 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDB SwinT: A Dual-Branch Swin Transformer Network for Road Extraction in Optical Remote Sensing Imagery
Mar 25, 2026With the continuous improvement in the spatial resolution of optical remote sensing imagery, accurate road extraction has become increasingly important for applications such as urban planning, traffic monitoring, and disaster management. However, road extraction in complex urban and rural environments remains challenging, as roads are often occluded by trees, buildings, and other objects, leading to fragmented structures and reduced extraction accuracy. To address this problem, this paper proposes a Dual-Branch Swin Transformer network (DB SwinT) for road extraction. The proposed framework combines the long-range dependency modeling capability of the Swin Transformer with the multi-scale feature fusion strategy of U-Net, and employs a dual-branch encoder to learn complementary local and global representations. Specifically, the local branch focuses on recovering fine structural details in occluded areas, while the global branch captures broader semantic context to preserve the overall continuity of road networks. In addition, an Attentional Feature Fusion (AFF) module is introduced to adaptively fuse features from the two branches, further enhancing the representation of occluded road segments. Experimental results on the Massachusetts and DeepGlobe datasets show that DB SwinT achieves Intersection over Union (IoU) scores of 79.35\% and 74.84\%, respectively, demonstrating its effectiveness for road extraction from optical remote sensing imagery.
On Synthetic Data Strategies for Domain-Specific Generative Retrieval
Feb 25, 2025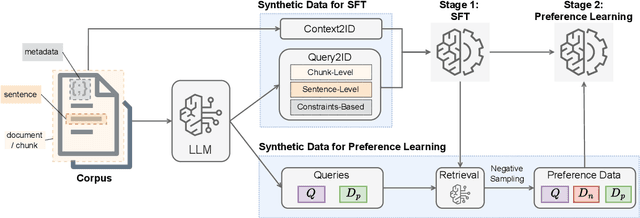
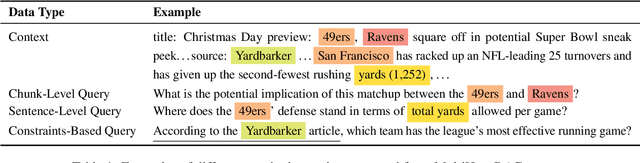
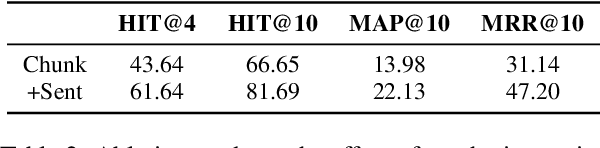
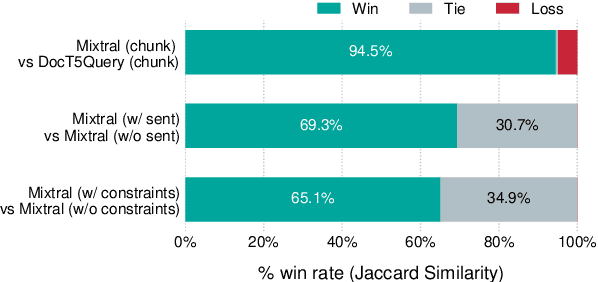
This paper investigates synthetic data generation strategies in developing generative retrieval models for domain-specific corpora, thereby addressing the scalability challenges inherent in manually annotating in-domain queries. We study the data strategies for a two-stage training framework: in the first stage, which focuses on learning to decode document identifiers from queries, we investigate LLM-generated queries across multiple granularity (e.g. chunks, sentences) and domain-relevant search constraints that can better capture nuanced relevancy signals. In the second stage, which aims to refine document ranking through preference learning, we explore the strategies for mining hard negatives based on the initial model's predictions. Experiments on public datasets over diverse domains demonstrate the effectiveness of our synthetic data generation and hard negative sampling approach.
