 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSMentor: Enhancing Data Science Agents with Curriculum Learning and Online Knowledge Accumulation
May 20, 2025Large language model (LLM) agents have shown promising performance in generating code for solving complex data science problems. Recent studies primarily focus on enhancing in-context learning through improved search, sampling, and planning techniques, while overlooking the importance of the order in which problems are tackled during inference. In this work, we develop a novel inference-time optimization framework, referred to as DSMentor, which leverages curriculum learning -- a strategy that introduces simpler task first and progressively moves to more complex ones as the learner improves -- to enhance LLM agent performance in challenging data science tasks. Our mentor-guided framework organizes data science tasks in order of increasing difficulty and incorporates a growing long-term memory to retain prior experiences, guiding the agent's learning progression and enabling more effective utilization of accumulated knowledge. We evaluate DSMentor through extensive experiments on DSEval and QRData benchmarks. Experiments show that DSMentor using Claude-3.5-Sonnet improves the pass rate by up to 5.2% on DSEval and QRData compared to baseline agents. Furthermore, DSMentor demonstrates stronger causal reasoning ability, improving the pass rate by 8.8% on the causality problems compared to GPT-4 using Program-of-Thoughts prompts. Our work underscores the importance of developing effective strategies for accumulating and utilizing knowledge during inference, mirroring the human learning process and opening new avenues for improving LLM performance through curriculum-based inference optimization.
Towards Better Understanding Table Instruction Tuning: Decoupling the Effects from Data versus Models
Jan 24, 2025



Recent advances in natural language processing have leveraged instruction tuning to enhance Large Language Models (LLMs) for table-related tasks. However, previous works train different base models with different training data, lacking an apples-to-apples comparison across the result table LLMs. To address this, we fine-tune base models from the Mistral, OLMo, and Phi families on existing public training datasets. Our replication achieves performance on par with or surpassing existing table LLMs, establishing new state-of-the-art performance on Hitab, a table question-answering dataset. More importantly, through systematic out-of-domain evaluation, we decouple the contributions of training data and the base model, providing insight into their individual impacts. In addition, we assess the effects of table-specific instruction tuning on general-purpose benchmarks, revealing trade-offs between specialization and generalization.
PRACTIQ: A Practical Conversational Text-to-SQL dataset with Ambiguous and Unanswerable Queries
Oct 14, 2024
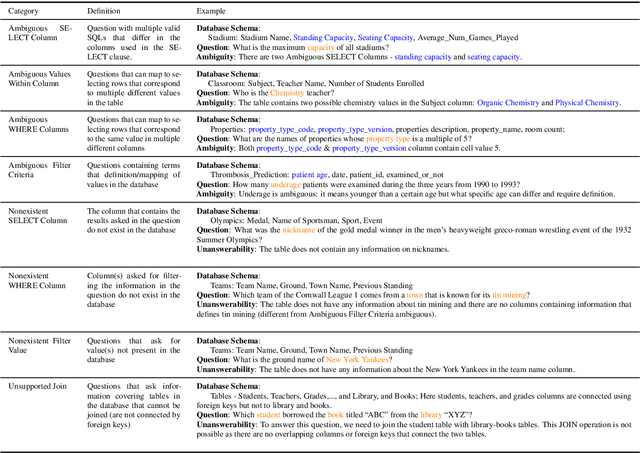
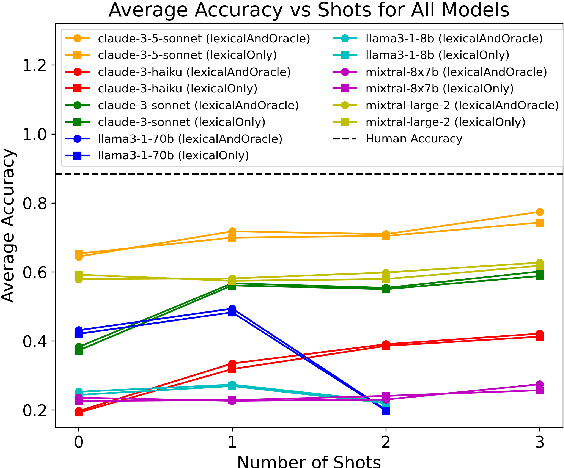
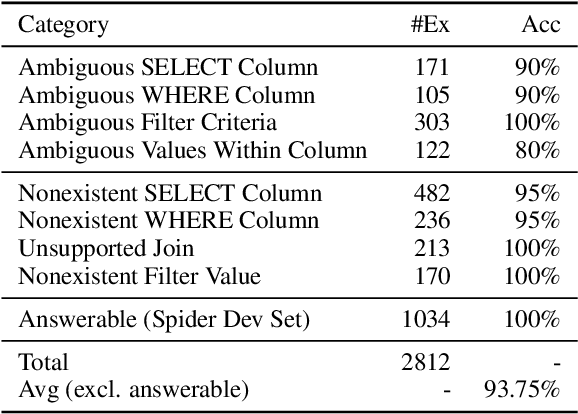
Previous text-to-SQL datasets and systems have primarily focused on user questions with clear intentions that can be answered. However, real user questions can often be ambiguous with multiple interpretations or unanswerable due to a lack of relevant data. In this work, we construct a practical conversational text-to-SQL dataset called PRACTIQ, consisting of ambiguous and unanswerable questions inspired by real-world user questions. We first identified four categories of ambiguous questions and four categories of unanswerable questions by studying existing text-to-SQL datasets. Then, we generate conversations with four turns: the initial user question, an assistant response seeking clarification, the user's clarification, and the assistant's clarified SQL response with the natural language explanation of the execution results. For some ambiguous queries, we also directly generate helpful SQL responses, that consider multiple aspects of ambiguity, instead of requesting user clarification. To benchmark the performance on ambiguous, unanswerable, and answerable questions, we implemented large language model (LLM)-based baselines using various LLMs. Our approach involves two steps: question category classification and clarification SQL prediction. Our experiments reveal that state-of-the-art systems struggle to handle ambiguous and unanswerable questions effectively. We will release our code for data generation and experiments on GitHub.
