 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Safeguards for Safe and Model-Agnostic Reinforcement Learning
Oct 31, 2024In this paper we propose a formal, model-agnostic meta-learning framework for safe reinforcement learning. Our framework is inspired by how parents safeguard their children across a progression of increasingly riskier tasks, imparting a sense of safety that is carried over from task to task. We model this as a meta-learning process where each task is synchronized with a safeguard that monitors safety and provides a reward signal to the agent. The safeguard is implemented as a finite-state machine based on a safety specification; the reward signal is formally shaped around this specification. The safety specification and its corresponding safeguard can be arbitrarily complex and non-Markovian, which adds flexibility to the training process and explainability to the learned policy. The design of the safeguard is manual but it is high-level and model-agnostic, which gives rise to an end-to-end safe learning approach with wide applicability, from pixel-level game control to language model fine-tuning. Starting from a given set of safety specifications (tasks), we train a model such that it can adapt to new specifications using only a small number of training samples. This is made possible by our method for efficiently transferring safety bias between tasks, which effectively minimizes the number of safety violations. We evaluate our framework in a Minecraft-inspired Gridworld, a VizDoom game environment, and an LLM fine-tuning application. Agents trained with our approach achieve near-minimal safety violations, while baselines are shown to underperform.
Phi-3 Safety Post-Training: Aligning Language Models with a "Break-Fix" Cycle
Jul 18, 2024


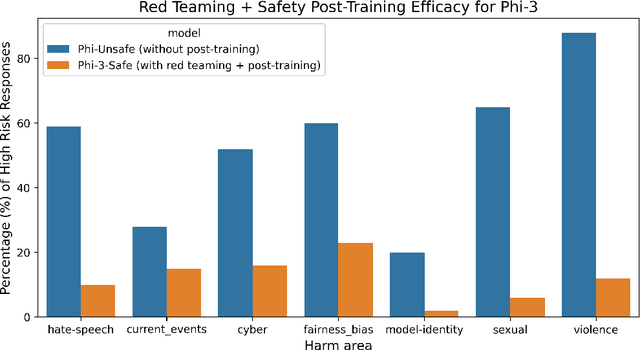
Recent innovations in language model training have demonstrated that it is possible to create highly performant models that are small enough to run on a smartphone. As these models are deployed in an increasing number of domains, it is critical to ensure that they are aligned with human preferences and safety considerations. In this report, we present our methodology for safety aligning the Phi-3 series of language models. We utilized a "break-fix" cycle, performing multiple rounds of dataset curation, safety post-training, benchmarking, red teaming, and vulnerability identification to cover a variety of harm areas in both single and multi-turn scenarios. Our results indicate that this approach iteratively improved the performance of the Phi-3 models across a wide range of responsible AI benchmarks.
Cost-Effective Proxy Reward Model Construction with On-Policy and Active Learning
Jul 02, 2024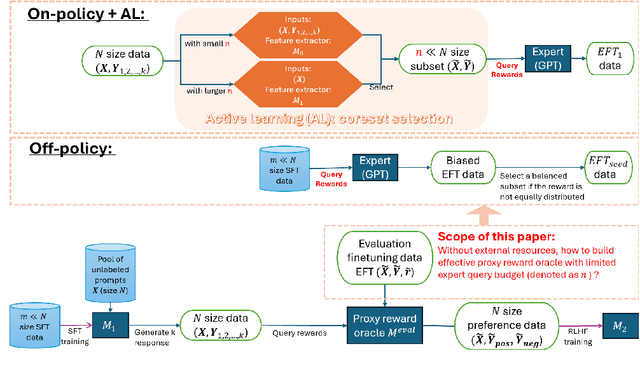
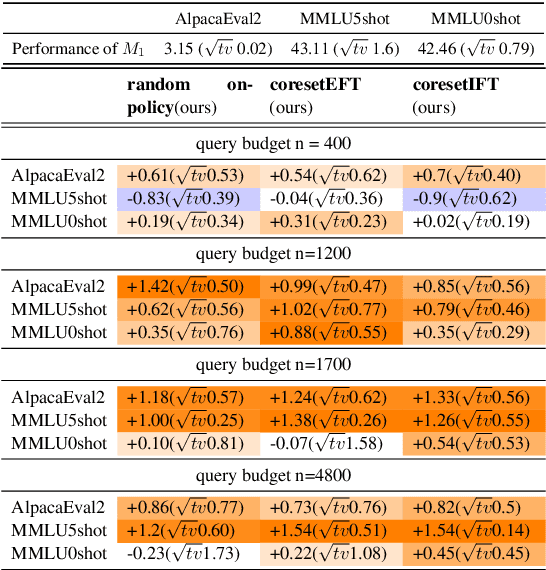

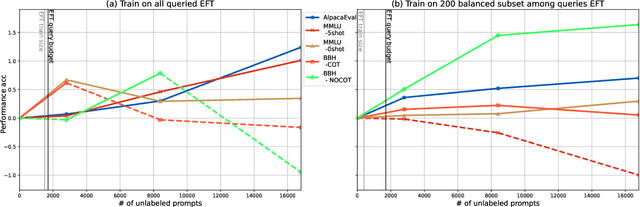
Reinforcement learning with human feedback (RLHF), as a widely adopted approach in current large language model pipelines, is \textit{bottlenecked by the size of human preference data}. While traditional methods rely on offline preference dataset constructions, recent approaches have shifted towards online settings, where a learner uses a small amount of labeled seed data and a large pool of unlabeled prompts to iteratively construct new preference data through self-generated responses and high-quality reward/preference feedback. However, most current online algorithms still focus on preference labeling during policy model updating with given feedback oracles, which incurs