 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhose story is it? Personalizing story generation by inferring author styles
Feb 18, 2025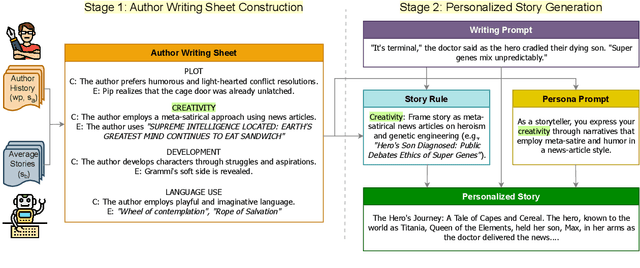

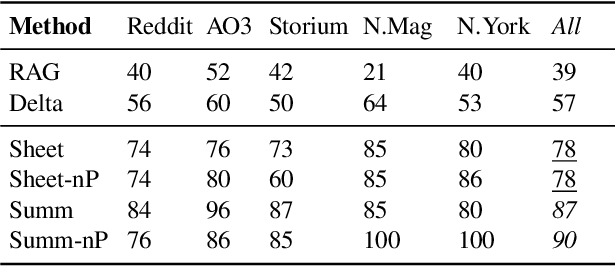
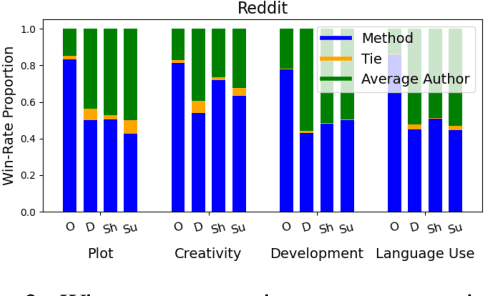
Personalization has become essential for improving user experience in interactive writing and educational applications, yet its potential in story generation remains largely unexplored. In this work, we propose a novel two-stage pipeline for personalized story generation. Our approach first infers an author's implicit story-writing characteristics from their past work and organizes them into an Author Writing Sheet, inspired by narrative theory. The second stage uses this sheet to simulate the author's persona through tailored persona descriptions and personalized story writing rules. To enable and validate our approach, we construct Mythos, a dataset of 590 stories from 64 authors across five distinct sources that reflect diverse story-writing settings. A head-to-head comparison with a non-personalized baseline demonstrates our pipeline's effectiveness in generating high-quality personalized stories. Our personalized stories achieve a 75 percent win rate (versus 14 percent for the baseline and 11 percent ties) in capturing authors' writing style based on their past works. Human evaluation highlights the high quality of our Author Writing Sheet and provides valuable insights into the personalized story generation task. Notable takeaways are that writings from certain sources, such as Reddit, are easier to personalize than others, like AO3, while narrative aspects, like Creativity and Language Use, are easier to personalize than others, like Plot.
PRACTIQ: A Practical Conversational Text-to-SQL dataset with Ambiguous and Unanswerable Queries
Oct 14, 2024
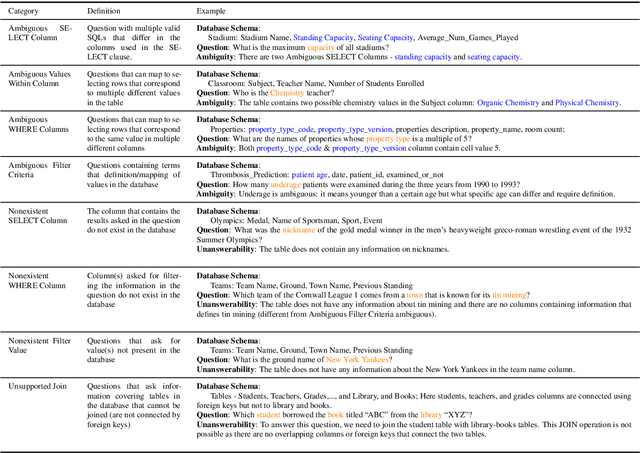
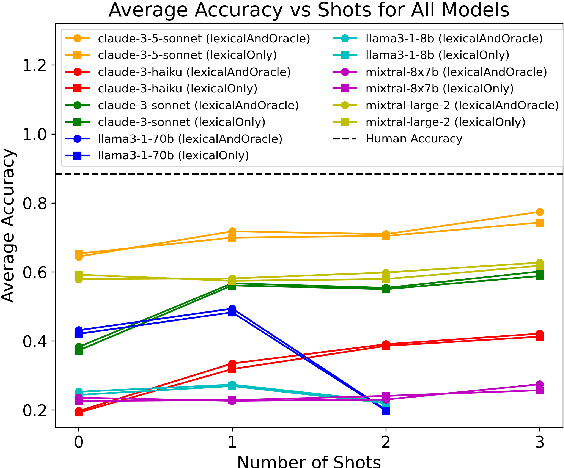
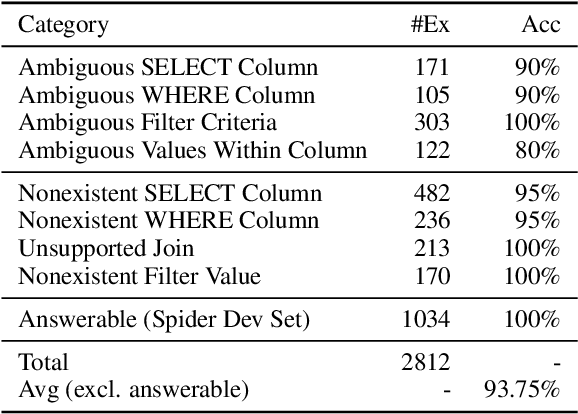
Previous text-to-SQL datasets and systems have primarily focused on user questions with clear intentions that can be answered. However, real user questions can often be ambiguous with multiple interpretations or unanswerable due to a lack of relevant data. In this work, we construct a practical conversational text-to-SQL dataset called PRACTIQ, consisting of ambiguous and unanswerable questions inspired by real-world user questions. We first identified four categories of ambiguous