 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifier-Backed Hard Problem Generation for Mathematical Reasoning
May 07, 2026Large Language Models (LLMs) demonstrate strong capabilities for solving scientific and mathematical problems, yet they struggle to produce valid, challenging, and novel problems - an essential component for advancing LLM training and enabling autonomous scientific research. Existing problem generation approaches either depend on expensive human expert involvement or adopt naive self-play paradigms, which frequently yield invalid problems due to reward hacking. This work introduces VHG, a verifier-enhanced hard problem generation framework built upon three-party self-play. By integrating an independent verifier into the conventional setter-solver duality, our design constrains the setter's reward to be jointly determined by problem validity (evaluated by the verifier) and difficulty (assessed by the solver). We instantiate two verifier variants: a Hard symbolic verifier and a Soft LLM-based verifier, with evaluations conducted on indefinite integral tasks and general mathematical reasoning tasks. Experimental results show that VHG substantially outperforms all baseline methods by a clear margin.
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
Apr 20, 2026Large language models are increasingly expected to serve as general-purpose agents that interact with external, stateful tool environments. The Model Context Protocol (MCP) and broader agent skills offer a unified interface for connecting agents with scalable real-world services, but training robust agents remains limited by the lack of realistic environments and principled mechanisms for life-long learning. In this paper, we present \textbf{Agent-World}, a self-evolving training arena for advancing general agent intelligence through scalable environments. Agent-World has two main components: (1) Agentic Environment-Task Discovery, which autonomously explores topic-aligned databases and executable tool ecosystems from thousands of real-world environment themes and synthesizes verifiable tasks with controllable difficulty; and (2) Continuous Self-Evolving Agent Training, which combines multi-environment reinforcement learning with a self-evolving agent arena that automatically identifies capability gaps through dynamic task synthesis and drives targeted learning, enabling the co-evolution of agent policies and environments. Across 23 challenging agent benchmarks, Agent-World-8B and 14B consistently outperforms strong proprietary models and environment scaling baselines. Further analyses reveal scaling trends in relation to environment diversity and self-evolution rounds, offering insights for building general agent intelligence.
AdaCtrl: Towards Adaptive and Controllable Reasoning via Difficulty-Aware Budgeting
May 24, 2025Modern large reasoning models demonstrate impressive problem-solving capabilities by employing sophisticated reasoning strategies. However, they often struggle to balance efficiency and effectiveness, frequently generating unnecessarily lengthy reasoning chains for simple problems. In this work, we propose AdaCtrl, a novel framework to support both difficulty-aware adaptive reasoning budget allocation and explicit user control over reasoning depth. AdaCtrl dynamically adjusts its reasoning length based on self-assessed problem difficulty, while also allowing users to manually control the budget to prioritize either efficiency or effectiveness. This is achieved through a two-stage training pipeline: an initial cold-start fine-tuning phase to instill the ability to self-aware difficulty and adjust reasoning budget, followed by a difficulty-aware reinforcement learning (RL) stage that refines the model's adaptive reasoning strategies and calibrates its difficulty assessments based on its evolving capabilities during online training. To enable intuitive user interaction, we design explicit length-triggered tags that function as a natural interface for budget control. Empirical results show that AdaCtrl adapts reasoning length based on estimated difficulty, compared to the standard training baseline that also incorporates fine-tuning and RL, it yields performance improvements and simultaneously reduces response length by 10.06% and 12.14% on the more challenging AIME2024 and AIME2025 datasets, which require elaborate reasoning, and by 62.05% and 91.04% on the MATH500 and GSM8K datasets, where more concise responses are sufficient. Furthermore, AdaCtrl enables precise user control over the reasoning budget, allowing for tailored responses to meet specific needs.
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Apr 15, 2025While reasoning models (e.g., DeepSeek R1) trained with reinforcement learning (RL), excel in textual reasoning, they struggle in scenarios requiring structured problem-solving, such as geometric reasoning, concise computation, or complex equation solving-areas where computational tools like code interpreters (CI) demonstrate distinct advantages. To bridge this gap, we propose ReTool, which enhances long-form reasoning with tool-integrated learning, including two key features: (1) dynamic interleaving of real-time code execution within natural language reasoning processes, and (2) an automated RL paradigm that allows policy rollouts with multi-turn real-time code execution and teaches the model in learning when and how to invoke tools based on outcome feedback. ReTool employs a systematic training framework, beginning with synthetic cold-start data generation to produce code-augmented long-form reasoning traces for fine-tuning base models. Subsequent RL training leverages task outcomes as rewards to iteratively refine the model's tool use strategy, enabling autonomous discovery of optimal tool invocation patterns without human priors. Experiments on the challenging MATH Olympiad benchmark AIME demonstrate ReTool's superiority: Our 32B model achieves 67% accuracy with 400 training steps, outperforming text-based RL baseline (40% accuracy, 1080 steps) in efficiency and performance. Remarkably, ReTool-32B attains 72.5% accuracy in extended settings, surpassing OpenAI's o1-preview by 27.9%. Further analysis reveals emergent behaviors such as code self-correction, signaling an ''aha moment'' in which the model autonomously masters adaptive tool use. These findings highlight the promise of outcome-driven tool integration for advancing complex mathematical reasoning and offer new insights into hybrid neuro-symbolic systems.
