 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Resolve Semantic Discrepancy in Self-Destructive Subcultures? Evidence from Jirai Kei
Jan 08, 2026Self-destructive behaviors are linked to complex psychological states and can be challenging to diagnose. These behaviors may be even harder to identify within subcultural groups due to their unique expressions. As large language models (LLMs) are applied across various fields, some researchers have begun exploring their application for detecting self-destructive behaviors. Motivated by this, we investigate self-destructive behavior detection within subcultures using current LLM-based methods. However, these methods have two main challenges: (1) Knowledge Lag: Subcultural slang evolves rapidly, faster than LLMs' training cycles; and (2) Semantic Misalignment: it is challenging to grasp the specific and nuanced expressions unique to subcultures. To address these issues, we proposed Subcultural Alignment Solver (SAS), a multi-agent framework that incorporates automatic retrieval and subculture alignment, significantly enhancing the performance of LLMs in detecting self-destructive behavior. Our experimental results show that SAS outperforms the current advanced multi-agent framework OWL. Notably, it competes well with fine-tuned LLMs. We hope that SAS will advance the field of self-destructive behavior detection in subcultural contexts and serve as a valuable resource for future researchers.
Why Chain of Thought Fails in Clinical Text Understanding
Sep 26, 2025Large language models (LLMs) are increasingly being applied to clinical care, a domain where both accuracy and transparent reasoning are critical for safe and trustworthy deployment. Chain-of-thought (CoT) prompting, which elicits step-by-step reasoning, has demonstrated improvements in performance and interpretability across a wide range of tasks. However, its effectiveness in clinical contexts remains largely unexplored, particularly in the context of electronic health records (EHRs), the primary source of clinical documentation, which are often lengthy, fragmented, and noisy. In this work, we present the first large-scale systematic study of CoT for clinical text understanding. We assess 95 advanced LLMs on 87 real-world clinical text tasks, covering 9 languages and 8 task types. Contrary to prior findings in other domains, we observe that 86.3\% of models suffer consistent performance degradation in the CoT setting. More capable models remain relatively robust, while weaker ones suffer substantial declines. To better characterize these effects, we perform fine-grained analyses of reasoning length, medical concept alignment, and error profiles, leveraging both LLM-as-a-judge evaluation and clinical expert evaluation. Our results uncover systematic patterns in when and why CoT fails in clinical contexts, which highlight a critical paradox: CoT enhances interpretability but may undermine reliability in clinical text tasks. This work provides an empirical basis for clinical reasoning strategies of LLMs, highlighting the need for transparent and trustworthy approaches.
BRIDGE: Benchmarking Large Language Models for Understanding Real-world Clinical Practice Text
May 01, 2025



Large language models (LLMs) hold great promise for medical applications and are evolving rapidly, with new models being released at an accelerated pace. However, current evaluations of LLMs in clinical contexts remain limited. Most existing benchmarks rely on medical exam-style questions or PubMed-derived text, failing to capture the complexity of real-world electronic health record (EHR) data. Others focus narrowly on specific application scenarios, limiting their generalizability across broader clinical use. To address this gap, we present BRIDGE, a comprehensive multilingual benchmark comprising 87 tasks sourced from real-world clinical data sources across nine languages. We systematically evaluated 52 state-of-the-art LLMs (including DeepSeek-R1, GPT-4o, Gemini, and Llama 4) under various inference strategies. With a total of 13,572 experiments, our results reveal substantial performance variation across model sizes, languages, natural language processing tasks, and clinical specialties. Notably, we demonstrate that open-source LLMs can achieve performance comparable to proprietary models, while medically fine-tuned LLMs based on older architectures often underperform versus updated general-purpose models. The BRIDGE and its corresponding leaderboard serve as a foundational resource and a unique reference for the development and evaluation of new LLMs in real-world clinical text understanding. The BRIDGE leaderboard: https://huggingface.co/spaces/YLab-Open/BRIDGE-Medical-Leaderboard
A New Adaptive Balanced Augmented Lagrangian Method with Application to ISAC Beamforming Design
Oct 20, 2024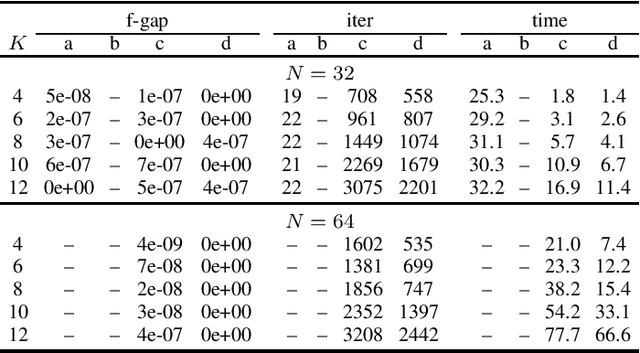
In this paper, we consider a class of convex programming problems with linear equality constraints, which finds broad applications in machine learning and signal processing. We propose a new adaptive balanced augmented Lagrangian (ABAL) method for solving these problems. The proposed ABAL method adaptively selects the stepsize parameter and enjoys a low per-iteration complexity, involving only the computation of a proximal mapping of the objective function and the solution of a linear equation. These features make the proposed method well-suited to large-scale problems. We then custom-apply the ABAL method to solve the ISAC beamforming design problem, which is formulated as a nonlinear semidefinite program in a previous work. This customized application requires careful exploitation of the problem's special structure such as the property that all of its signal-to-interference-and-noise-ratio (SINR) constraints hold with equality at the solution and an efficient computation of the proximal mapping of the objective function. Simulation results demonstrate the efficiency of the proposed ABAL method.
Revealing COVID-19's Social Dynamics: Diachronic Semantic Analysis of Vaccine and Symptom Discourse on Twitter
Oct 10, 2024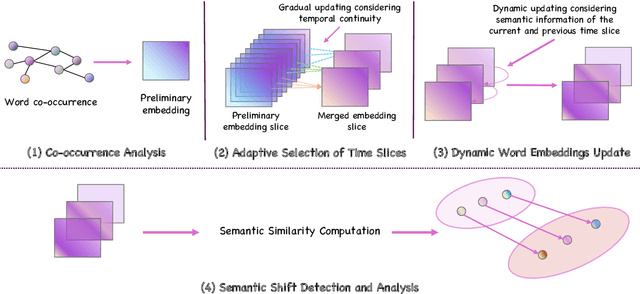
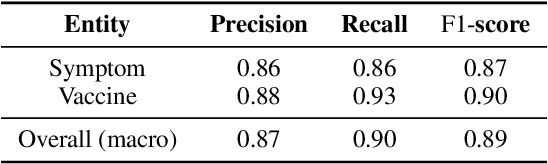