PRACTIQ: A Practical Conversational Text-to-SQL dataset with Ambiguous and Unanswerable Queries
Oct 14, 2024
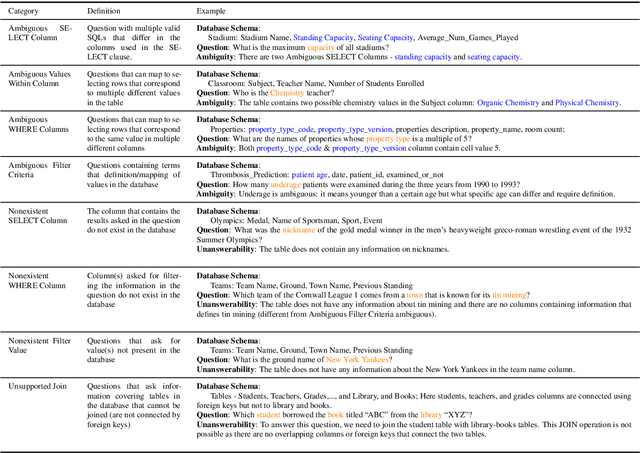
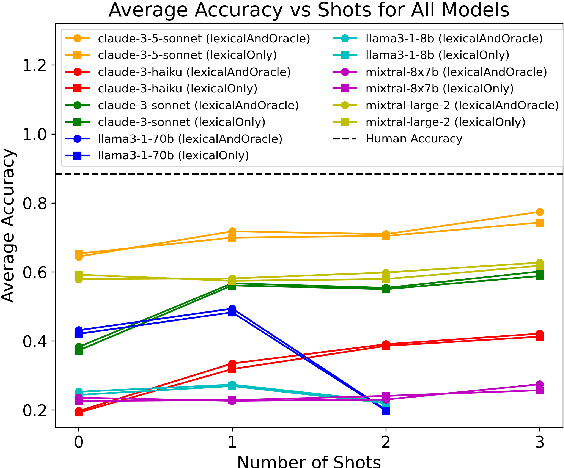
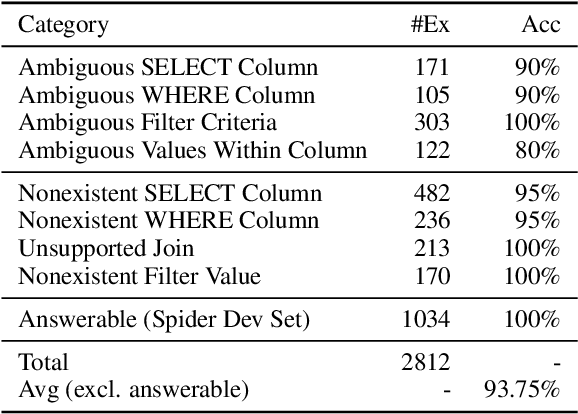
Previous text-to-SQL datasets and systems have primarily focused on user questions with clear intentions that can be answered. However, real user questions can often be ambiguous with multiple interpretations or unanswerable due to a lack of relevant data. In this work, we construct a practical conversational text-to-SQL dataset called PRACTIQ, consisting of ambiguous and unanswerable questions inspired by real-world user questions. We first identified four categories of ambiguous questions and four categories of unanswerable questions by studying existing text-to-SQL datasets. Then, we generate conversations with four turns: the initial user question, an assistant response seeking clarification, the user's clarification, and the assistant's clarified SQL response with the natural language explanation of the execution results. For some ambiguous queries, we also directly generate helpful SQL responses, that consider multiple aspects of ambiguity, instead of requesting user clarification. To benchmark the performance on ambiguous, unanswerable, and answerable questions, we implemented large language model (LLM)-based baselines using various LLMs. Our approach involves two steps: question category classification and clarification SQL prediction. Our experiments reveal that state-of-the-art systems struggle to handle ambiguous and unanswerable questions effectively. We will release our code for data generation and experiments on GitHub.
