 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Temperature-Centric Investigation of Speculative Decoding with Knowledge Distillation
Oct 14, 2024Speculative decoding stands as a pivotal technique to expedite inference in autoregressive (large) language models. This method employs a smaller draft model to speculate a block of tokens, which the target model then evaluates for acceptance. Despite a wealth of studies aimed at increasing the efficiency of speculative decoding, the influence of generation configurations on the decoding process remains poorly understood, especially concerning decoding temperatures. This paper delves into the effects of decoding temperatures on speculative decoding's efficacy. Beginning with knowledge distillation (KD), we first highlight the challenge of decoding at higher temperatures, and demonstrate KD in a consistent temperature setting could be a remedy. We also investigate the effects of out-of-domain testing sets with out-of-range temperatures. Building upon these findings, we take an initial step to further the speedup for speculative decoding, particularly in a high-temperature generation setting. Our work offers new insights into how generation configurations drastically affect the performance of speculative decoding, and underscores the need for developing methods that focus on diverse decoding configurations. Code is publically available at https://github.com/ozyyshr/TempSpec.
Cost-Effective Proxy Reward Model Construction with On-Policy and Active Learning
Jul 02, 2024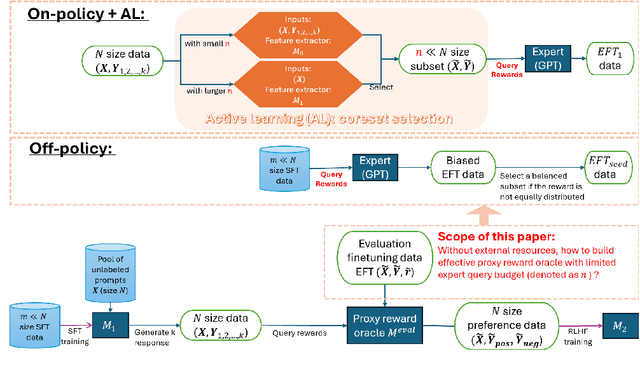
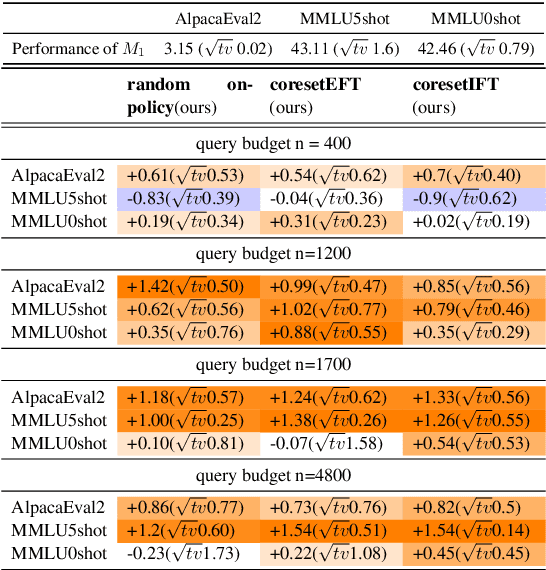

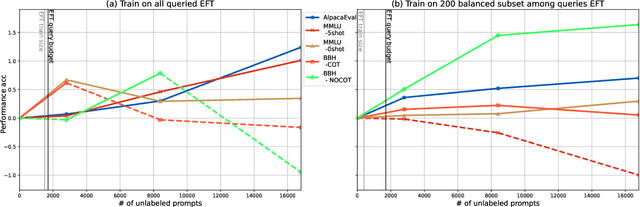
Reinforcement learning with human feedback (RLHF), as a widely adopted approach in current large language model pipelines, is \textit{bottlenecked by the size of human preference data}. While traditional methods rely on offline preference dataset constructions, recent approaches have shifted towards online settings, where a learner uses a small amount of labeled seed data and a large pool of unlabeled prompts to iteratively construct new preference data through self-generated responses and high-quality reward/preference feedback. However, most current online algorithms still focus on preference labeling during policy model updating with given feedback oracles, which incurs significant expert query costs. \textit{We are the first to explore cost-effective proxy reward oracles construction strategies for further labeling preferences or rewards with extremely limited labeled data and expert query budgets}. Our approach introduces two key innovations: (1) on-policy query to avoid OOD and imbalance issues in seed data, and (2) active learning to select the most informative data for preference queries. Using these methods, we train a evaluation model with minimal expert-labeled data, which then effectively labels nine times more preference pairs for further RLHF training. For instance, our model using Direct Preference Optimization (DPO) gains around over 1% average improvement on AlpacaEval2, MMLU-5shot and MMLU-0shot, with only 1.7K query cost. Our methodology is orthogonal to other direct expert query-based strategies and therefore might be integrated with them to further reduce query costs.