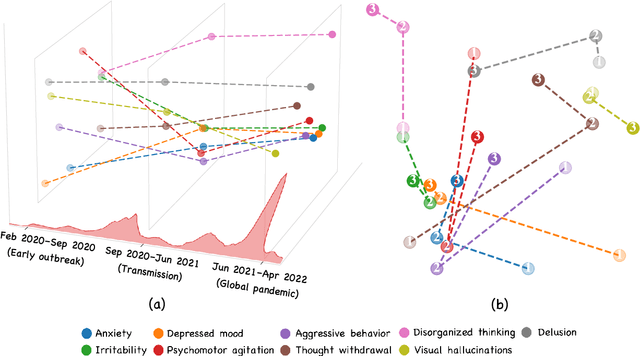
Social media is recognized as an important source for deriving insights into public opinion dynamics and social impacts due to the vast textual data generated daily and the 'unconstrained' behavior of people interacting on these platforms. However, such analyses prove challenging due to the semantic shift phenomenon, where word meanings evolve over time. This paper proposes an unsupervised dynamic word embedding method to capture longitudinal semantic shifts in social media data without predefined anchor words. The method leverages word co-occurrence statistics and dynamic updating to adapt embeddings over time, addressing the challenges of data sparseness, imbalanced distributions, and synergistic semantic effects. Evaluated on a large COVID-19 Twitter dataset, the method reveals semantic evolution patterns of vaccine- and symptom-related entities across different pandemic stages, and their potential correlations with real-world statistics. Our key contributions include the dynamic embedding technique, empirical analysis of COVID-19 semantic shifts, and discussions on enhancing semantic shift modeling for computational social science research. This study enables capturing longitudinal semantic dynamics on social media to understand public discourse and collective phenomena.
FinTruthQA: A Benchmark Dataset for Evaluating the Quality of Financial Information Disclosure
Jun 17, 2024Accurate and transparent financial information disclosure is crucial in the fields of accounting and finance, ensuring market efficiency and investor confidence. Among many information disclosure platforms, the Chinese stock exchanges' investor interactive platform provides a novel and interactive way for listed firms to disclose information of interest to investors through an online question-and-answer (Q&A) format. However, it is common for listed firms to respond to questions with limited or no substantive information, and automatically evaluating the quality of financial information disclosure on large amounts of Q&A pairs is challenging. This paper builds a benchmark FinTruthQA, that can evaluate advanced natural language processing (NLP) techniques for the automatic quality assessment of information disclosure in financial Q&A data. FinTruthQA comprises 6,000 real-world financial Q&A entries and each Q&A was manually annotated based on four conceptual dimensions of accounting. We benchmarked various NLP techniques on FinTruthQA, including statistical machine learning models, pre-trained language model and their fine-tuned versions, as well as the large language model GPT-4. Experiments showed that existing NLP models have strong predictive ability for real question identification and question relevance tasks, but are suboptimal for answer relevance and answer readability tasks. By establishing this benchmark, we provide a robust foundation for the automatic evaluation of information disclosure, significantly enhancing the transparency and quality of financial reporting. FinTruthQA can be used by auditors, regulators, and financial analysts for real-time monitoring and data-driven decision-making, as well as by researchers for advanced studies in accounting and finance, ultimately fostering greater trust and efficiency in the financial markets.
MedKP: Medical Dialogue with Knowledge Enhancement and Clinical Pathway Encoding
Mar 11, 2024



