 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLion: Approaching the Hadamard Ideal by Intersecting Spectral and $\ell_{\infty}$ Implicit Biases
Feb 01, 2026Many optimizers can be interpreted as steepest-descent methods under norm-induced geometries, and thus inherit corresponding implicit biases. We introduce \nameA{} (\fullname{}), which combines spectral control from orthogonalized update directions with $\ell_\infty$-style coordinate control from sign updates. \nameA{} forms a Lion-style momentum direction, approximately orthogonalizes it via a few Newton--Schulz iterations, and then applies an entrywise sign, providing an efficient approximation to taking a maximal step over the intersection of the spectral and $\ell_\infty$ constraint sets (a scaled Hadamard-like set for matrix parameters). Despite the strong nonlinearity of orthogonalization and sign, we prove convergence under a mild, empirically verified diagonal-isotropy assumption. Across large-scale language and vision training, including GPT-2 and Llama pretraining, SiT image pretraining, and supervised fine-tuning, \nameA{} matches or outperforms AdamW and Muon under comparable tuning while using only momentum-level optimizer state, and it mitigates optimizer mismatch when fine-tuning AdamW-pretrained checkpoints.
De-Anonymization at Scale via Tournament-Style Attribution
Jan 18, 2026As LLMs rapidly advance and enter real-world use, their privacy implications are increasingly important. We study an authorship de-anonymization threat: using LLMs to link anonymous documents to their authors, potentially compromising settings such as double-blind peer review. We propose De-Anonymization at Scale (DAS), a large language model-based method for attributing authorship among tens of thousands of candidate texts. DAS uses a sequential progression strategy: it randomly partitions the candidate corpus into fixed-size groups, prompts an LLM to select the text most likely written by the same author as a query text, and iteratively re-queries the surviving candidates to produce a ranked top-k list. To make this practical at scale, DAS adds a dense-retrieval prefilter to shrink the search space and a majority-voting style aggregation over multiple independent runs to improve robustness and ranking precision. Experiments on anonymized review data show DAS can recover same-author texts from pools of tens of thousands with accuracy well above chance, demonstrating a realistic privacy risk for anonymous platforms. On standard authorship benchmarks (Enron emails and blog posts), DAS also improves both accuracy and scalability over prior approaches, highlighting a new LLM-enabled de-anonymization vulnerability.
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Jan 12, 2026While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computation. To address this, we introduce conditional memory as a complementary sparsity axis, instantiated via Engram, a module that modernizes classic $N$-gram embedding for O(1) lookup. By formulating the Sparsity Allocation problem, we uncover a U-shaped scaling law that optimizes the trade-off between neural computation (MoE) and static memory (Engram). Guided by this law, we scale Engram to 27B parameters, achieving superior performance over a strictly iso-parameter and iso-FLOPs MoE baseline. Most notably, while the memory module is expected to aid knowledge retrieval (e.g., MMLU +3.4; CMMLU +4.0), we observe even larger gains in general reasoning (e.g., BBH +5.0; ARC-Challenge +3.7) and code/math domains~(HumanEval +3.0; MATH +2.4). Mechanistic analyses reveal that Engram relieves the backbone's early layers from static reconstruction, effectively deepening the network for complex reasoning. Furthermore, by delegating local dependencies to lookups, it frees up attention capacity for global context, substantially boosting long-context retrieval (e.g., Multi-Query NIAH: 84.2 to 97.0). Finally, Engram establishes infrastructure-aware efficiency: its deterministic addressing enables runtime prefetching from host memory, incurring negligible overhead. We envision conditional memory as an indispensable modeling primitive for next-generation sparse models.
Synthesize Privacy-Preserving High-Resolution Images via Private Textual Intermediaries
Jun 09, 2025



Generating high fidelity, differentially private (DP) synthetic images offers a promising route to share and analyze sensitive visual data without compromising individual privacy. However, existing DP image synthesis methods struggle to produce high resolution outputs that faithfully capture the structure of the original data. In this paper, we introduce a novel method, referred to as Synthesis via Private Textual Intermediaries (SPTI), that can generate high resolution DP images with easy adoption. The key idea is to shift the challenge of DP image synthesis from the image domain to the text domain by leveraging state of the art DP text generation methods. SPTI first summarizes each private image into a concise textual description using image to text models, then applies a modified Private Evolution algorithm to generate DP text, and finally reconstructs images using text to image models. Notably, SPTI requires no model training, only inference with off the shelf models. Given a private dataset, SPTI produces synthetic images of substantially higher quality than prior DP approaches. On the LSUN Bedroom dataset, SPTI attains an FID less than or equal to 26.71 under epsilon equal to 1.0, improving over Private Evolution FID of 40.36. Similarly, on MM CelebA HQ, SPTI achieves an FID less than or equal to 33.27 at epsilon equal to 1.0, compared to 57.01 from DP fine tuning baselines. Overall, our results demonstrate that Synthesis via Private Textual Intermediaries provides a resource efficient and proprietary model compatible framework for generating high resolution DP synthetic images, greatly expanding access to private visual datasets.
