 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neurosymbolic Approach to Natural Language Formalization and Verification
Nov 12, 2025Large Language Models perform well at natural language interpretation and reasoning, but their inherent stochasticity limits their adoption in regulated industries like finance and healthcare that operate under strict policies. To address this limitation, we present a two-stage neurosymbolic framework that (1) uses LLMs with optional human guidance to formalize natural language policies, allowing fine-grained control of the formalization process, and (2) uses inference-time autoformalization to validate logical correctness of natural language statements against those policies. When correctness is paramount, we perform multiple redundant formalization steps at inference time, cross checking the formalizations for semantic equivalence. Our benchmarks demonstrate that our approach exceeds 99% soundness, indicating a near-zero false positive rate in identifying logical validity. Our approach produces auditable logical artifacts that substantiate the verification outcomes and can be used to improve the original text.
UNITE: A Unified Benchmark for Text-to-SQL Evaluation
May 26, 2023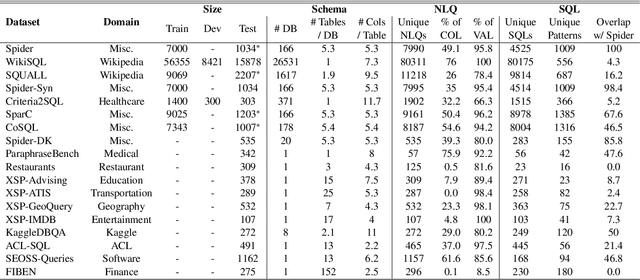
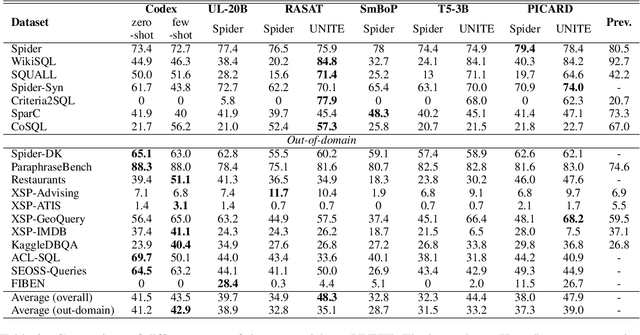
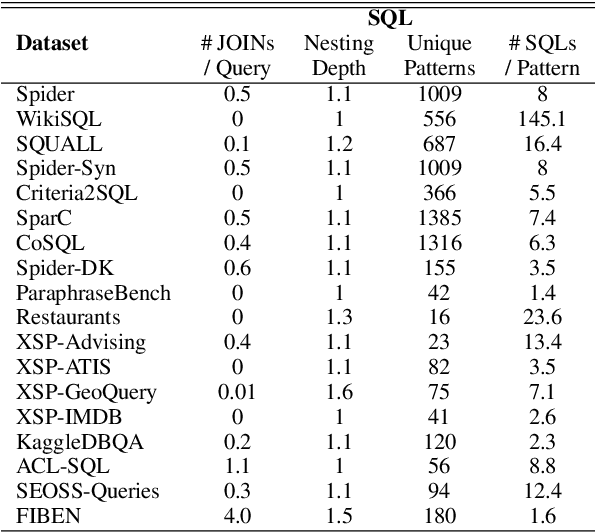
A practical text-to-SQL system should generalize well on a wide variety of natural language questions, unseen database schemas, and novel SQL query structures. To comprehensively evaluate text-to-SQL systems, we introduce a \textbf{UNI}fied benchmark for \textbf{T}ext-to-SQL \textbf{E}valuation (UNITE). It is composed of publicly available text-to-SQL datasets, containing natural language questions from more than 12 domains, SQL queries from more than 3.9K patterns, and 29K databases. Compared to the widely used Spider benchmark \cite{yu-etal-2018-spider}, we introduce $\sim$120K additional examples and a threefold increase in SQL patterns, such as comparative and boolean questions. We conduct a systematic study of six state-of-the-art (SOTA) text-to-SQL parsers on our new benchmark and show that: 1) Codex performs surprisingly well on out-of-domain datasets; 2) specially designed decoding methods (e.g. constrained beam search) can improve performance for both in-domain and out-of-domain settings; 3) explicitly modeling the relationship between questions and schemas further improves the Seq2Seq models. More importantly, our benchmark presents key challenges towards compositional generalization and robustness issues -- which these SOTA models cannot address well. \footnote{Our code and data processing script will be available at \url{https://github.com/XXXX.}}
Dr.Spider: A Diagnostic Evaluation Benchmark towards Text-to-SQL Robustness
Jan 21, 2023



Neural text-to-SQL models have achieved remarkable performance in translating natural language questions into SQL queries. However, recent studies reveal that text-to-SQL models are vulnerable to task-specific perturbations. Previous curated robustness test sets usually focus on individual phenomena. In this paper, we propose a comprehensive robustness benchmark based on Spider, a cross-domain text-to-SQL benchmark, to diagnose the model robustness. We design 17 perturbations on databases, natural language questions, and SQL queries to measure the robustness from different angles. In order to collect more diversified natural question perturbations, we utilize large pretrained language models (PLMs) to simulate human behaviors in creating natural questions. We conduct a diagnostic study of the state-of-the-art models on the robustness set. Experimental results reveal that even the most robust model suffers from a 14.0% performance drop overall and a 50.7% performance drop on the most challenging perturbation. We also present a breakdown analysis regarding text-to-SQL model designs and provide insights for improving model robustness.