 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Table Comprehension In The Wild
Dec 13, 2024



Large Language Models (LLMs), while being increasingly dominant on a myriad of knowledge-intensive activities, have only had limited success understanding lengthy table-text mixtures, such as academic papers and financial reports. Recent advances of long-context LLMs have opened up new possibilities for this field. Nonetheless, we identify two roadblocks: (1) Prior benchmarks of table question answering (TableQA) have focused on isolated tables without context, making it hard to evaluate models in real-world scenarios. (2) Prior benchmarks have focused on some narrow skill sets of table comprehension such as table recognition, data manipulation/calculation, table summarization etc., while a skilled human employs those skills collectively. In this work, we introduce TableQuest, a new benchmark designed to evaluate the holistic table comprehension capabilities of LLMs in the natural table-rich context of financial reports. We employ a rigorous data processing and filtering procedure to ensure that the question-answer pairs are logical, reasonable, and diverse. We experiment with 7 state-of-the-art models, and find that despite reasonable accuracy in locating facts, they often falter when required to execute more sophisticated reasoning or multi-step calculations. We conclude with a qualitative study of the failure modes and discuss the challenges of constructing a challenging benchmark. We make the evaluation data, judging procedure and results of this study publicly available to facilitate research in this field.
On the Risk of Misinformation Pollution with Large Language Models
May 23, 2023In this paper, we comprehensively investigate the potential misuse of modern Large Language Models (LLMs) for generating credible-sounding misinformation and its subsequent impact on information-intensive applications, particularly Open-Domain Question Answering (ODQA) systems. We establish a threat model and simulate potential misuse scenarios, both unintentional and intentional, to assess the extent to which LLMs can be utilized to produce misinformation. Our study reveals that LLMs can act as effective misinformation generators, leading to a significant degradation in the performance of ODQA systems. To mitigate the harm caused by LLM-generated misinformation, we explore three defense strategies: prompting, misinformation detection, and majority voting. While initial results show promising trends for these defensive strategies, much more work needs to be done to address the challenge of misinformation pollution. Our work highlights the need for further research and interdisciplinary collaboration to address LLM-generated misinformation and to promote responsible use of LLMs.
GreenPLM: Cross-lingual pre-trained language models conversion with (almost) no cost
Nov 13, 2022
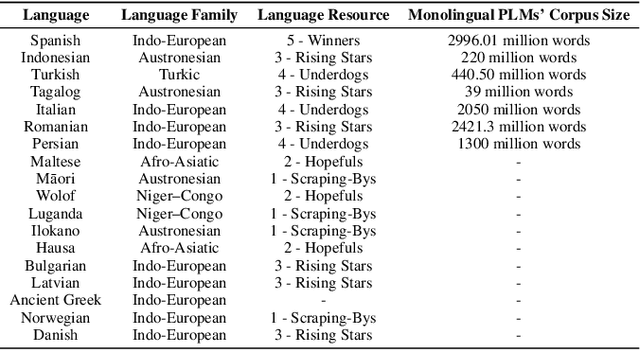


While large pre-trained models have transformed the field of natural language processing (NLP), the high training cost and low cross-lingual availability of such models prevent the new advances from being equally shared by users across all languages, especially the less spoken ones. To promote equal opportunities for all language speakers in NLP research and to reduce energy consumption for sustainability, this study proposes an effective and energy-efficient framework GreenPLM that uses bilingual lexicons to directly translate language models of one language into other languages at (almost) no additional cost. We validate this approach in 18 languages and show that this framework is comparable to, if not better than, other heuristics trained with high cost. In addition, when given a low computational cost (2.5%), the framework outperforms the original monolingual language models in six out of seven tested languages. This approach can be easily implemented, and we will release language models in 50 languages translated from English soon.