A First-Order Algorithm for Graph Learning from Smooth Signals Under Partial Observability
Oct 08, 2024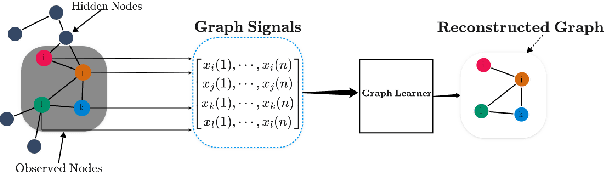

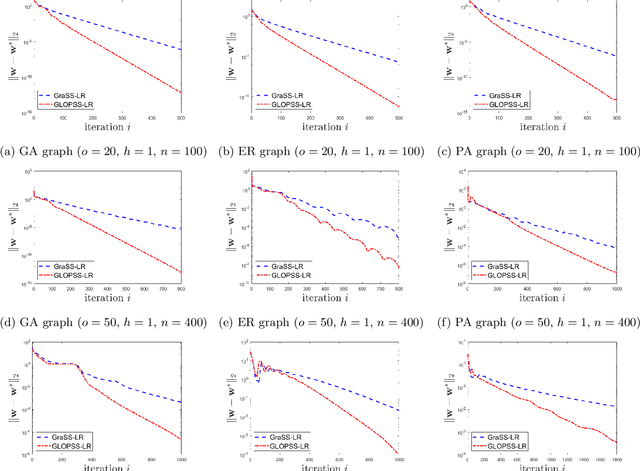
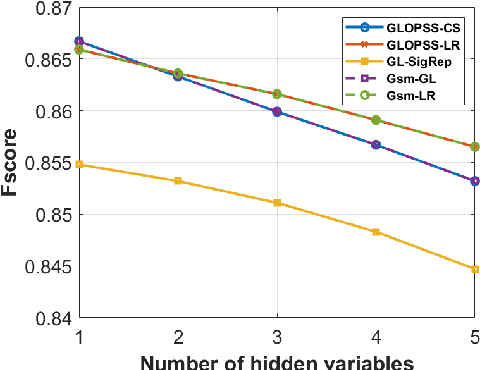
Learning graph structures from smooth signals is a significant problem in data science and engineering. A common challenge in real-world scenarios is the availability of only partially observed nodes. While some studies have considered hidden nodes and proposed various optimization frameworks, existing methods often lack the practical efficiency needed for large-scale networks or fail to provide theoretical convergence guarantees. In this paper, we address the problem of inferring network topologies from smooth signals with partially observed nodes. We propose a first-order algorithmic framework that includes two variants: one based on column sparsity regularization and the other on a low-rank constraint. We establish theoretical convergence guarantees and demonstrate the linear convergence rate of our algorithms. Extensive experiments on both synthetic and real-world data show that our results align with theoretical predictions, exhibiting not only linear convergence but also superior speed compared to existing methods. To the best of our knowledge, this is the first work to propose a first-order algorithmic framework for inferring network structures from smooth signals under partial observability, offering both guaranteed linear convergence and practical effectiveness for large-scale networks.
You Only Read Once (YORO): Learning to Internalize Database Knowledge for Text-to-SQL
Sep 18, 2024



While significant progress has been made on the text-to-SQL task, recent solutions repeatedly encode the same database schema for every question, resulting in unnecessary high inference cost and often overlooking crucial database knowledge. To address these issues, we propose You Only Read Once (YORO), a novel paradigm that directly internalizes database knowledge into the parametric knowledge of a text-to-SQL model during training and eliminates the need for schema encoding during inference. YORO significantly reduces the input token length by 66%-98%. Despite its shorter inputs, our empirical results demonstrate YORO's competitive performances with traditional systems on three benchmarks as well as its significant outperformance on large databases. Furthermore, YORO excels in handling questions with challenging value retrievals such as abbreviation.
RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
Aug 15, 2024



Despite Retrieval-Augmented Generation (RAG) has shown promising capability in leveraging external knowledge, a comprehensive evaluation of RAG systems is still challenging due to the modular nature of RAG, evaluation of long-form responses and reliability of measurements. In this paper, we propose a fine-grained evaluation framework, RAGChecker, that incorporates a suite of diagnostic metrics for both the retrieval and generation modules. Meta evaluation verifies that RAGChecker has significantly better correlations with human judgments than other evaluation metrics. Using RAGChecker, we evaluate 8 RAG systems and conduct an in-depth analysis of their performance, revealing insightful patterns and trade-offs in the design choices of RAG architectures. The metrics of RAGChecker can guide researchers and practitioners in developing more effective RAG systems.