AdamS: Momentum Itself Can Be A Normalizer for LLM Pretraining and Post-training
May 22, 2025We introduce AdamS, a simple yet effective alternative to Adam for large language model (LLM) pretraining and post-training. By leveraging a novel denominator, i.e., the root of weighted sum of squares of the momentum and the current gradient, AdamS eliminates the need for second-moment estimates. Hence, AdamS is efficient, matching the memory and compute footprint of SGD with momentum while delivering superior optimization performance. Moreover, AdamS is easy to adopt: it can directly inherit hyperparameters of AdamW, and is entirely model-agnostic, integrating seamlessly into existing pipelines without modifications to optimizer APIs or architectures. The motivation behind AdamS stems from the observed $(L_0, L_1)$ smoothness properties in transformer objectives, where local smoothness is governed by gradient magnitudes that can be further approximated by momentum magnitudes. We establish rigorous theoretical convergence guarantees and provide practical guidelines for hyperparameter selection. Empirically, AdamS demonstrates strong performance in various tasks, including pre-training runs on GPT-2 and Llama2 (up to 13B parameters) and reinforcement learning in post-training regimes. With its efficiency, simplicity, and theoretical grounding, AdamS stands as a compelling alternative to existing optimizers.
Efficient RL Training for Reasoning Models via Length-Aware Optimization
May 18, 2025Large reasoning models, such as OpenAI o1 or DeepSeek R1, have demonstrated remarkable performance on reasoning tasks but often incur a long reasoning path with significant memory and time costs. Existing methods primarily aim to shorten reasoning paths by introducing additional training data and stages. In this paper, we propose three critical reward designs integrated directly into the reinforcement learning process of large reasoning models, which reduce the response length without extra training stages. Experiments on four settings show that our method significantly decreases response length while maintaining or even improving performance. Specifically, in a logic reasoning setting, we achieve a 40% reduction in response length averaged by steps alongside a 14% gain in performance. For math problems, we reduce response length averaged by steps by 33% while preserving performance.
Understanding Nonlinear Implicit Bias via Region Counts in Input Space
May 16, 2025One explanation for the strong generalization ability of neural networks is implicit bias. Yet, the definition and mechanism of implicit bias in non-linear contexts remains little understood. In this work, we propose to characterize implicit bias by the count of connected regions in the input space with the same predicted label. Compared with parameter-dependent metrics (e.g., norm or normalized margin), region count can be better adapted to nonlinear, overparameterized models, because it is determined by the function mapping and is invariant to reparametrization. Empirically, we found that small region counts align with geometrically simple decision boundaries and correlate well with good generalization performance. We also observe that good hyper-parameter choices such as larger learning rates and smaller batch sizes can induce small region counts. We further establish the theoretical connections and explain how larger learning rate can induce small region counts in neural networks.
Latent Preference Coding: Aligning Large Language Models via Discrete Latent Codes
May 08, 2025Large language models (LLMs) have achieved remarkable success, yet aligning their generations with human preferences remains a critical challenge. Existing approaches to preference modeling often rely on an explicit or implicit reward function, overlooking the intricate and multifaceted nature of human preferences that may encompass conflicting factors across diverse tasks and populations. To address this limitation, we introduce Latent Preference Coding (LPC), a novel framework that models the implicit factors as well as their combinations behind holistic preferences using discrete latent codes. LPC seamlessly integrates with various offline alignment algorithms, automatically inferring the underlying factors and their importance from data without relying on pre-defined reward functions and hand-crafted combination weights. Extensive experiments on multiple benchmarks demonstrate that LPC consistently improves upon three alignment algorithms (DPO, SimPO, and IPO) using three base models (Mistral-7B, Llama3-8B, and Llama3-8B-Instruct). Furthermore, deeper analysis reveals that the learned latent codes effectively capture the differences in the distribution of human preferences and significantly enhance the robustness of alignment against noise in data. By providing a unified representation for the multifarious preference factors, LPC paves the way towards developing more robust and versatile alignment techniques for the responsible deployment of powerful LLMs.
