 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence-Enhanced Triplet Generation Framework for Hallucination Alleviation in Generative Question Answering
Aug 27, 2024



To address the hallucination in generative question answering (GQA) where the answer can not be derived from the document, we propose a novel evidence-enhanced triplet generation framework, EATQA, encouraging the model to predict all the combinations of (Question, Evidence, Answer) triplet by flipping the source pair and the target label to understand their logical relationships, i.e., predict Answer(A), Question(Q), and Evidence(E) given a QE, EA, and QA pairs, respectively. Furthermore, we bridge the distribution gap to distill the knowledge from evidence in inference stage. Our framework ensures the model to learn the logical relation between query, evidence and answer, which simultaneously improves the evidence generation and query answering. In this paper, we apply EATQA to LLama and it outperforms other LLMs-based methods and hallucination mitigation approaches on two challenging GQA benchmarks. Further analysis shows that our method not only keeps prior knowledge within LLM, but also mitigates hallucination and generates faithful answers.
Internal and External Knowledge Interactive Refinement Framework for Knowledge-Intensive Question Answering
Aug 23, 2024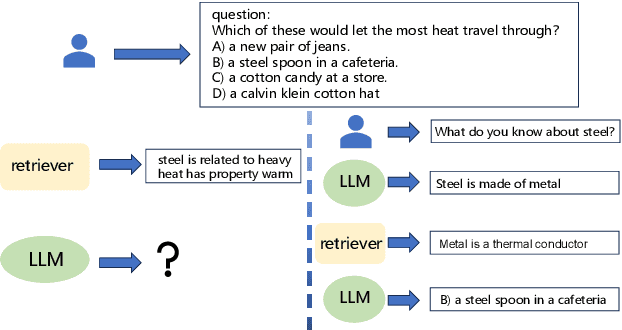
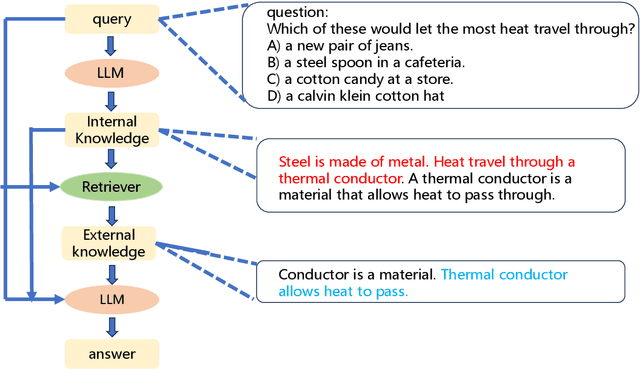


Recent works have attempted to integrate external knowledge into LLMs to address the limitations and potential factual errors in LLM-generated content. However, how to retrieve the correct knowledge from the large amount of external knowledge imposes a challenge. To this end, we empirically observe that LLMs have already encoded rich knowledge in their pretrained parameters and utilizing these internal knowledge improves the retrieval of external knowledge when applying them to knowledge-intensive tasks. In this paper, we propose a new internal and external knowledge interactive refinement paradigm dubbed IEKR to utilize internal knowledge in LLM to help retrieve relevant knowledge from the external knowledge base, as well as exploit the external knowledge to refine the hallucination of generated internal knowledge. By simply adding a prompt like 'Tell me something about' to the LLMs, we try to review related explicit knowledge and insert them with the query into the retriever for external retrieval. The external knowledge is utilized to complement the internal knowledge into input of LLM for answers. We conduct experiments on 3 benchmark datasets in knowledge-intensive question answering task with different LLMs and domains, achieving the new state-of-the-art. Further analysis shows the effectiveness of different modules in our approach.