questions and four categories of unanswerable questions by studying existing text-to-SQL datasets. Then, we generate conversations with four turns: the initial user question, an assistant response seeking clarification, the user's clarification, and the assistant's clarified SQL response with the natural language explanation of the execution results. For some ambiguous queries, we also directly generate helpful SQL responses, that consider multiple aspects of ambiguity, instead of requesting user clarification. To benchmark the performance on ambiguous, unanswerable, and answerable questions, we implemented large language model (LLM)-based baselines using various LLMs. Our approach involves two steps: question category classification and clarification SQL prediction. Our experiments reveal that state-of-the-art systems struggle to handle ambiguous and unanswerable questions effectively. We will release our code for data generation and experiments on GitHub.
Improving Socratic Question Generation using Data Augmentation and Preference Optimization
Mar 01, 2024The Socratic method is a way of guiding students toward solving a problem independently without directly revealing the solution to the problem. Although this method has been shown to significantly improve student learning outcomes, it remains a complex labor-intensive task for instructors. Large language models (LLMs) can be used to augment human effort by automatically generating Socratic questions for students. However, existing methods that involve prompting these LLMs sometimes produce invalid outputs, e.g., those that directly reveal the solution to the problem or provide irrelevant or premature questions. To alleviate this problem, inspired by reinforcement learning with AI feedback (RLAIF), we first propose a data augmentation method to enrich existing Socratic questioning datasets with questions that are invalid in specific ways. Next, we propose a method to optimize open-source LLMs such as LLama 2 to prefer ground-truth questions over generated invalid ones, using direct preference optimization (DPO). Our experiments on a Socratic questions dataset for student code debugging show that a DPO-optimized 7B LLama 2 model can effectively avoid generating invalid questions, and as a result, outperforms existing state-of-the-art prompting methods.
Using Large Language Models for Student-Code Guided Test Case Generation in Computer Science Education
Feb 11, 2024