significant expert query costs. \textit{We are the first to explore cost-effective proxy reward oracles construction strategies for further labeling preferences or rewards with extremely limited labeled data and expert query budgets}. Our approach introduces two key innovations: (1) on-policy query to avoid OOD and imbalance issues in seed data, and (2) active learning to select the most informative data for preference queries. Using these methods, we train a evaluation model with minimal expert-labeled data, which then effectively labels nine times more preference pairs for further RLHF training. For instance, our model using Direct Preference Optimization (DPO) gains around over 1% average improvement on AlpacaEval2, MMLU-5shot and MMLU-0shot, with only 1.7K query cost. Our methodology is orthogonal to other direct expert query-based strategies and therefore might be integrated with them to further reduce query costs.
Self-Exploring Language Models: Active Preference Elicitation for Online Alignment
May 29, 2024



Preference optimization, particularly through Reinforcement Learning from Human Feedback (RLHF), has achieved significant success in aligning Large Language Models (LLMs) to adhere to human intentions. Unlike offline alignment with a fixed dataset, online feedback collection from humans or AI on model generations typically leads to more capable reward models and better-aligned LLMs through an iterative process. However, achieving a globally accurate reward model requires systematic exploration to generate diverse responses that span the vast space of natural language. Random sampling from standard reward-maximizing LLMs alone is insufficient to fulfill this requirement. To address this issue, we propose a bilevel objective optimistically biased towards potentially high-reward responses to actively explore out-of-distribution regions. By solving the inner-level problem with the reparameterized reward function, the resulting algorithm, named Self-Exploring Language Models (SELM), eliminates the need for a separate RM and iteratively updates the LLM with a straightforward objective. Compared to Direct Preference Optimization (DPO), the SELM objective reduces indiscriminate favor of unseen extrapolations and enhances exploration efficiency. Our experimental results demonstrate that when finetuned on Zephyr-7B-SFT and Llama-3-8B-Instruct models, SELM significantly boosts the performance on instruction-following benchmarks such as MT-Bench and AlpacaEval 2.0, as well as various standard academic benchmarks in different settings. Our code and models are available at https://github.com/shenao-zhang/SELM.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Language Models can be Logical Solvers
Nov 10, 2023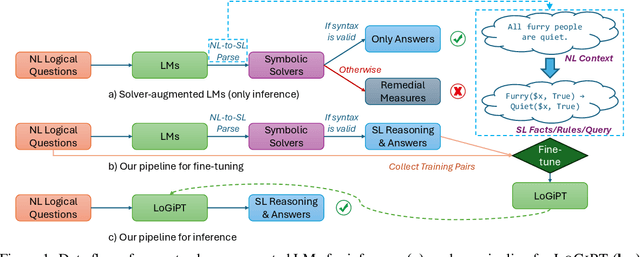
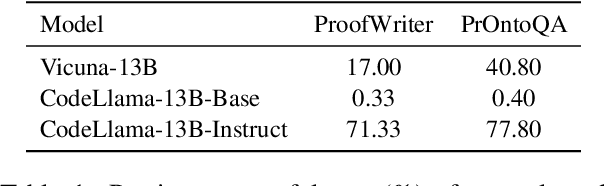
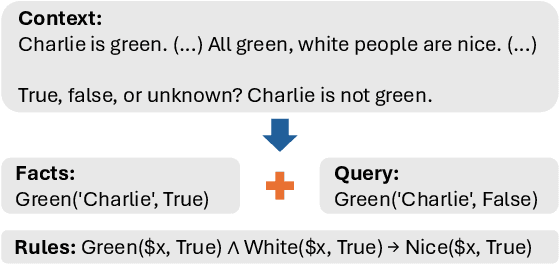
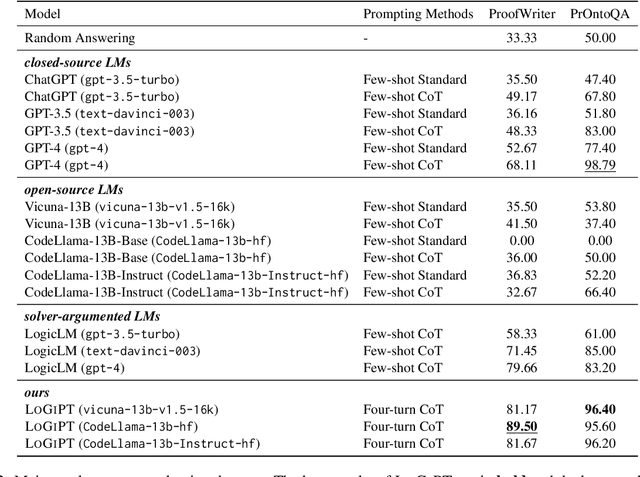
Logical reasoning is a fundamental aspect of human intelligence and a key component of tasks like problem-solving and decision-making. Recent advancements have enabled Large Language Models (LLMs) to potentially exhibit reasoning capabilities, but complex logical reasoning remains a challenge. The state-of-the-art, solver-augmented language models, use LLMs to parse natural language logical questions into symbolic representations first and then adopt external logical solvers to take in the symbolic representations and output the answers. Despite their impressive performance, any parsing errors will inevitably result