UNITE: A Unified Benchmark for Text-to-SQL Evaluation
May 26, 2023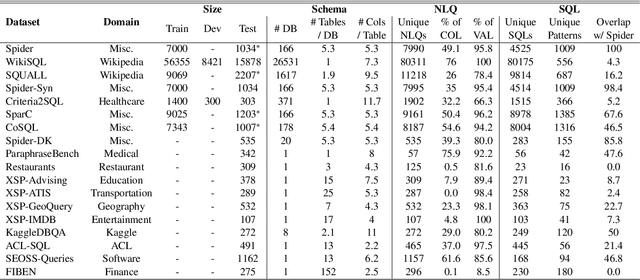
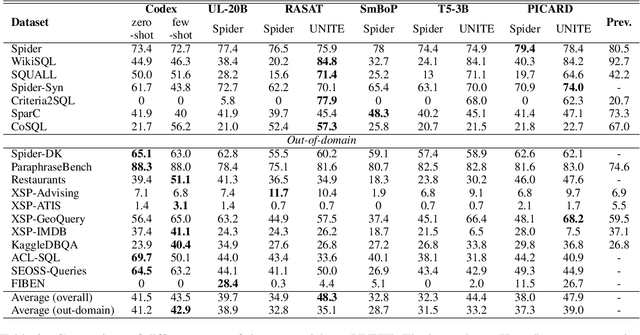
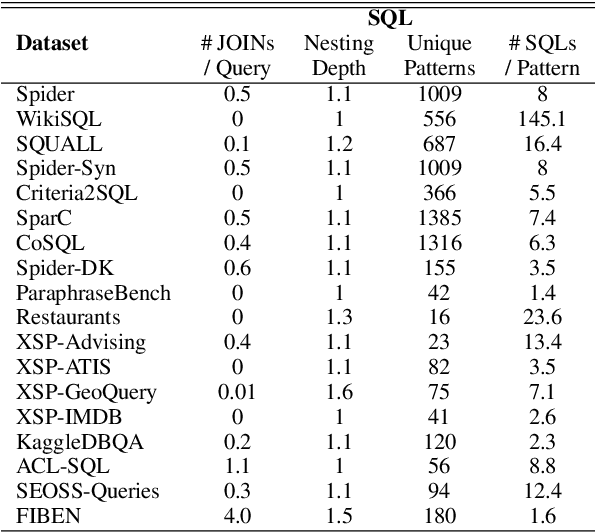
A practical text-to-SQL system should generalize well on a wide variety of natural language questions, unseen database schemas, and novel SQL query structures. To comprehensively evaluate text-to-SQL systems, we introduce a \textbf{UNI}fied benchmark for \textbf{T}ext-to-SQL \textbf{E}valuation (UNITE). It is composed of publicly available text-to-SQL datasets, containing natural language questions from more than 12 domains, SQL queries from more than 3.9K patterns, and 29K databases. Compared to the widely used Spider benchmark \cite{yu-etal-2018-spider}, we introduce $\sim$120K additional examples and a threefold increase in SQL patterns, such as comparative and boolean questions. We conduct a systematic study of six state-of-the-art (SOTA) text-to-SQL parsers on our new benchmark and show that: 1) Codex performs surprisingly well on out-of-domain datasets; 2) specially designed decoding methods (e.g. constrained beam search) can improve performance for both in-domain and out-of-domain settings; 3) explicitly modeling the relationship between questions and schemas further improves the Seq2Seq models. More importantly, our benchmark presents key challenges towards compositional generalization and robustness issues -- which these SOTA models cannot address well. \footnote{Our code and data processing script will be available at \url{https://github.com/XXXX.}}
Importance of Synthesizing High-quality Data for Text-to-SQL Parsing
Dec 17, 2022
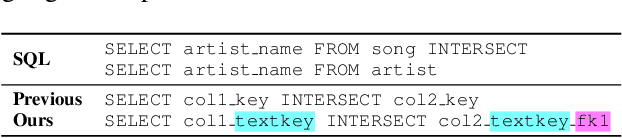
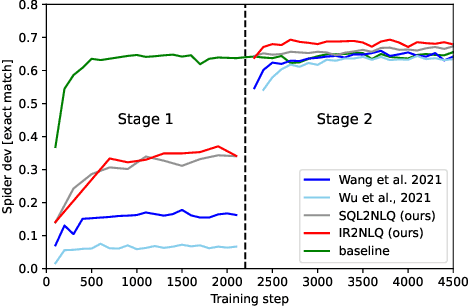

Recently, there has been increasing interest in synthesizing data to improve downstream text-to-SQL tasks. In this paper, we first examined the existing synthesized datasets and discovered that state-of-the-art text-to-SQL algorithms did not further improve on popular benchmarks when trained with augmented synthetic data. We observed two shortcomings: illogical synthetic SQL queries from independent column sampling and arbitrary table joins. To address these issues, we propose a novel synthesis framework that incorporates key relationships from schema, imposes strong typing, and conducts schema-distance-weighted column sampling. We also adopt an intermediate representation (IR) for the SQL-to-text task to further improve the quality of the generated natural language questions. When existing powerful semantic parsers are pre-finetuned on our high-quality synthesized data, our experiments show that these models have significant accuracy boosts on popular benchmarks, including new state-of-the-art performance on Spider.