Self-Exploring Language Models: Active Preference Elicitation for Online Alignment
May 29, 2024



Preference optimization, particularly through Reinforcement Learning from Human Feedback (RLHF), has achieved significant success in aligning Large Language Models (LLMs) to adhere to human intentions. Unlike offline alignment with a fixed dataset, online feedback collection from humans or AI on model generations typically leads to more capable reward models and better-aligned LLMs through an iterative process. However, achieving a globally accurate reward model requires systematic exploration to generate diverse responses that span the vast space of natural language. Random sampling from standard reward-maximizing LLMs alone is insufficient to fulfill this requirement. To address this issue, we propose a bilevel objective optimistically biased towards potentially high-reward responses to actively explore out-of-distribution regions. By solving the inner-level problem with the reparameterized reward function, the resulting algorithm, named Self-Exploring Language Models (SELM), eliminates the need for a separate RM and iteratively updates the LLM with a straightforward objective. Compared to Direct Preference Optimization (DPO), the SELM objective reduces indiscriminate favor of unseen extrapolations and enhances exploration efficiency. Our experimental results demonstrate that when finetuned on Zephyr-7B-SFT and Llama-3-8B-Instruct models, SELM significantly boosts the performance on instruction-following benchmarks such as MT-Bench and AlpacaEval 2.0, as well as various standard academic benchmarks in different settings. Our code and models are available at https://github.com/shenao-zhang/SELM.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Multi-LoRA Composition for Image Generation
Feb 26, 2024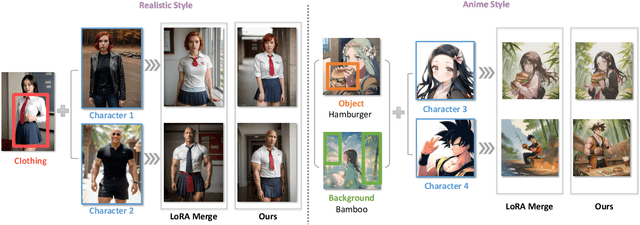

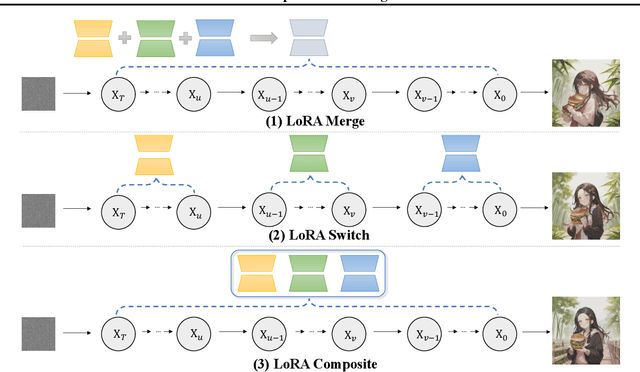
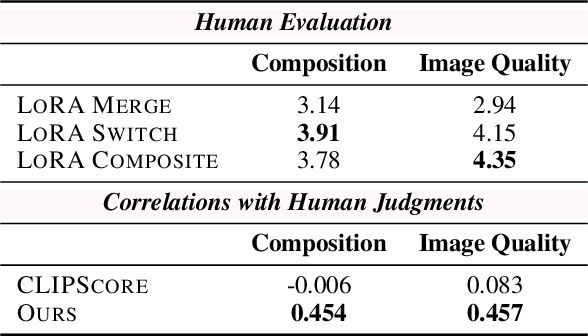
Low-Rank Adaptation (LoRA) is extensively utilized in text-to-image models for the accurate rendition of specific elements like distinct characters or unique styles in generated images. Nonetheless, existing methods face challenges in effectively composing multiple LoRAs, especially as the number of LoRAs to be integrated grows, thus hindering the creation of complex imagery. In this paper, we study multi-LoRA composition through a decoding-centric perspective. We present two training-free methods: LoRA Switch, which alternates between different LoRAs at each denoising step, and LoRA Composite, which simultaneously incorporates all LoRAs to guide more cohesive image synthesis. To evaluate the proposed approaches, we establish ComposLoRA, a new comprehensive testbed as part of this research. It features a diverse range of LoRA categories with 480 composition sets. Utilizing an evaluation framework based on GPT-4V, our findings demonstrate a clear improvement in performance with our methods over the prevalent baseline, particularly evident when increasing the number of LoRAs in a composition.