A Step Closer to Comprehensive Answers: Constrained Multi-Stage Question Decomposition with Large Language Models
Nov 13, 2023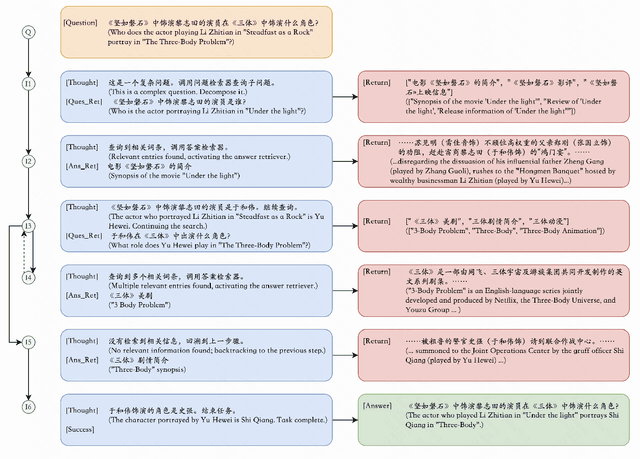
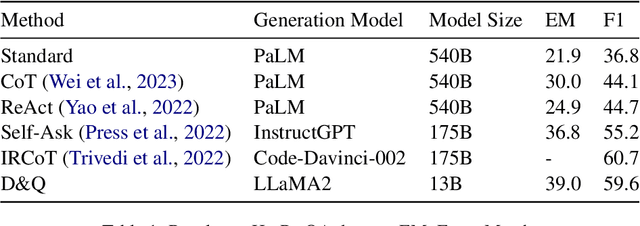
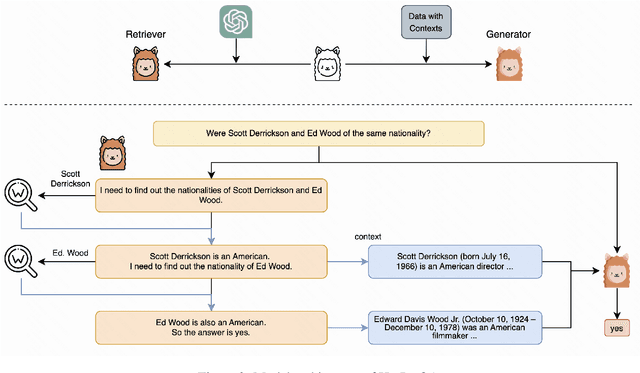

While large language models exhibit remarkable performance in the Question Answering task, they are susceptible to hallucinations. Challenges arise when these models grapple with understanding multi-hop relations in complex questions or lack the necessary knowledge for a comprehensive response. To address this issue, we introduce the "Decompose-and-Query" framework (D&Q). This framework guides the model to think and utilize external knowledge similar to ReAct, while also restricting its thinking to reliable information, effectively mitigating the risk of hallucinations. Experiments confirm the effectiveness of D&Q: On our ChitChatQA dataset, D&Q does not lose to ChatGPT in 67% of cases; on the HotPotQA question-only setting, D&Q achieved an F1 score of 59.6%. Our code is available at https://github.com/alkaidpku/DQ-ToolQA.