DecAF: Joint Decoding of Answers and Logical Forms for Question Answering over Knowledge Bases
Sep 30, 2022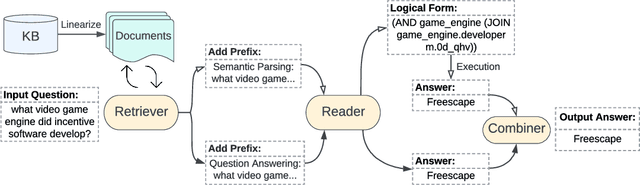



Question answering over knowledge bases (KBs) aims to answer natural language questions with factual information such as entities and relations in KBs. Previous methods either generate logical forms that can be executed over KBs to obtain final answers or predict answers directly. Empirical results show that the former often produces more accurate answers, but it suffers from non-execution issues due to potential syntactic and semantic errors in the generated logical forms. In this work, we propose a novel framework DecAF that jointly generates both logical forms and direct answers, and then combines the merits of them to get the final answers. Moreover, different from most of the previous methods, DecAF is based on simple free-text retrieval without relying on any entity linking tools -- this simplification eases its adaptation to different datasets. DecAF achieves new state-of-the-art accuracy on WebQSP, FreebaseQA, and GrailQA benchmarks, while getting competitive results on the ComplexWebQuestions benchmark.
Multispectral Palmprint Encoding and Recognition
Feb 06, 2014
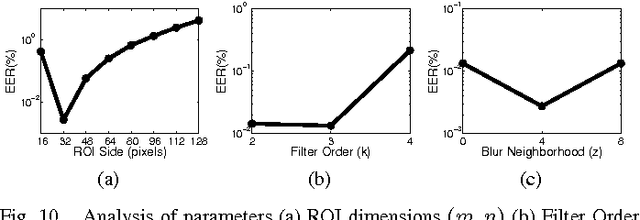
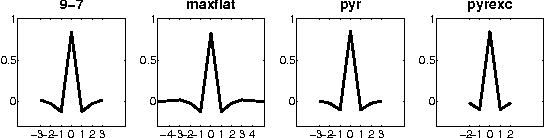
Palmprints are emerging as a new entity in multi-modal biometrics for human identification and verification. Multispectral palmprint images captured in the visible and infrared spectrum not only contain the wrinkles and ridge structure of a palm, but also the underlying pattern of veins; making them a highly discriminating biometric identifier. In this paper, we propose a feature encoding scheme for robust and highly accurate representation and matching of multispectral palmprints. To facilitate compact storage of the feature, we design a binary hash table structure that allows for efficient matching in large databases. Comprehensive experiments for both identification and verification scenarios are performed on two public datasets -- one captured with a contact-based sensor (PolyU dataset), and the other with a contact-free sensor (CASIA dataset). Recognition results in various experimental setups show that the proposed method consistently outperforms existing state-of-the-art methods. Error rates achieved by our method (0.003% on PolyU and 0.2% on CASIA) are the lowest reported in literature on both dataset and clearly indicate the viability of palmprint as a reliable and promising biometric. All source codes are publicly available.