DecAF: Joint Decoding of Answers and Logical Forms for Question Answering over Knowledge Bases
Sep 30, 2022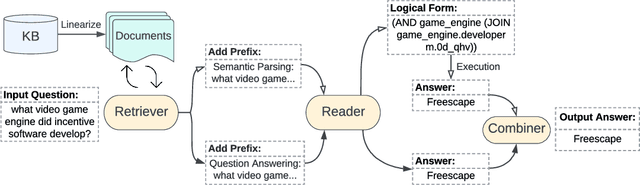



Question answering over knowledge bases (KBs) aims to answer natural language questions with factual information such as entities and relations in KBs. Previous methods either generate logical forms that can be executed over KBs to obtain final answers or predict answers directly. Empirical results show that the former often produces more accurate answers, but it suffers from non-execution issues due to potential syntactic and semantic errors in the generated logical forms. In this work, we propose a novel framework DecAF that jointly generates both logical forms and direct answers, and then combines the merits of them to get the final answers. Moreover, different from most of the previous methods, DecAF is based on simple free-text retrieval without relying on any entity linking tools -- this simplification eases its adaptation to different datasets. DecAF achieves new state-of-the-art accuracy on WebQSP, FreebaseQA, and GrailQA benchmarks, while getting competitive results on the ComplexWebQuestions benchmark.
Long-tailed Extreme Multi-label Text Classification with Generated Pseudo Label Descriptions
Apr 02, 2022
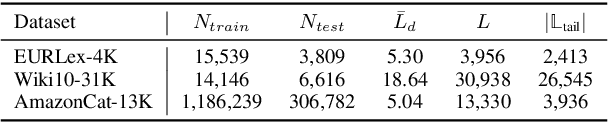
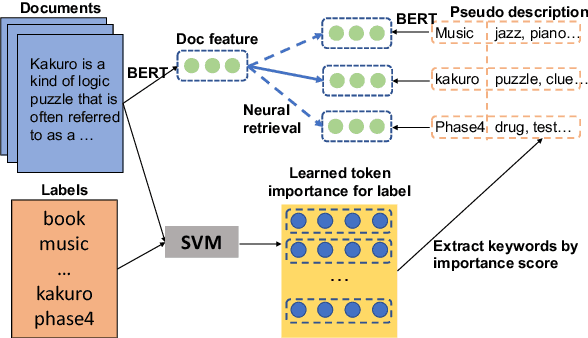
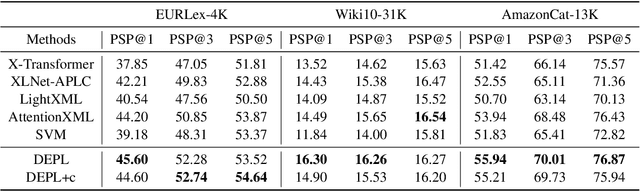
Extreme Multi-label Text Classification (XMTC) has been a tough challenge in machine learning research and applications due to the sheer sizes of the label spaces and the severe data scarce problem associated with the long tail of rare labels in highly skewed distributions. This paper addresses the challenge of tail label prediction by proposing a novel approach, which combines the effectiveness of a trained bag-of-words (BoW) classifier in generating informative label descriptions under severe data scarce conditions, and the power of neural embedding based retrieval models in mapping input documents (as queries) to relevant label descriptions. The proposed approach achieves state-of-the-art performance on XMTC benchmark datasets and significantly outperforms the best methods so far in the tail label prediction. We also provide a theoretical analysis for relating the BoW and neural models w.r.t. performance lower bound.