Language Models can be Logical Solvers
Nov 10, 2023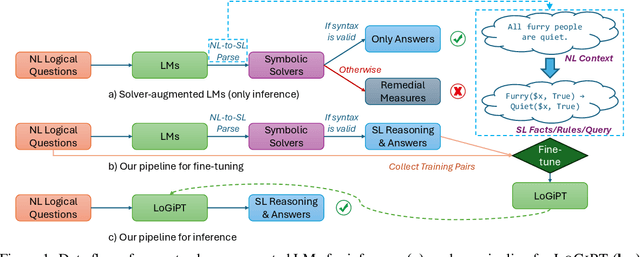
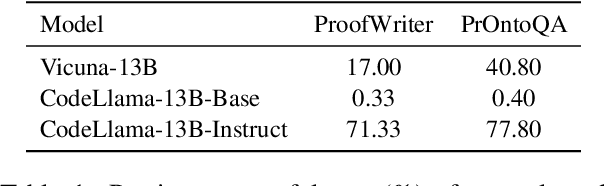
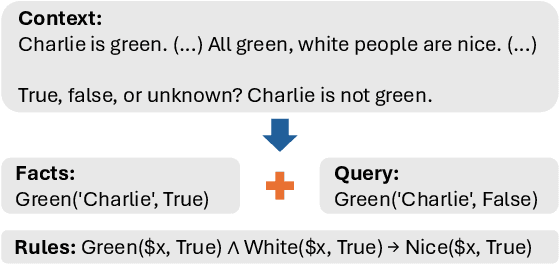
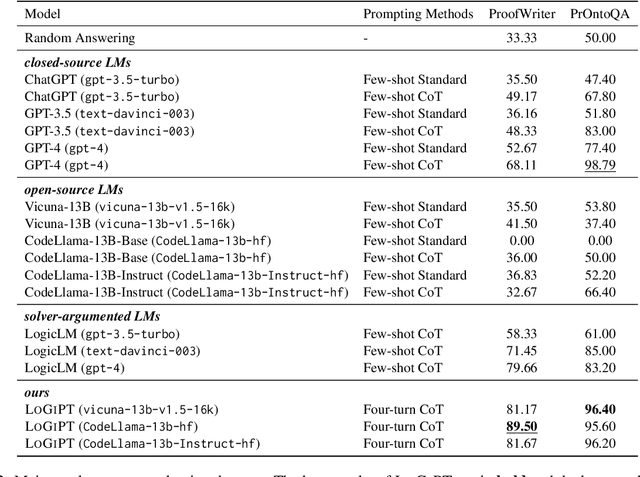
Logical reasoning is a fundamental aspect of human intelligence and a key component of tasks like problem-solving and decision-making. Recent advancements have enabled Large Language Models (LLMs) to potentially exhibit reasoning capabilities, but complex logical reasoning remains a challenge. The state-of-the-art, solver-augmented language models, use LLMs to parse natural language logical questions into symbolic representations first and then adopt external logical solvers to take in the symbolic representations and output the answers. Despite their impressive performance, any parsing errors will inevitably result in the failure of the execution of the external logical solver and no answer to the logical questions. In this paper, we introduce LoGiPT, a novel language model that directly emulates the reasoning processes of logical solvers and bypasses the parsing errors by learning to strict adherence to solver syntax and grammar. LoGiPT is fine-tuned on a newly constructed instruction-tuning dataset derived from revealing and refining the invisible reasoning process of deductive solvers. Experimental results on two public deductive reasoning datasets demonstrate that LoGiPT outperforms state-of-the-art solver-augmented LMs and few-shot prompting methods on competitive LLMs like ChatGPT or GPT-4.
Teaching Text-to-Image Models to Communicate
Sep 27, 2023Various works have been extensively studied in the research of text-to-image generation. Although existing models perform well in text-to-image generation, there are significant challenges when directly employing them to generate images in dialogs. In this paper, we first highlight a new problem: dialog-to-image generation, that is, given the dialog context, the model should generate a realistic image which is consistent with the specified conversation as response. To tackle the problem, we propose an efficient approach for dialog-to-image generation without any intermediate translation, which maximizes the extraction of the semantic information contained in the dialog. Considering the characteristics of dialog structure, we put segment token before each sentence in a turn of a dialog to differentiate different speakers. Then, we fine-tune pre-trained text-to-image models to enable them to generate images conditioning on processed dialog context. After fine-tuning, our approach can consistently improve the performance of various models across multiple metrics. Experimental results on public benchmark demonstrate the effectiveness and practicability of our method.