in the failure of the execution of the external logical solver and no answer to the logical questions. In this paper, we introduce LoGiPT, a novel language model that directly emulates the reasoning processes of logical solvers and bypasses the parsing errors by learning to strict adherence to solver syntax and grammar. LoGiPT is fine-tuned on a newly constructed instruction-tuning dataset derived from revealing and refining the invisible reasoning process of deductive solvers. Experimental results on two public deductive reasoning datasets demonstrate that LoGiPT outperforms state-of-the-art solver-augmented LMs and few-shot prompting methods on competitive LLMs like ChatGPT or GPT-4.
ALLURE: Auditing and Improving LLM-based Evaluation of Text using Iterative In-Context-Learning
Sep 27, 2023



From grading papers to summarizing medical documents, large language models (LLMs) are evermore used for evaluation of text generated by humans and AI alike. However, despite their extensive utility, LLMs exhibit distinct failure modes, necessitating a thorough audit and improvement of their text evaluation capabilities. Here we introduce ALLURE, a systematic approach to Auditing Large Language Models Understanding and Reasoning Errors. ALLURE involves comparing LLM-generated evaluations with annotated data, and iteratively incorporating instances of significant deviation into the evaluator, which leverages in-context learning (ICL) to enhance and improve robust evaluation of text by LLMs. Through this iterative process, we refine the performance of the evaluator LLM, ultimately reducing reliance on human annotators in the evaluation process. We anticipate ALLURE to serve diverse applications of LLMs in various domains related to evaluation of textual data, such as medical summarization, education, and and productivity.
Evaluating Cognitive Maps and Planning in Large Language Models with CogEval
Sep 25, 2023


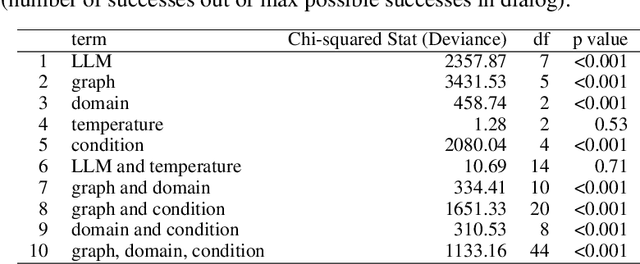
Recently an influx of studies claim emergent cognitive abilities in large language models (LLMs). Yet, most rely on anecdotes, overlook contamination of training sets, or lack systematic Evaluation involving multiple tasks, control conditions, multiple iterations, and statistical robustness tests. Here we make two major contributions. First, we propose CogEval, a cognitive science-inspired protocol for the systematic evaluation of cognitive capacities in Large Language Models. The CogEval protocol can be followed for the evaluation of various abilities. Second, here we follow CogEval to systematically evaluate cognitive maps and planning ability across eight LLMs (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge-52.4B, Anthropic Claude-1-52B, LLaMA-13B, and Alpaca-7B). We base our task prompts on human experiments, which offer both established construct validity for evaluating planning, and are absent from LLM training sets. We find that, while LLMs show apparent competence in a few planning tasks with simpler structures, systematic evaluation reveals striking failure modes in planning tasks, including hallucinations of invalid trajectories and getting trapped in loops. These findings do not support the idea of emergent out-of-the-box planning ability in LLMs. This could be because LLMs do not understand the latent relational structures underlying planning problems, known as cognitive maps, and fail at unrolling goal-directed trajectories based on the underlying structure. Implications for application and future directions are discussed.
