 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoison Once, Exploit Forever: Environment-Injected Memory Poisoning Attacks on Web Agents
Apr 03, 2026Memory makes LLM-based web agents personalized, powerful, yet exploitable. By storing past interactions to personalize future tasks, agents inadvertently create a persistent attack surface that spans websites and sessions. While existing security research on memory assumes attackers can directly inject into memory storage or exploit shared memory across users, we present a more realistic threat model: contamination through environmental observation alone. We introduce Environment-injected Trajectory-based Agent Memory Poisoning (eTAMP), the first attack to achieve cross-session, cross-site compromise without requiring direct memory access. A single contaminated observation (e.g., viewing a manipulated product page) silently poisons an agent's memory and activates during future tasks on different websites, bypassing permission-based defenses. Our experiments on (Visual)WebArena reveal two key findings. First, eTAMP achieves substantial attack success rates: up to 32.5% on GPT-5-mini, 23.4% on GPT-5.2, and 19.5% on GPT-OSS-120B. Second, we discover Frustration Exploitation: agents under environmental stress become dramatically more susceptible, with ASR increasing up to 8 times when agents struggle with dropped clicks or garbled text. Notably, more capable models are not more secure. GPT-5.2 shows substantial vulnerability despite superior task performance. With the rise of AI browsers like OpenClaw, ChatGPT Atlas, and Perplexity Comet, our findings underscore the urgent need for defenses against environment-injected memory poisoning.
PRACTIQ: A Practical Conversational Text-to-SQL dataset with Ambiguous and Unanswerable Queries
Oct 14, 2024
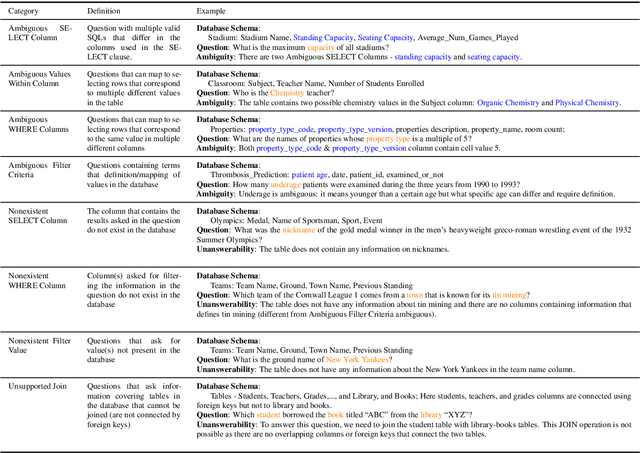
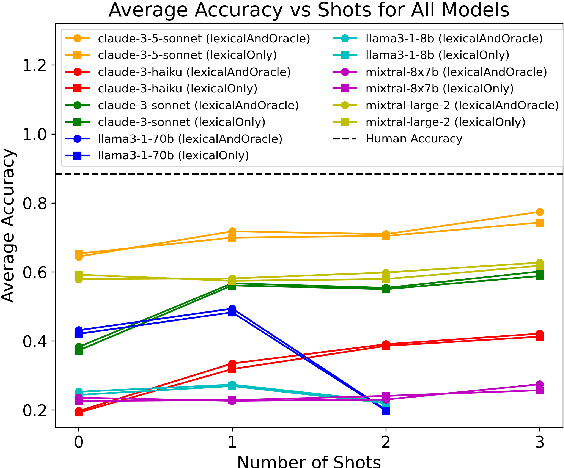
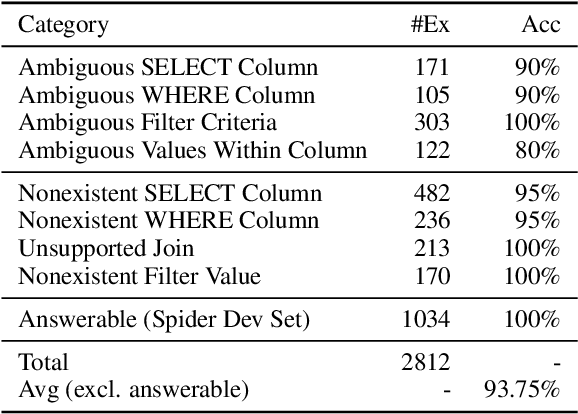
Previous text-to-SQL datasets and systems have primarily focused on user questions with clear intentions that can be answered. However, real user questions can often be ambiguous with multiple interpretations or unanswerable due to a lack of relevant data. In this work, we construct a practical conversational text-to-SQL dataset called PRACTIQ, consisting of ambiguous and unanswerable questions inspired by real-world user questions. We first identified four categories of ambiguous questions and four categories of unanswerable questions by studying existing text-to-SQL datasets. Then, we generate conversations with four turns: the initial user question, an assistant response seeking clarification, the user's clarification, and the assistant's clarified SQL response with the natural language explanation of the execution results. For some ambiguous queries, we also directly generate helpful SQL responses, that consider multiple aspects of ambiguity, instead of requesting user clarification. To benchmark the performance on ambiguous, unanswerable, and answerable questions, we implemented large language model (LLM)-based baselines using various LLMs. Our approach involves two steps: question category classification and clarification SQL prediction. Our experiments reveal that state-of-the-art systems struggle to handle ambiguous and unanswerable questions effectively. We will release our code for data generation and experiments on GitHub.