With appropriate data selection and training techniques, Large Language Models (LLMs) have demonstrated exceptional success in various medical examinations and multiple-choice questions. However, the application of LLMs in medical dialogue generation-a task more closely aligned with actual medical practice-has been less explored. This gap is attributed to the insufficient medical knowledge of LLMs, which leads to inaccuracies and hallucinated information in the generated medical responses. In this work, we introduce the Medical dialogue with Knowledge enhancement and clinical Pathway encoding (MedKP) framework, which integrates an external knowledge enhancement module through a medical knowledge graph and an internal clinical pathway encoding via medical entities and physician actions. Evaluated with comprehensive metrics, our experiments on two large-scale, real-world online medical consultation datasets (MedDG and KaMed) demonstrate that MedKP surpasses multiple baselines and mitigates the incidence of hallucinations, achieving a new state-of-the-art. Extensive ablation studies further reveal the effectiveness of each component of MedKP. This enhancement advances the development of reliable, automated medical consultation responses using LLMs, thereby broadening the potential accessibility of precise and real-time medical assistance.
Globally Optimal Beamforming Design for Integrated Sensing and Communication Systems
Sep 13, 2023

In this paper, we propose a multi-input multi-output (MIMO) beamforming transmit optimization model for joint radar sensing and multi-user communications, where the design of the beamformers is formulated as an optimization problem whose objective is a weighted combination of the sum rate and the Cram\'{e}r-Rao bound (CRB), subject to the transmit power budget constraint. The formulated problem is challenging to obtain a global solution, because the sum rate maximization (SRM) problem itself (even without considering the sensing metric) is known to be NP-hard. In this paper, we propose an efficient global branch-and-bound algorithm for solving the formulated problem based on the McCormick envelope relaxation and the semidefinite relaxation (SDR) technique. The proposed algorithm is guaranteed to find the global solution for the considered problem, and thus serves as an important benchmark for performance evaluation of the existing local or suboptimal algorithms for solving the same problem.
Qualifying Chinese Medical Licensing Examination with Knowledge Enhanced Generative Pre-training Model
May 17, 2023Generative Pre-Training (GPT) models like ChatGPT have demonstrated exceptional performance in various Natural Language Processing (NLP) tasks. Although ChatGPT has been integrated into the overall workflow to boost efficiency in many domains, the lack of flexibility in the finetuning process hinders its applications in areas that demand extensive domain expertise and semantic knowledge, such as healthcare. In this paper, we evaluate ChatGPT on the China National Medical Licensing Examination (CNMLE) and propose a novel approach to improve ChatGPT from two perspectives: integrating medical domain knowledge and enabling few-shot learning. By using a simple but effective retrieval method, medical background knowledge is extracted as semantic instructions to guide the inference of ChatGPT. Similarly, relevant medical questions are identified and fed as demonstrations to ChatGPT. Experimental results show that directly applying ChatGPT fails to qualify the CNMLE at a score of 51 (i.e., only 51\% of questions are answered correctly). While our knowledge-enhanced model achieves a high score of 70 on CNMLE-2022 which not only passes the qualification but also surpasses the average score of humans (61). This research demonstrates the potential of knowledge-enhanced ChatGPT to serve as versatile medical assistants, capable of analyzing real-world medical problems in a more accessible, user-friendly, and adaptable manner.
Exploring Social Media for Early Detection of Depression in COVID-19 Patients
Feb 23, 2023



The COVID-19 pandemic has caused substantial damage to global health. Even though three years have passed, the world continues to struggle with the virus. Concerns are growing about the impact of COVID-19 on the mental health of infected individuals, who are more likely to experience depression, which can have long-lasting consequences for both the affected individuals and the world. Detection and intervention at an early stage can reduce the risk of depression in COVID-19 patients. In this paper, we investigated the relationship between COVID-19 infection and depression through social media analysis. Firstly, we managed a dataset of COVID-19 patients that contains information about their social media activity both before and after infection. Secondly,We conducted an extensive analysis of this dataset to investigate the characteristic of COVID-19 patients with a higher risk of depression. Thirdly, we proposed a deep neural network for early prediction of depression risk. This model considers daily mood swings as a psychiatric signal and incorporates textual and emotional characteristics via knowledge distillation. Experimental results demonstrate that our proposed framework outperforms baselines in detecting depression risk, with an AUROC of 0.9317 and an AUPRC of 0.8116. Our model has the potential to enable public health organizations to initiate prompt intervention with high-risk patients