 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruct Large Language Models to Generate Scientific Literature Survey Step by Step
Aug 15, 2024Abstract. Automatically generating scientific literature surveys is a valuable task that can significantly enhance research efficiency. However, the diverse and complex nature of information within a literature survey poses substantial challenges for generative models. In this paper, we design a series of prompts to systematically leverage large language models (LLMs), enabling the creation of comprehensive literature surveys through a step-by-step approach. Specifically, we design prompts to guide LLMs to sequentially generate the title, abstract, hierarchical headings, and the main content of the literature survey. We argue that this design enables the generation of the headings from a high-level perspective. During the content generation process, this design effectively harnesses relevant information while minimizing costs by restricting the length of both input and output content in LLM queries. Our implementation with Qwen-long achieved third place in the NLPCC 2024 Scientific Literature Survey Generation evaluation task, with an overall score only 0.03% lower than the second-place team. Additionally, our soft heading recall is 95.84%, the second best among the submissions. Thanks to the efficient prompt design and the low cost of the Qwen-long API, our method reduces the expense for generating each literature survey to 0.1 RMB, enhancing the practical value of our method.
Chain of Condition: Construct, Verify and Solve Conditions for Conditional Question Answering
Aug 10, 2024Conditional question answering (CQA) is an important task that aims to find probable answers and identify conditions that need to be satisfied to support the answer. Existing approaches struggle with CQA due to two main challenges: (1) precisely identifying conditions and their logical relationship, and (2) verifying and solving the conditions. To address these challenges, we propose Chain of Condition, a novel prompting approach by firstly identifying all conditions and constructing their logical relationships explicitly according to the document, then verifying whether these conditions are satisfied, finally solving the logical expression by tools to indicate any missing conditions and generating the answer based on the resolved conditions. The experiments on two benchmark conditional question answering datasets shows chain of condition outperforms existing prompting baselines, establishing a new state-of-the-art. Furthermore, with backbone models like GPT-3.5-Turbo or GPT-4, it surpasses all supervised baselines with only few-shot settings.
Teaching Text-to-Image Models to Communicate
Sep 27, 2023Various works have been extensively studied in the research of text-to-image generation. Although existing models perform well in text-to-image generation, there are significant challenges when directly employing them to generate images in dialogs. In this paper, we first highlight a new problem: dialog-to-image generation, that is, given the dialog context, the model should generate a realistic image which is consistent with the specified conversation as response. To tackle the problem, we propose an efficient approach for dialog-to-image generation without any intermediate translation, which maximizes the extraction of the semantic information contained in the dialog. Considering the characteristics of dialog structure, we put segment token before each sentence in a turn of a dialog to differentiate different speakers. Then, we fine-tune pre-trained text-to-image models to enable them to generate images conditioning on processed dialog context. After fine-tuning, our approach can consistently improve the performance of various models across multiple metrics. Experimental results on public benchmark demonstrate the effectiveness and practicability of our method.
Improving the Generalization Ability in Essay Coherence Evaluation through Monotonic Constraints
Jul 25, 2023Coherence is a crucial aspect of evaluating text readability and can be assessed through two primary factors when evaluating an essay in a scoring scenario. The first factor is logical coherence, characterized by the appropriate use of discourse connectives and the establishment of logical relationships between sentences. The second factor is the appropriateness of punctuation, as inappropriate punctuation can lead to confused sentence structure. To address these concerns, we propose a coherence scoring model consisting of a regression model with two feature extractors: a local coherence discriminative model and a punctuation correction model. We employ gradient-boosting regression trees as the regression model and impose monotonicity constraints on the input features. The results show that our proposed model better generalizes unseen data. The model achieved third place in track 1 of NLPCC 2023 shared task 7. Additionally, we briefly introduce our solution for the remaining tracks, which achieves second place for track 2 and first place for both track 3 and track 4.
How Many Answers Should I Give? An Empirical Study of Multi-Answer Reading Comprehension
Jun 01, 2023The multi-answer phenomenon, where a question may have multiple answers scattered in the document, can be well handled by humans but is challenging enough for machine reading comprehension (MRC) systems. Despite recent progress in multi-answer MRC, there lacks a systematic analysis of how this phenomenon arises and how to better address it. In this work, we design a taxonomy to categorize commonly-seen multi-answer MRC instances, with which we inspect three multi-answer datasets and analyze where the multi-answer challenge comes from. We further analyze how well different paradigms of current multi-answer MRC models deal with different types of multi-answer instances. We find that some paradigms capture well the key information in the questions while others better model the relationship between questions and contexts. We thus explore strategies to make the best of the strengths of different paradigms. Experiments show that generation models can be a promising platform to incorporate different paradigms. Our annotations and code are released for further research.