Propagation and Pitfalls: Reasoning-based Assessment of Knowledge Editing through Counterfactual Tasks
Jan 31, 2024Current approaches of knowledge editing struggle to effectively propagate updates to interconnected facts. In this work, we delve into the barriers that hinder the appropriate propagation of updated knowledge within these models for accurate reasoning. To support our analysis, we introduce a novel reasoning-based benchmark -- ReCoE (Reasoning-based Counterfactual Editing dataset) -- which covers six common reasoning schemes in real world. We conduct a thorough analysis of existing knowledge editing techniques, including input augmentation, finetuning, and locate-and-edit. We found that all model editing methods show notably low performance on this dataset, especially in certain reasoning schemes. Our analysis over the chain-of-thought generation of edited models further uncover key reasons behind the inadequacy of existing knowledge editing methods from a reasoning standpoint, involving aspects on fact-wise editing, fact recall ability, and coherence in generation. We will make our benchmark publicly available.
UNITE: A Unified Benchmark for Text-to-SQL Evaluation
May 26, 2023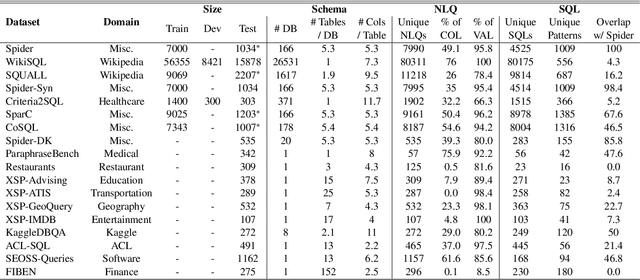
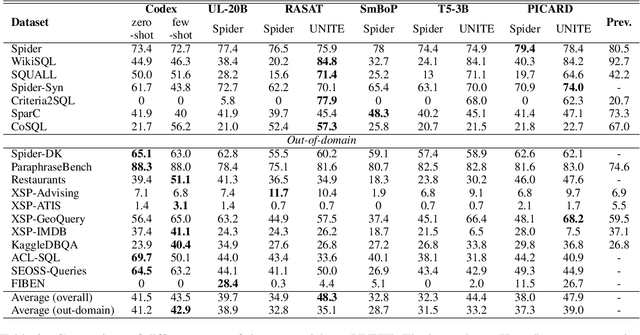
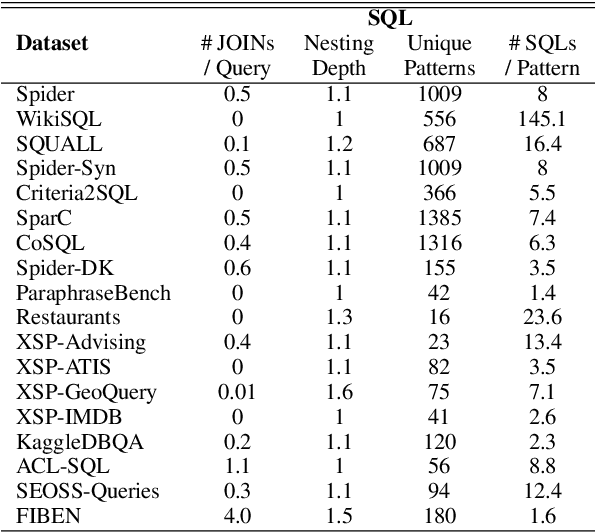
A practical text-to-SQL system should generalize well on a wide variety of natural language questions, unseen database schemas, and novel SQL query structures. To comprehensively evaluate text-to-SQL systems, we introduce a \textbf{UNI}fied benchmark for \textbf{T}ext-to-SQL \textbf{E}valuation (UNITE). It is composed of publicly available text-to-SQL datasets, containing natural language questions from more than 12 domains, SQL queries from more than 3.9K patterns, and 29K databases. Compared to the widely used Spider benchmark \cite{yu-etal-2018-spider}, we introduce $\sim$120K additional examples and a threefold increase in SQL patterns, such as comparative and boolean questions. We conduct a systematic study of six state-of-the-art (SOTA) text-to-SQL parsers on our new benchmark and show that: 1) Codex performs surprisingly well on out-of-domain datasets; 2) specially designed decoding methods (e.g. constrained beam search) can improve performance for both in-domain and out-of-domain settings; 3) explicitly modeling the relationship between questions and schemas further improves the Seq2Seq models. More importantly, our benchmark presents key challenges towards compositional generalization and robustness issues -- which these SOTA models cannot address well. \footnote{Our code and data processing script will be available at \url{https://github.com/XXXX.}}
Dr.Spider: A Diagnostic Evaluation Benchmark towards Text-to-SQL Robustness
Jan 21, 2023



Neural text-to-SQL models have achieved remarkable performance in translating natural language questions into SQL queries. However, recent studies reveal that text-to-SQL models are vulnerable to task-specific perturbations. Previous curated robustness test sets usually focus on individual phenomena. In this paper, we propose a comprehensive robustness benchmark based on Spider, a cross-domain text-to-SQL benchmark, to diagnose the model robustness. We design 17 perturbations on databases, natural language questions, and SQL queries to measure the robustness from different angles. In order to collect more diversified natural question perturbations, we utilize large pretrained language models (PLMs) to simulate human behaviors in creating natural questions. We conduct a diagnostic study of the state-of-the-art models on the robustness set. Experimental results reveal that even the most robust model suffers from a 14.0% performance drop overall and a 50.7% performance drop on the most challenging perturbation. We also present a breakdown analysis regarding text-to-SQL model designs and provide insights for improving model robustness.