In-Context Learning with Reinforcement Learning for Incomplete Utterance Rewriting
Aug 23, 2024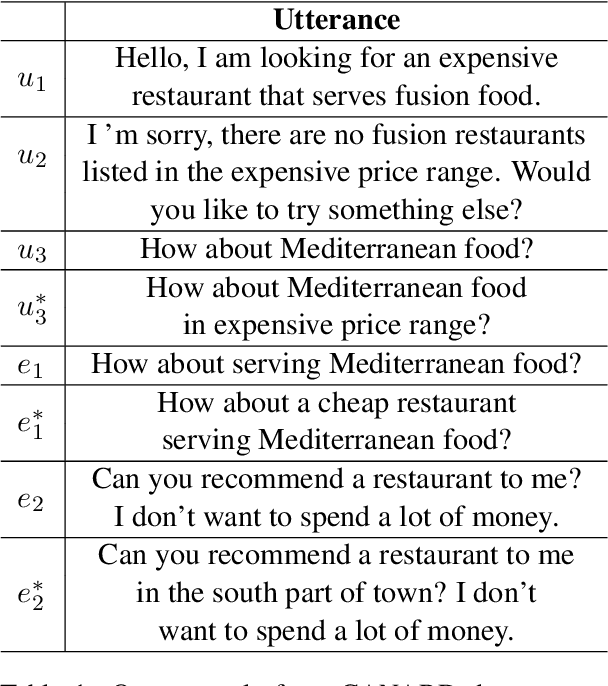
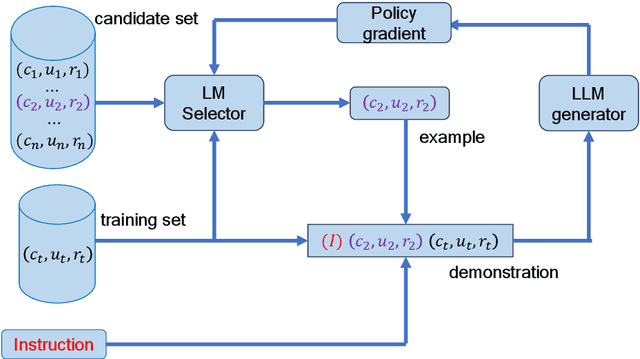
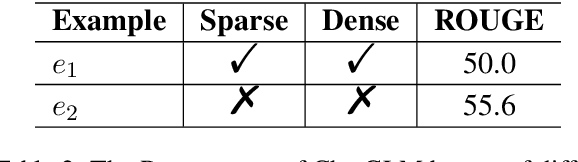

In-context learning (ICL) of large language models (LLMs) has attracted increasing attention in the community where LLMs make predictions only based on instructions augmented with a few examples. Existing example selection methods for ICL utilize sparse or dense retrievers and derive effective performance. However, these methods do not utilize direct feedback of LLM to train the retriever and the examples selected can not necessarily improve the analogy ability of LLM. To tackle this, we propose our policy-based reinforcement learning framework for example selection (RLS), which consists of a language model (LM) selector and an LLM generator. The LM selector encodes the candidate examples into dense representations and selects the top-k examples into the demonstration for LLM. The outputs of LLM are adopted to compute the reward and policy gradient to optimize the LM selector. We conduct experiments on different datasets and significantly outperform existing example selection methods. Moreover, our approach shows advantages over supervised finetuning (SFT) models in few shot setting. Further experiments show the balance of abundance and the similarity with the test case of examples is important for ICL performance of LLM.
Multi-Granularity Information Interaction Framework for Incomplete Utterance Rewriting
Dec 19, 2023Recent approaches in Incomplete Utterance Rewriting (IUR) fail to capture the source of important words, which is crucial to edit the incomplete utterance, and introduce words from irrelevant utterances. We propose a novel and effective multi-task information interaction framework including context selection, edit matrix construction, and relevance merging to capture the multi-granularity of semantic information. Benefiting from fetching the relevant utterance and figuring out the important words, our approach outperforms existing state-of-the-art models on two benchmark datasets Restoration-200K and CANAND in this field. Code will be provided on \url{https://github.com/yanmenxue/QR}.
Relation-Aware Question Answering for Heterogeneous Knowledge Graphs
Dec 19, 2023Multi-hop Knowledge Base Question Answering(KBQA) aims to find the answer entity in a knowledge graph (KG), which requires multiple steps of reasoning. Existing retrieval-based approaches solve this task by concentrating on the specific relation at different hops and predicting the intermediate entity within the reasoning path. During the reasoning process of these methods, the representation of relations are fixed but the initial relation representation may not be optimal. We claim they fail to utilize information from head-tail entities and the semantic connection between relations to enhance the current relation representation, which undermines the ability to capture information of relations in KGs. To address this issue, we construct a \textbf{dual relation graph} where each node denotes a relation in the original KG (\textbf{primal entity graph}) and edges are constructed between relations sharing same head or tail entities. Then we iteratively do primal entity graph reasoning, dual relation graph information propagation, and interaction between these two graphs. In this way, the interaction between entity and relation is enhanced, and we derive better entity and relation representations. Experiments on two public datasets, WebQSP and CWQ, show that our approach achieves a significant performance gain over the prior state-of-the-art. Our code is available on \url{https://github.com/yanmenxue/RAH-KBQA}.