Cross-Lingual Question Answering over Knowledge Base as Reading Comprehension
Feb 26, 2023



Although many large-scale knowledge bases (KBs) claim to contain multilingual information, their support for many non-English languages is often incomplete. This incompleteness gives birth to the task of cross-lingual question answering over knowledge base (xKBQA), which aims to answer questions in languages different from that of the provided KB. One of the major challenges facing xKBQA is the high cost of data annotation, leading to limited resources available for further exploration. Another challenge is mapping KB schemas and natural language expressions in the questions under cross-lingual settings. In this paper, we propose a novel approach for xKBQA in a reading comprehension paradigm. We convert KB subgraphs into passages to narrow the gap between KB schemas and questions, which enables our model to benefit from recent advances in multilingual pre-trained language models (MPLMs) and cross-lingual machine reading comprehension (xMRC). Specifically, we use MPLMs, with considerable knowledge of cross-lingual mappings, for cross-lingual reading comprehension. Existing high-quality xMRC datasets can be further utilized to finetune our model, greatly alleviating the data scarcity issue in xKBQA. Extensive experiments on two xKBQA datasets in 12 languages show that our approach outperforms various baselines and achieves strong few-shot and zero-shot performance. Our dataset and code are released for further research.
Event Transition Planning for Open-ended Text Generation
Apr 20, 2022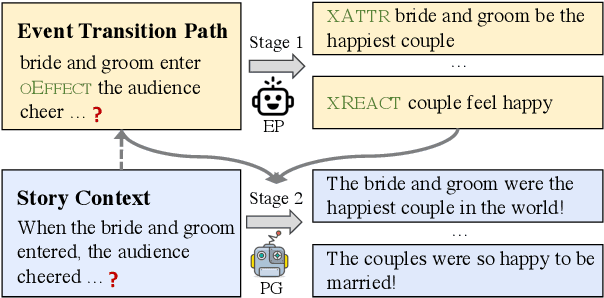

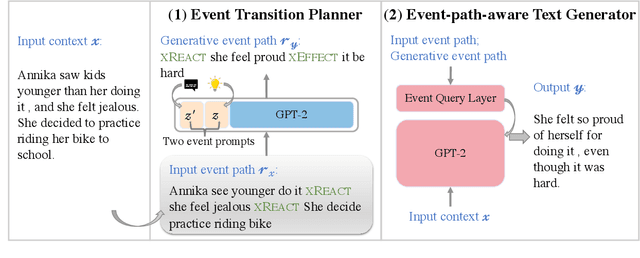
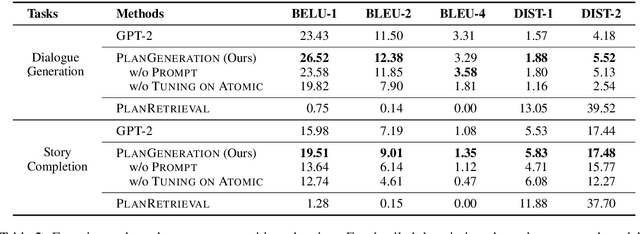
Open-ended text generation tasks, such as dialogue generation and story completion, require models to generate a coherent continuation given limited preceding context. The open-ended nature of these tasks brings new challenges to the neural auto-regressive text generators nowadays. Despite these neural models are good at producing human-like text, it is difficult for them to arrange causalities and relations between given facts and possible ensuing events. To bridge this gap, we propose a novel two-stage method which explicitly arranges the ensuing events in open-ended text generation. Our approach can be understood as a specially-trained coarse-to-fine algorithm, where an event transition planner provides a "coarse" plot skeleton and a text generator in the second stage refines the skeleton. Experiments on two open-ended text generation tasks demonstrate that our proposed method effectively improves the quality of the generated text, especially in coherence and diversity. The code is available at: \url{https://github.com/qtli/EventPlanforTextGen}.
Extract, Integrate, Compete: Towards Verification Style Reading Comprehension
Sep 11, 2021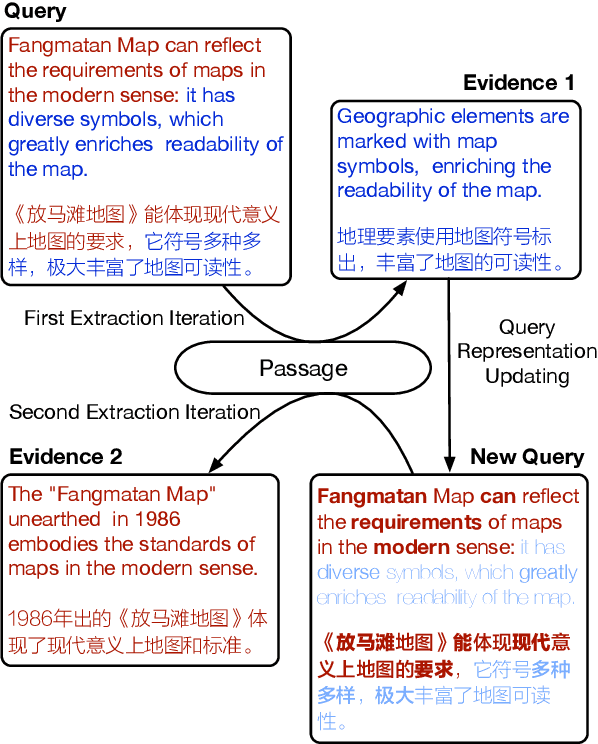

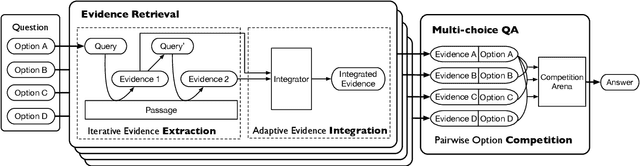
In this paper, we present a new verification style reading comprehension dataset named VGaokao from Chinese Language tests of Gaokao. Different from existing efforts, the new dataset is originally designed for native speakers' evaluation, thus requiring more advanced language understanding skills. To address the challenges in VGaokao, we propose a novel Extract-Integrate-Compete approach, which iteratively selects complementary evidence with a novel query updating mechanism and adaptively distills supportive evidence, followed by a pairwise competition to push models to learn the subtle difference among similar text pieces. Experiments show that our methods outperform various baselines on VGaokao with retrieved complementary evidence, while having the merits of efficiency and explainability. Our dataset and code are released for further research.