Towards a Holistic Evaluation of LLMs on Factual Knowledge Recall
Apr 24, 2024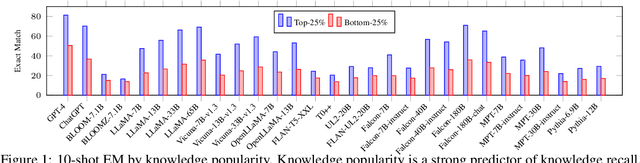



Large language models (LLMs) have shown remarkable performance on a variety of NLP tasks, and are being rapidly adopted in a wide range of use cases. It is therefore of vital importance to holistically evaluate the factuality of their generated outputs, as hallucinations remain a challenging issue. In this work, we focus on assessing LLMs' ability to recall factual knowledge learned from pretraining, and the factors that affect this ability. To that end, we construct FACT-BENCH, a representative benchmark covering 20 domains, 134 property types, 3 answer types, and different knowledge popularity levels. We benchmark 31 models from 10 model families and provide a holistic assessment of their strengths and weaknesses. We observe that instruction-tuning hurts knowledge recall, as pretraining-only models consistently outperform their instruction-tuned counterparts, and positive effects of model scaling, as larger models outperform smaller ones for all model families. However, the best performance from GPT-4 still represents a large gap with the upper-bound. We additionally study the role of in-context exemplars using counterfactual demonstrations, which lead to significant degradation of factual knowledge recall for large models. By further decoupling model known and unknown knowledge, we find the degradation is attributed to exemplars that contradict a model's known knowledge, as well as the number of such exemplars. Lastly, we fine-tune LLaMA-7B in different settings of known and unknown knowledge. In particular, fine-tuning on a model's known knowledge is beneficial, and consistently outperforms fine-tuning on unknown and mixed knowledge. We will make our benchmark publicly available.
Propagation and Pitfalls: Reasoning-based Assessment of Knowledge Editing through Counterfactual Tasks
Jan 31, 2024Current approaches of knowledge editing struggle to effectively propagate updates to interconnected facts. In this work, we delve into the barriers that hinder the appropriate propagation of updated knowledge within these models for accurate reasoning. To support our analysis, we introduce a novel reasoning-based benchmark -- ReCoE (Reasoning-based Counterfactual Editing dataset) -- which covers six common reasoning schemes in real world. We conduct a thorough analysis of existing knowledge editing techniques, including input augmentation, finetuning, and locate-and-edit. We found that all model editing methods show notably low performance on this dataset, especially in certain reasoning schemes. Our analysis over the chain-of-thought generation of edited models further uncover key reasons behind the inadequacy of existing knowledge editing methods from a reasoning standpoint, involving aspects on fact-wise editing, fact recall ability, and coherence in generation. We will make our benchmark publicly available.
Globally Optimal Beamforming Design for Integrated Sensing and Communication Systems
Sep 13, 2023

In this paper, we propose a multi-input multi-output (MIMO) beamforming transmit optimization model for joint radar sensing and multi-user communications, where the design of the beamformers is formulated as an optimization problem whose objective is a weighted combination of the sum rate and the Cram\'{e}r-Rao bound (CRB), subject to the transmit power budget constraint. The formulated problem is challenging to obtain a global solution, because the sum rate maximization (SRM) problem itself (even without considering the sensing metric) is known to be NP-hard. In this paper, we propose an efficient global branch-and-bound algorithm for solving the formulated problem based on the McCormick envelope relaxation and the semidefinite relaxation (SDR) technique. The proposed algorithm is guaranteed to find the global solution for the considered problem, and thus serves as an important benchmark for performance evaluation of the existing local or suboptimal algorithms for solving the same problem.
Few-Shot Data-to-Text Generation via Unified Representation and Multi-Source Learning
Aug 10, 2023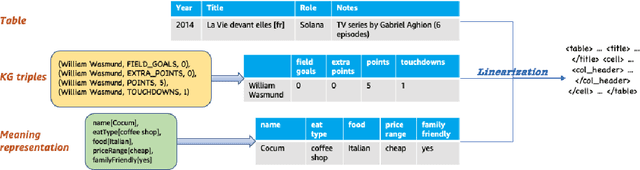



We present a novel approach for structured data-to-text generation that addresses the limitations of existing methods that primarily focus on specific types of structured data. Our proposed method aims to improve performance in multi-task training, zero-shot and few-shot scenarios by providing a unified representation that can handle various forms of structured data such as tables, knowledge graph triples, and meaning representations. We demonstrate that our proposed approach can effectively adapt to new structured forms, and can improve performance in comparison to current methods. For example, our method resulted in a 66% improvement in zero-shot BLEU scores when transferring models trained on table inputs to a knowledge graph dataset. Our proposed method is an important step towards a more general data-to-text generation framework.