Cross-Lingual Question Answering over Knowledge Base as Reading Comprehension
Feb 26, 2023



Although many large-scale knowledge bases (KBs) claim to contain multilingual information, their support for many non-English languages is often incomplete. This incompleteness gives birth to the task of cross-lingual question answering over knowledge base (xKBQA), which aims to answer questions in languages different from that of the provided KB. One of the major challenges facing xKBQA is the high cost of data annotation, leading to limited resources available for further exploration. Another challenge is mapping KB schemas and natural language expressions in the questions under cross-lingual settings. In this paper, we propose a novel approach for xKBQA in a reading comprehension paradigm. We convert KB subgraphs into passages to narrow the gap between KB schemas and questions, which enables our model to benefit from recent advances in multilingual pre-trained language models (MPLMs) and cross-lingual machine reading comprehension (xMRC). Specifically, we use MPLMs, with considerable knowledge of cross-lingual mappings, for cross-lingual reading comprehension. Existing high-quality xMRC datasets can be further utilized to finetune our model, greatly alleviating the data scarcity issue in xKBQA. Extensive experiments on two xKBQA datasets in 12 languages show that our approach outperforms various baselines and achieves strong few-shot and zero-shot performance. Our dataset and code are released for further research.
Knowledge-enhanced Iterative Instruction Generation and Reasoning for Knowledge Base Question Answering
Sep 07, 2022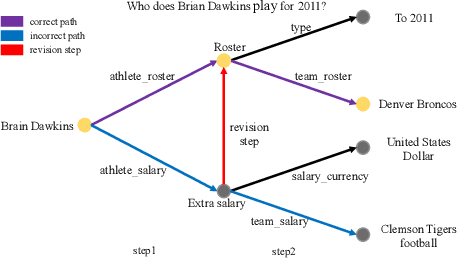
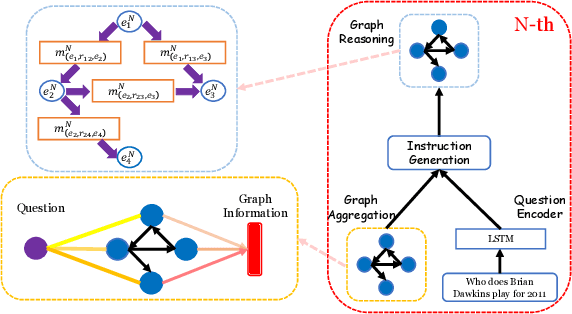
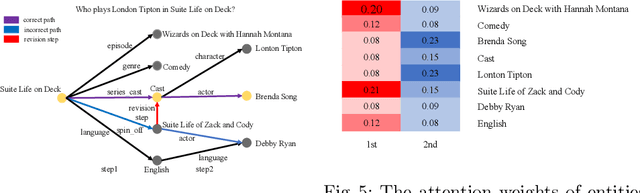
Multi-hop Knowledge Base Question Answering(KBQA) aims to find the answer entity in a knowledge base which is several hops from the topic entity mentioned in the question. Existing Retrieval-based approaches first generate instructions from the question and then use them to guide the multi-hop reasoning on the knowledge graph. As the instructions are fixed during the whole reasoning procedure and the knowledge graph is not considered in instruction generation, the model cannot revise its mistake once it predicts an intermediate entity incorrectly. To handle this, we propose KBIGER(Knowledge Base Iterative Instruction GEnerating and Reasoning), a novel and efficient approach to generate the instructions dynamically with the help of reasoning graph. Instead of generating all the instructions before reasoning, we take the (k-1)-th reasoning graph into consideration to build the k-th instruction. In this way, the model could check the prediction from the graph and generate new instructions to revise the incorrect prediction of intermediate entities. We do experiments on two multi-hop KBQA benchmarks and outperform the existing approaches, becoming the new-state-of-the-art. Further experiments show our method does detect the incorrect prediction of intermediate entities and has the ability to revise such errors.