Three Sentences Are All You Need: Local Path Enhanced Document Relation Extraction
Jun 03, 2021
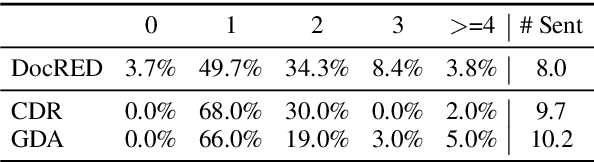
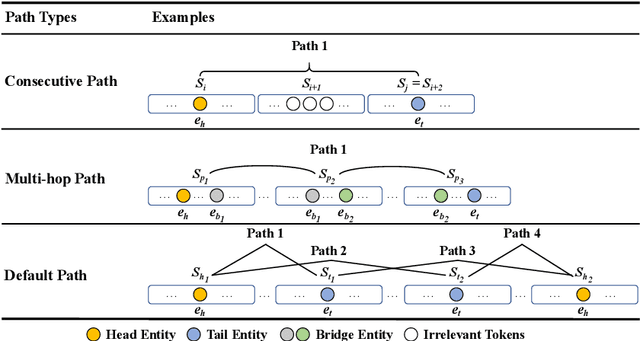
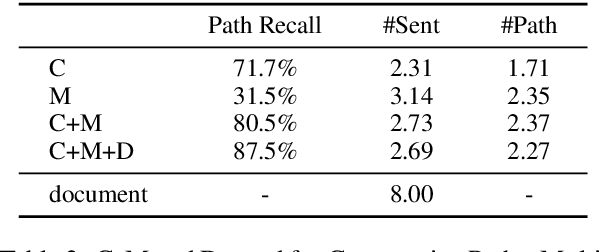
Document-level Relation Extraction (RE) is a more challenging task than sentence RE as it often requires reasoning over multiple sentences. Yet, human annotators usually use a small number of sentences to identify the relationship between a given entity pair. In this paper, we present an embarrassingly simple but effective method to heuristically select evidence sentences for document-level RE, which can be easily combined with BiLSTM to achieve good performance on benchmark datasets, even better than fancy graph neural network based methods. We have released our code at https://github.com/AndrewZhe/Three-Sentences-Are-All-You-Need.
Why Machine Reading Comprehension Models Learn Shortcuts?
Jun 02, 2021
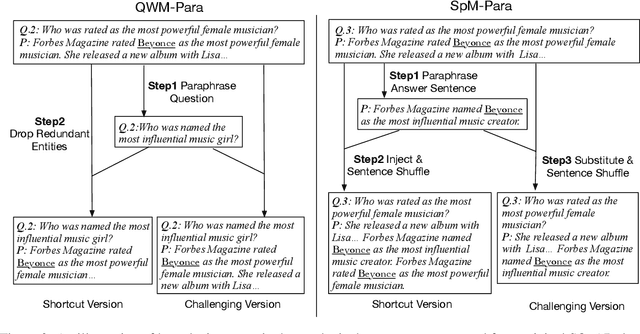

Recent studies report that many machine reading comprehension (MRC) models can perform closely to or even better than humans on benchmark datasets. However, existing works indicate that many MRC models may learn shortcuts to outwit these benchmarks, but the performance is unsatisfactory in real-world applications. In this work, we attempt to explore, instead of the expected comprehension skills, why these models learn the shortcuts. Based on the observation that a large portion of questions in current datasets have shortcut solutions, we argue that larger proportion of shortcut questions in training data make models rely on shortcut tricks excessively. To investigate this hypothesis, we carefully design two synthetic datasets with annotations that indicate whether a question can be answered using shortcut solutions. We further propose two new methods to quantitatively analyze the learning difficulty regarding shortcut and challenging questions, and revealing the inherent learning mechanism behind the different performance between the two kinds of questions. A thorough empirical analysis shows that MRC models tend to learn shortcut questions earlier than challenging questions, and the high proportions of shortcut questions in training sets hinder models from exploring the sophisticated reasoning skills in the later stage of training.