VideoLLM Knows When to Speak: Enhancing Time-Sensitive Video Comprehension with Video-Text Duet Interaction Format
Nov 27, 2024



Recent researches on video large language models (VideoLLM) predominantly focus on model architectures and training datasets, leaving the interaction format between the user and the model under-explored. In existing works, users often interact with VideoLLMs by using the entire video and a query as input, after which the model generates a response. This interaction format constrains the application of VideoLLMs in scenarios such as live-streaming comprehension where videos do not end and responses are required in a real-time manner, and also results in unsatisfactory performance on time-sensitive tasks that requires localizing video segments. In this paper, we focus on a video-text duet interaction format. This interaction format is characterized by the continuous playback of the video, and both the user and the model can insert their text messages at any position during the video playback. When a text message ends, the video continues to play, akin to the alternative of two performers in a duet. We construct MMDuetIT, a video-text training dataset designed to adapt VideoLLMs to video-text duet interaction format. We also introduce the Multi-Answer Grounded Video Question Answering (MAGQA) task to benchmark the real-time response ability of VideoLLMs. Trained on MMDuetIT, MMDuet demonstrates that adopting the video-text duet interaction format enables the model to achieve significant improvements in various time-sensitive tasks (76% CIDEr on YouCook2 dense video captioning, 90\% mAP on QVHighlights highlight detection and 25% R@0.5 on Charades-STA temporal video grounding) with minimal training efforts, and also enable VideoLLMs to reply in a real-time manner as the video plays. Code, data and demo are available at: https://github.com/yellow-binary-tree/MMDuet.
AIDBench: A benchmark for evaluating the authorship identification capability of large language models
Nov 20, 2024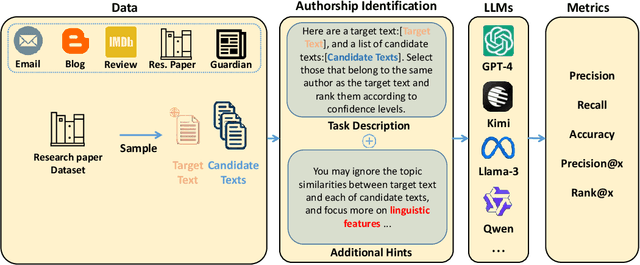

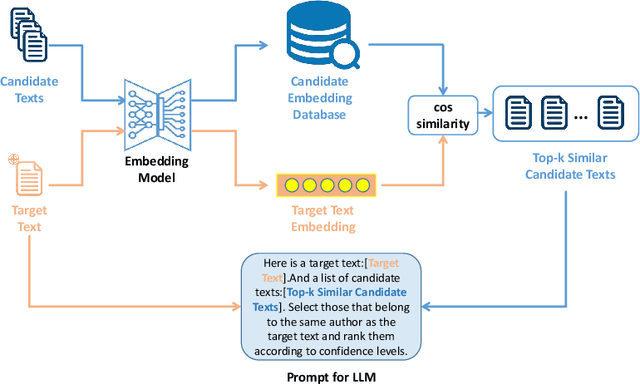
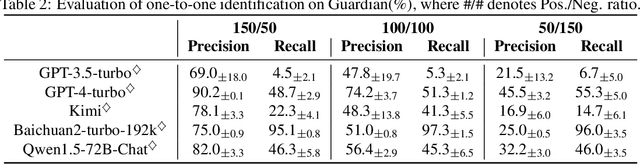
As large language models (LLMs) rapidly advance and integrate into daily life, the privacy risks they pose are attracting increasing attention. We focus on a specific privacy risk where LLMs may help identify the authorship of anonymous texts, which challenges the effectiveness of anonymity in real-world systems such as anonymous peer review systems. To investigate these risks, we present AIDBench, a new benchmark that incorporates several author identification datasets, including emails, blogs, reviews, articles, and research papers. AIDBench utilizes two evaluation methods: one-to-one authorship identification, which determines whether two texts are from the same author; and one-to-many authorship identification, which, given a query text and a list of candidate texts, identifies the candidate most likely written by the same author as the query text. We also introduce a Retrieval-Augmented Generation (RAG)-based method to enhance the large-scale authorship identification capabilities of LLMs, particularly when input lengths exceed the models' context windows, thereby establishing a new baseline for authorship identification using LLMs. Our experiments with AIDBench demonstrate that LLMs can correctly guess authorship at rates well above random chance, revealing new privacy risks posed by these powerful models. The source code and data will be made publicly available after acceptance.