In computer science education, test cases are an integral part of programming assignments since they can be used as assessment items to test students' programming knowledge and provide personalized feedback on student-written code. The goal of our work is to propose a fully automated approach for test case generation that can accurately measure student knowledge, which is important for two reasons. First, manually constructing test cases requires expert knowledge and is a labor-intensive process. Second, developing test cases for students, especially those who are novice programmers, is significantly different from those oriented toward professional-level software developers. Therefore, we need an automated process for test case generation to assess student knowledge and provide feedback. In this work, we propose a large language model-based approach to automatically generate test cases and show that they are good measures of student knowledge, using a publicly available dataset that contains student-written Java code. We also discuss future research directions centered on using test cases to help students.
Multi-Intent Detection in User Provided Annotations for Programming by Examples Systems
Jul 08, 2023



In mapping enterprise applications, data mapping remains a fundamental part of integration development, but its time consuming. An increasing number of applications lack naming standards, and nested field structures further add complexity for the integration developers. Once the mapping is done, data transformation is the next challenge for the users since each application expects data to be in a certain format. Also, while building integration flow, developers need to understand the format of the source and target data field and come up with transformation program that can change data from source to target format. The problem of automatic generation of a transformation program through program synthesis paradigm from some specifications has been studied since the early days of Artificial Intelligence (AI). Programming by Example (PBE) is one such kind of technique that targets automatic inferencing of a computer program to accomplish a format or string conversion task from user-provided input and output samples. To learn the correct intent, a diverse set of samples from the user is required. However, there is a possibility that the user fails to provide a diverse set of samples. This can lead to multiple intents or ambiguity in the input and output samples. Hence, PBE systems can get confused in generating the correct intent program. In this paper, we propose a deep neural network based ambiguity prediction model, which analyzes the input-output strings and maps them to a different set of properties responsible for multiple intent. Users can analyze these properties and accordingly can provide new samples or modify existing samples which can help in building a better PBE system for mapping enterprise applications.
Improving Reading Comprehension Question Generation with Data Augmentation and Overgenerate-and-rank
Jun 15, 2023



Reading comprehension is a crucial skill in many aspects of education, including language learning, cognitive development, and fostering early literacy skills in children. Automated answer-aware reading comprehension question generation has significant potential to scale up learner support in educational activities. One key technical challenge in this setting is that there can be multiple questions, sometimes very different from each other, with the same answer; a trained question generation method may not necessarily know which question human educators would prefer. To address this challenge, we propose 1) a data augmentation method that enriches the training dataset with diverse questions given the same context and answer and 2) an overgenerate-and-rank method to select the best question from a pool of candidates. We evaluate our method on the FairytaleQA dataset, showing a 5% absolute improvement in ROUGE-L over the best existing method. We also demonstrate the effectiveness of our method in generating harder, "implicit" questions, where the answers are not contained in the context as text spans.
A Conceptual Model for End-to-End Causal Discovery in Knowledge Tracing
May 11, 2023



In this paper, we take a preliminary step towards solving the problem of causal discovery in knowledge tracing, i.e., finding the underlying causal relationship among different skills from real-world student response data. This problem is important since it can potentially help us understand the causal relationship between different skills without extensive A/B testing, which can potentially help educators to design better curricula according to skill prerequisite information. Specifically, we propose a conceptual solution, a novel causal gated recurrent unit (GRU) module in a modified deep knowledge tracing model, which uses i) a learnable permutation matrix for causal ordering among skills and ii) an optionally learnable lower-triangular matrix for causal structure among skills. We also detail how to learn the model parameters in an end-to-end, differentiable way. Our solution placed among the top entries in Task 3 of the NeurIPS 2022 Challenge on Causal Insights for Learning Paths in Education. We detail preliminary experiments as evaluated on the challenge's public leaderboard since the ground truth causal structure has not been publicly released, making detailed local evaluation impossible.