Knowledge Refinement via Interaction Between Search Engines and Large Language Models
May 21, 2023



Information retrieval (IR) plays a crucial role in locating relevant resources from vast amounts of data, and its applications have evolved from traditional knowledge bases to modern search engines (SEs). The emergence of large language models (LLMs) has further revolutionized the IR field by enabling users to interact with search systems in natural language. In this paper, we explore the advantages and disadvantages of LLMs and SEs, highlighting their respective strengths in understanding user-issued queries and retrieving up-to-date information. To leverage the benefits of both paradigms while circumventing their limitations, we propose InteR, a novel framework that facilitates knowledge refinement through interaction between SEs and LLMs. InteR allows SEs to expand knowledge in queries using LLM-generated knowledge collections and enables LLMs to enhance prompt formulation using SE-retrieved documents. This iterative refinement process augments the inputs of SEs and LLMs, leading to more accurate retrieval. Experiments on large-scale retrieval benchmarks involving web search and low-resource retrieval tasks demonstrate that InteR achieves overall superior zero-shot retrieval performance compared to state-of-the-art methods, even those using relevance judgment. Source code is available at https://github.com/Cyril-JZ/InteR
WizardLM: Empowering Large Language Models to Follow Complex Instructions
Apr 24, 2023



Training large language models (LLM) with open-domain instruction following data brings colossal success. However, manually creating such instruction data is very time-consuming and labor-intensive. Moreover, humans may struggle to produce high-complexity instructions. In this paper, we show an avenue for creating large amounts of instruction data with varying levels of complexity using LLM instead of humans. Starting with an initial set of instructions, we use our proposed Evol-Instruct to rewrite them step by step into more complex instructions. Then, we mix all generated instruction data to fine-tune LLaMA. We call the resulting model WizardLM. Human evaluations on a complexity-balanced test bed show that instructions from Evol-Instruct are superior to human-created ones. By analyzing the human evaluation results of the high complexity part, we demonstrate that outputs from our WizardLM model are preferred to outputs from OpenAI ChatGPT. Even though WizardLM still lags behind ChatGPT in some aspects, our findings suggest that fine-tuning with AI-evolved instructions is a promising direction for enhancing large language models. Our codes and generated data are public at https://github.com/nlpxucan/WizardLM
MMDialog: A Large-scale Multi-turn Dialogue Dataset Towards Multi-modal Open-domain Conversation
Nov 16, 2022
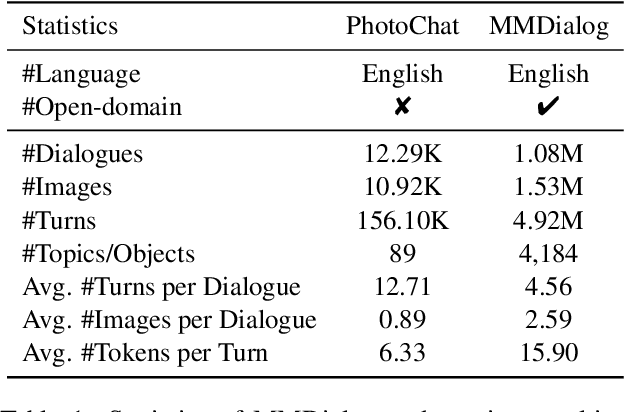
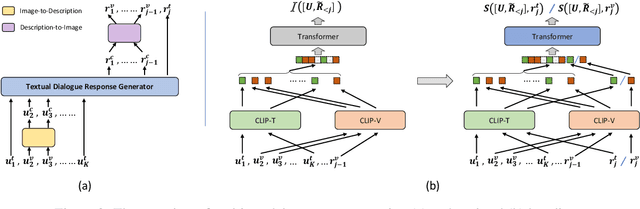
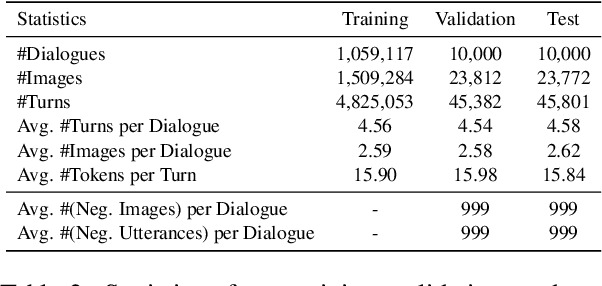
Responding with multi-modal content has been recognized as an essential capability for an intelligent conversational agent. In this paper, we introduce the MMDialog dataset to better facilitate multi-modal conversation. MMDialog is composed of a curated set of 1.08 million real-world dialogues with 1.53 million unique images across 4,184 topics. MMDialog has two main and unique advantages. First, it is the largest multi-modal conversation dataset by the number of dialogues by 88x. Second, it contains massive topics to generalize the open-domain. To build engaging dialogue system with this dataset, we propose and normalize two response producing tasks based on retrieval and generative scenarios. In addition, we build two baselines for above tasks with state-of-the-art techniques and report their experimental performance. We also propose a novel evaluation metric MM-Relevance to measure the multi-modal responses. Our dataset and scripts are available in https://github.com/victorsungo/MMDialog.