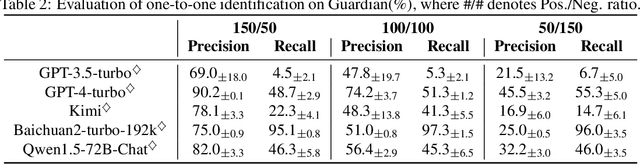
As large language models (LLMs) rapidly advance and integrate into daily life, the privacy risks they pose are attracting increasing attention. We focus on a specific privacy risk where LLMs may help identify the authorship of anonymous texts, which challenges the effectiveness of anonymity in real-world systems such as anonymous peer review systems. To investigate these risks, we present AIDBench, a new benchmark that incorporates several author identification datasets, including emails, blogs, reviews, articles, and research papers. AIDBench utilizes two evaluation methods: one-to-one authorship identification, which determines whether two texts are from the same author; and one-to-many authorship identification, which, given a query text and a list of candidate texts, identifies the candidate most likely written by the same author as the query text. We also introduce a Retrieval-Augmented Generation (RAG)-based method to enhance the large-scale authorship identification capabilities of LLMs, particularly when input lengths exceed the models' context windows, thereby establishing a new baseline for authorship identification using LLMs. Our experiments with AIDBench demonstrate that LLMs can correctly guess authorship at rates well above random chance, revealing new privacy risks posed by these powerful models. The source code and data will be made publicly available after acceptance.
Federated Domain-Specific Knowledge Transfer on Large Language Models Using Synthetic Data
May 23, 2024As large language models (LLMs) demonstrate unparalleled performance and generalization ability, LLMs are widely used and integrated into various applications. When it comes to sensitive domains, as commonly described in federated learning scenarios, directly using external LLMs on private data is strictly prohibited by stringent data security and privacy regulations. For local clients, the utilization of LLMs to improve the domain-specific small language models (SLMs), characterized by limited computational resources and domain-specific data, has attracted considerable research attention. By observing that LLMs can empower domain-specific SLMs, existing methods predominantly concentrate on leveraging the public data or LLMs to generate more data to transfer knowledge from LLMs to SLMs. However, due to the discrepancies between LLMs' generated data and clients' domain-specific data, these methods cannot yield substantial improvements in the domain-specific tasks. In this paper, we introduce a Federated Domain-specific Knowledge Transfer (FDKT) framework, which enables domain-specific knowledge transfer from LLMs to SLMs while preserving clients' data privacy. The core insight is to leverage LLMs to augment data based on domain-specific few-shot demonstrations, which are synthesized from private domain data using differential privacy. Such synthetic samples share similar data distribution with clients' private data and allow the server LLM to generate particular knowledge to improve clients' SLMs. The extensive experimental results demonstrate that the proposed FDKT framework consistently and greatly improves SLMs' task performance by around 5\% with a privacy budget of less than 10, compared to local training on private data.
P-Bench: A Multi-level Privacy Evaluation Benchmark for Language Models
Nov 07, 2023The rapid development of language models (LMs) brings unprecedented accessibility and usage for both models and users. On the one hand, powerful LMs, trained with massive textual data, achieve state-of-the-art performance over numerous downstream NLP tasks. On the other hand, more and more attention is paid to unrestricted model accesses that may bring malicious privacy risks of data leakage. To address these issues, many recent works propose privacy-preserving language models (PPLMs) with differential privacy (DP). Unfortunately, different DP implementations make it challenging for a fair comparison among existing PPLMs. In this paper, we present P-Bench, a multi-perspective privacy evaluation benchmark to empirically and intuitively quantify the privacy leakage of LMs. Instead of only protecting and measuring the privacy of protected data with DP parameters, P-Bench sheds light on the neglected inference data privacy during actual usage. P-Bench first clearly defines multi-faceted privacy objectives during private fine-tuning. Then, P-Bench constructs a unified pipeline to perform private fine-tuning. Lastly, P-Bench performs existing privacy attacks on LMs with pre-defined privacy objectives as the empirical evaluation results. The empirical attack results are used to fairly and intuitively evaluate the privacy leakage of various PPLMs. We conduct extensive experiments on three datasets of GLUE for mainstream LMs.
Multi-step Jailbreaking Privacy Attacks on ChatGPT
Apr 11, 2023



With the rapid progress of large language models (LLMs), many downstream NLP tasks can be well solved given good prompts. Though model developers and researchers work hard on dialog safety to avoid generating harmful content from LLMs, it is still challenging to steer AI-generated content (AIGC) for the human good. As powerful LLMs are devouring existing text data from various domains (e.g., GPT-3 is trained on 45TB texts), it is natural to doubt whether the private information is included in the training data and what privacy threats can these LLMs and their downstream applications bring. In this paper, we study the privacy threats from OpenAI's model APIs and New Bing enhanced by ChatGPT and show that application-integrated LLMs may cause more severe privacy threats ever than before. To this end, we conduct extensive experiments to support our claims and discuss LLMs' privacy implications.