Fine-Tuning Language Models with Advantage-Induced Policy Alignment
Jun 06, 2023
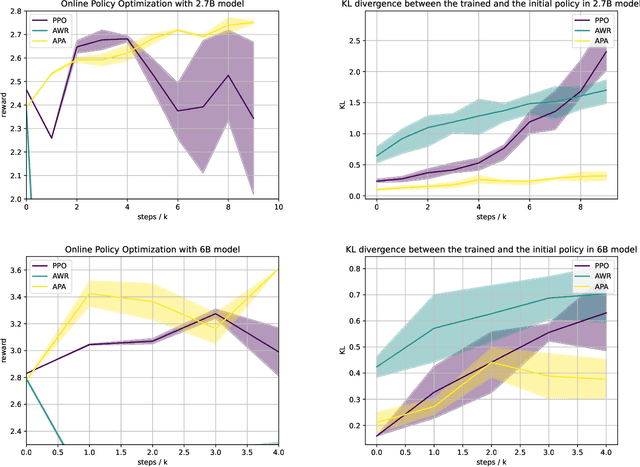
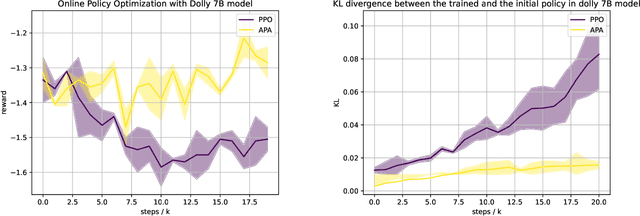
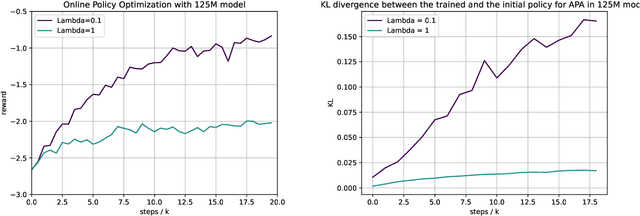
Reinforcement learning from human feedback (RLHF) has emerged as a reliable approach to aligning large language models (LLMs) to human preferences. Among the plethora of RLHF techniques, proximal policy optimization (PPO) is of the most widely used methods. Despite its popularity, however, PPO may suffer from mode collapse, instability, and poor sample efficiency. We show that these issues can be alleviated by a novel algorithm that we refer to as Advantage-Induced Policy Alignment (APA), which leverages a squared error loss function based on the estimated advantages. We demonstrate empirically that APA consistently outperforms PPO in language tasks by a large margin, when a separate reward model is employed as the evaluator. In addition, compared with PPO, APA offers a more stable form of control over the deviation from the model's initial policy, ensuring that the model improves its performance without collapsing to deterministic output. In addition to empirical results, we also provide a theoretical justification supporting the design of our loss function.
Randomized Policy Learning for Continuous State and Action MDPs
Jun 08, 2020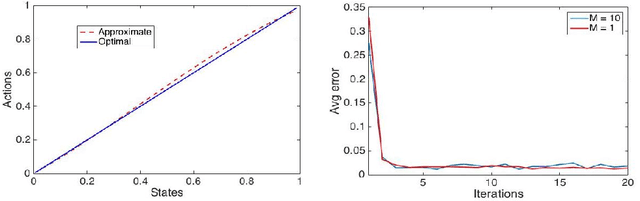

Deep reinforcement learning methods have achieved state-of-the-art results in a variety of challenging, high-dimensional domains ranging from video games to locomotion. The key to success has been the use of deep neural networks used to approximate the policy and value function. Yet, substantial tuning of weights is required for good results. We instead use randomized function approximation. Such networks are not only cheaper than training fully connected networks but also improve the numerical performance. We present \texttt{RANDPOL}, a generalized policy iteration algorithm for MDPs with continuous state and action spaces. Both the policy and value functions are represented with randomized networks. We also give finite time guarantees on the performance of the algorithm. Then we show the numerical performance on challenging environments and compare them with deep neural network based algorithms.