Robust Information Retrieval for False Claims with Distracting Entities In Fact Extraction and Verification
Dec 10, 2021
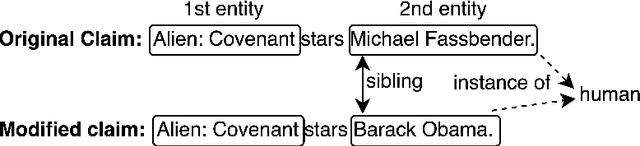
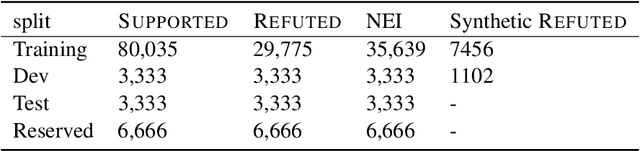
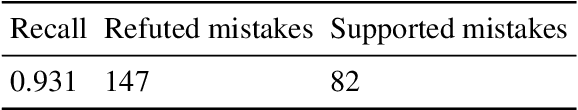
Accurate evidence retrieval is essential for automated fact checking. Little previous research has focused on the differences between true and false claims and how they affect evidence retrieval. This paper shows that, compared with true claims, false claims more frequently contain irrelevant entities which can distract evidence retrieval model. A BERT-based retrieval model made more mistakes in retrieving refuting evidence for false claims than supporting evidence for true claims. When tested with adversarial false claims (synthetically generated) containing irrelevant entities, the recall of the retrieval model is significantly lower than that for original claims. These results suggest that the vanilla BERT-based retrieval model is not robust to irrelevant entities in the false claims. By augmenting the training data with synthetic false claims containing irrelevant entities, the trained model achieved higher evidence recall, including that of false claims with irrelevant entities. In addition, using separate models to retrieve refuting and supporting evidence and then aggregating them can also increase the evidence recall, including that of false claims with irrelevant entities. These results suggest that we can increase the BERT-based retrieval model's robustness to false claims with irrelevant entities via data augmentation and model ensemble.
Convolutional Neural Network Achieves Human-level Accuracy in Music Genre Classification
Feb 27, 2018
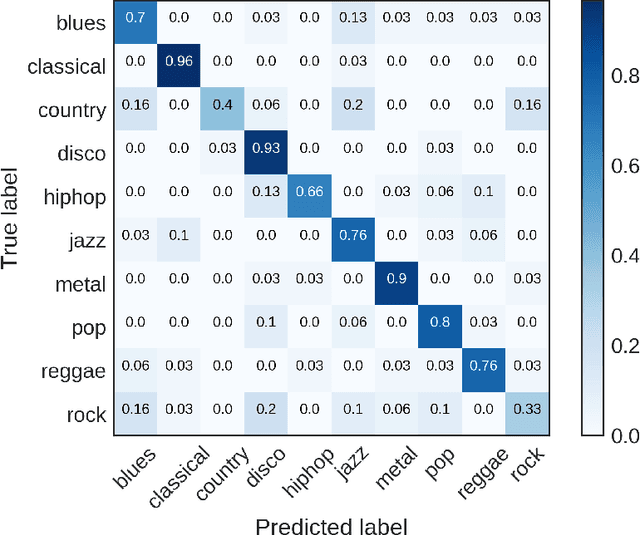

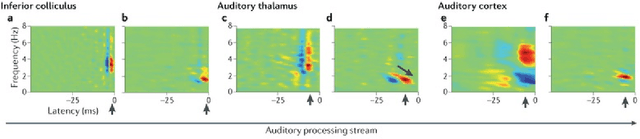
Music genre classification is one example of content-based analysis of music signals. Traditionally, human-engineered features were used to automatize this task and 61% accuracy has been achieved in the 10-genre classification. However, it's still below the 70% accuracy that humans could achieve in the same task. Here, we propose a new method that combines knowledge of human perception study in music genre classification and the neurophysiology of the auditory system. The method works by training a simple convolutional neural network (CNN) to classify a short segment of the music signal. Then, the genre of a music is determined by splitting it into short segments and then combining CNN's predictions from all short segments. After training, this method achieves human-level (70%) accuracy and the filters learned in the CNN resemble the spectrotemporal receptive field (STRF) in the auditory system.