Dict-BERT: Enhancing Language Model Pre-training with Dictionary
Oct 13, 2021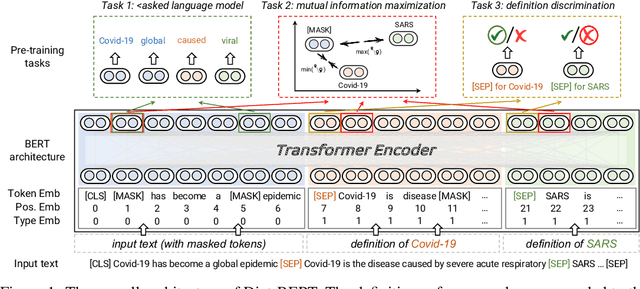



Pre-trained language models (PLMs) aim to learn universal language representations by conducting self-supervised training tasks on large-scale corpora. Since PLMs capture word semantics in different contexts, the quality of word representations highly depends on word frequency, which usually follows a heavy-tailed distributions in the pre-training corpus. Therefore, the embeddings of rare words on the tail are usually poorly optimized. In this work, we focus on enhancing language model pre-training by leveraging definitions of the rare words in dictionaries (e.g., Wiktionary). To incorporate a rare word definition as a part of input, we fetch its definition from the dictionary and append it to the end of the input text sequence. In addition to training with the masked language modeling objective, we propose two novel self-supervised pre-training tasks on word and sentence-level alignment between input text sequence and rare word definitions to enhance language modeling representation with dictionary. We evaluate the proposed Dict-BERT model on the language understanding benchmark GLUE and eight specialized domain benchmark datasets. Extensive experiments demonstrate that Dict-BERT can significantly improve the understanding of rare words and boost model performance on various NLP downstream tasks.
KG-FiD: Infusing Knowledge Graph in Fusion-in-Decoder for Open-Domain Question Answering
Oct 08, 2021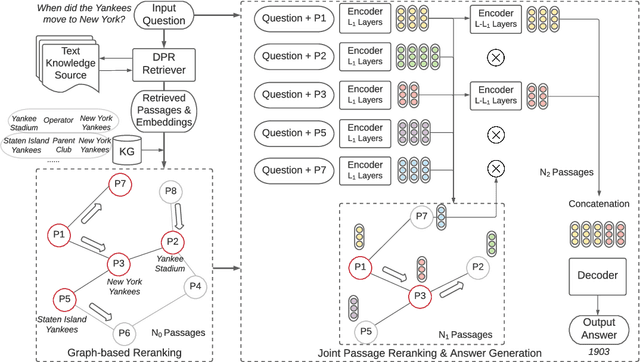
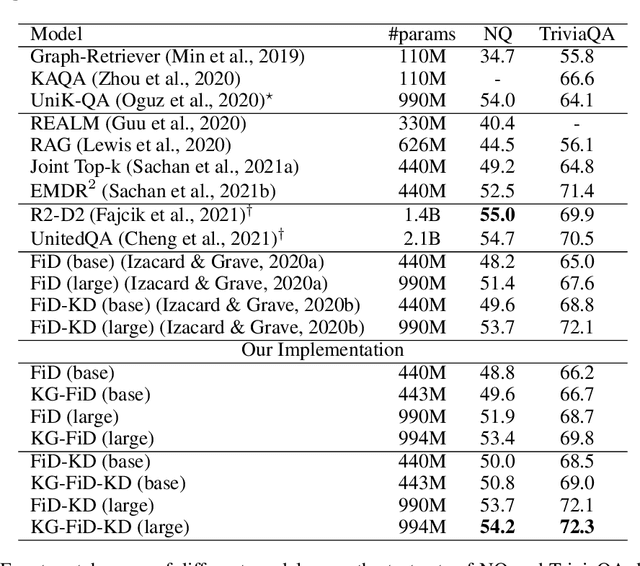


Current Open-Domain Question Answering (ODQA) model paradigm often contains a retrieving module and a reading module. Given an input question, the reading module predicts the answer from the relevant passages which are retrieved by the retriever. The recent proposed Fusion-in-Decoder (FiD), which is built on top of the pretrained generative model T5, achieves the state-of-the-art performance in the reading module. Although being effective, it remains constrained by inefficient attention on all retrieved passages which contain a lot of noise. In this work, we propose a novel method KG-FiD, which filters noisy passages by leveraging the structural relationship among the retrieved passages with a knowledge graph. We initiate the passage node embedding from the FiD encoder and then use graph neural network (GNN) to update the representation for reranking. To improve the efficiency, we build the GNN on top of the intermediate layer output of the FiD encoder and only pass a few top reranked passages into the higher layers of encoder and decoder for answer generation. We also apply the proposed GNN based reranking method to enhance the passage retrieval results in the retrieving module. Extensive experiments on common ODQA benchmark datasets (Natural Question and TriviaQA) demonstrate that KG-FiD can improve vanilla FiD by up to 1.5% on answer exact match score and achieve comparable performance with FiD with only 40% of computation cost.