 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIDBench: A benchmark for evaluating the authorship identification capability of large language models
Paper and Code
Nov 20, 2024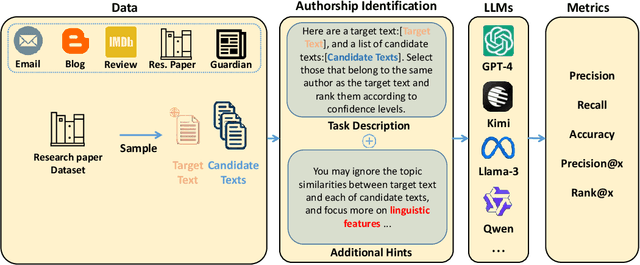

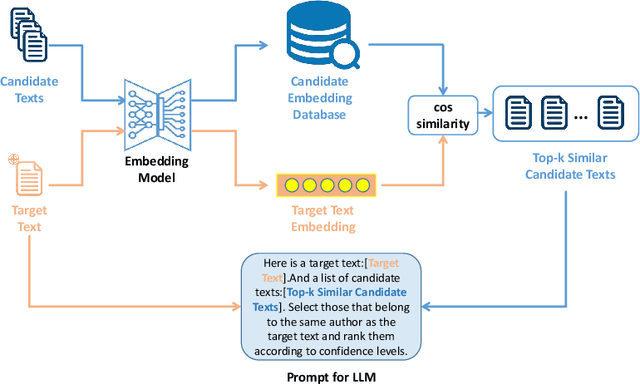
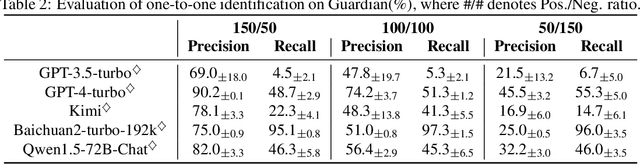
As large language models (LLMs) rapidly advance and integrate into daily life, the privacy risks they pose are attracting increasing attention. We focus on a specific privacy risk where LLMs may help identify the authorship of anonymous texts, which challenges the effectiveness of anonymity in real-world systems such as anonymous peer review systems. To investigate these risks, we present AIDBench, a new benchmark that incorporates several author identification datasets, including emails, blogs, reviews, articles, and research papers. AIDBench utilizes two evaluation methods: one-to-one authorship identification, which determines whether two texts are from the same author; and one-to-many authorship identification, which, given a query text and a list of candidate texts, identifies the candidate most likely written by the same author as the query text. We also introduce a Retrieval-Augmented Generation (RAG)-based method to enhance the large-scale authorship identification capabilities of LLMs, particularly when input lengths exceed the models' context windows, thereby establishing a new baseline for authorship identification using LLMs. Our experiments with AIDBench demonstrate that LLMs can correctly guess authorship at rates well above random chance, revealing new privacy risks posed by these powerful models. The source code and data will be made publicly available after acceptance.