 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning with Reinforcement Learning for Incomplete Utterance Rewriting
Paper and Code
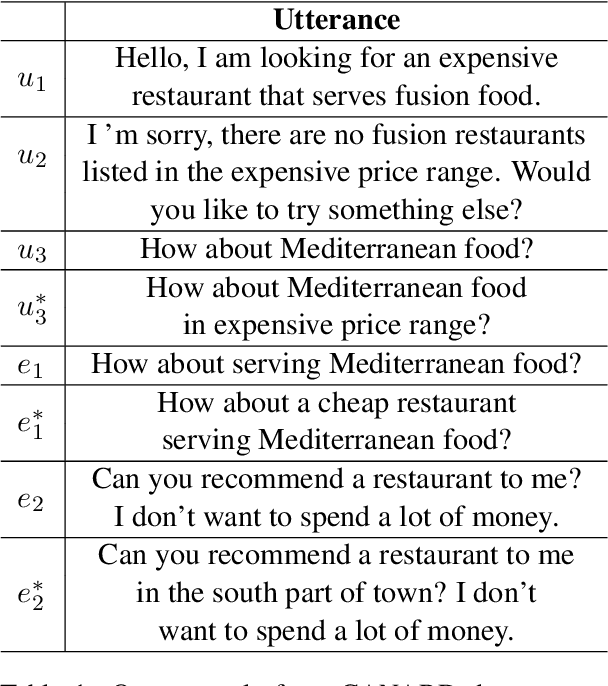
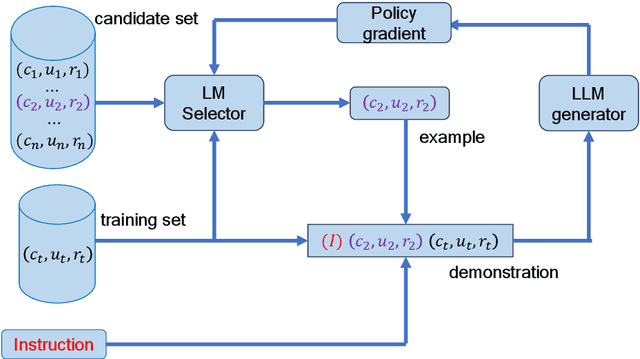
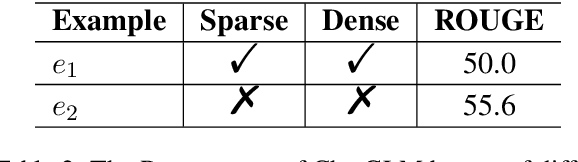

In-context learning (ICL) of large language models (LLMs) has attracted increasing attention in the community where LLMs make predictions only based on instructions augmented with a few examples. Existing example selection methods for ICL utilize sparse or dense retrievers and derive effective performance. However, these methods do not utilize direct feedback of LLM to train the retriever and the examples selected can not necessarily improve the analogy ability of LLM. To tackle this, we propose our policy-based reinforcement learning framework for example selection (RLS), which consists of a language model (LM) selector and an LLM generator. The LM selector encodes the candidate examples into dense representations and selects the top-k examples into the demonstration for LLM. The outputs of LLM are adopted to compute the reward and policy gradient to optimize the LM selector. We conduct experiments on different datasets and significantly outperform existing example selection methods. Moreover, our approach shows advantages over supervised finetuning (SFT) models in few shot setting. Further experiments show the balance of abundance and the similarity with the test case of examples is important for ICL performance of LLM.