 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Visual Attribute Effects in Advertising from Observational Data: A Deepfake-Informed Double Machine Learning Approach
Mar 02, 2026Digital advertising increasingly relies on visual content, yet marketers lack rigorous methods for understanding how specific visual attributes causally affect consumer engagement. This paper addresses a fundamental methodological challenge: estimating causal effects when the treatment, such as a model's skin tone, is an attribute embedded within the image itself. Standard approaches like Double Machine Learning (DML) fail in this setting because vision encoders entangle treatment information with confounding variables, producing severely biased estimates. We develop DICE-DML (Deepfake-Informed Control Encoder for Double Machine Learning), a framework that leverages generative AI to disentangle treatment from confounders. The approach combines three mechanisms: (1) deepfake-generated image pairs that isolate treatment variation; (2) DICE-Diff adversarial learning on paired difference vectors, where background signals cancel to reveal pure treatment fingerprints; and (3) orthogonal projection that geometrically removes treatment-axis components. In simulations with known ground truth, DICE-DML reduces root mean squared error by 73-97% compared to standard DML, with the strongest improvement (97.5%) at the null effect point, demonstrating robust Type I error control. Applying DICE-DML to 232,089 Instagram influencer posts, we estimate the causal effect of skin tone on engagement. Standard DML produces diagnostically invalid results (negative outcome R^2), while DICE-DML achieves valid confounding control (R^2 = 0.63) and estimates a marginally significant negative effect of darker skin tone (-522 likes; p = 0.062), substantially smaller than the biased standard estimate. Our framework provides a principled approach for causal inference with visual data when treatments and confounders coexist within images.
Avoiding Premature Collapse: Adaptive Annealing for Entropy-Regularized Structural Inference
Jan 30, 2026Differentiable matching layers, often implemented via entropy-regularized Optimal Transport, serve as a critical approximate inference mechanism in structural prediction. However, recovering discrete permutations via annealing $ε\to 0$ is notoriously unstable. We identify a fundamental mechanism for this failure: \textbf{Premature Mode Collapse}. By analyzing the non-normal dynamics of the Sinkhorn fixed-point map, we reveal a theoretical \textbf{thermodynamic speed limit}. Under standard exponential cooling, the shift in the target posterior ($O(1)$) outpaces the contraction rate of the inference operator, which degrades as $O(1/ε)$. This mismatch inevitably forces the inference trajectory into spurious local basins. To address this, we propose \textbf{Efficient PH-ASC}, an adaptive scheduling algorithm that monitors the stability of the inference process. By enforcing a linear stability law, we decouple expensive spectral diagnostics from the training loop, reducing overhead from $O(N^3)$ to amortized $O(1)$. Our implementation and interactive demo are available at https://github.com/xxx0438/torch-sinkhorn-asc and https://huggingface.co/spaces/leon0923/torch-sinkhorn-asc-demo. bounded away from zero in generic training dynamics unless the feature extractor converges unrealistically fast.
The Homogeneity Trap: Spectral Collapse in Doubly-Stochastic Deep Networks
Jan 05, 2026Doubly-stochastic matrices (DSM) are increasingly utilized in structure-preserving deep architectures -- such as Optimal Transport layers and Sinkhorn-based attention -- to enforce numerical stability and probabilistic interpretability. In this work, we identify a critical spectral degradation phenomenon inherent to these constraints, termed the Homogeneity Trap. We demonstrate that the maximum-entropy bias, typical of Sinkhorn-based projections, drives the mixing operator towards the uniform barycenter, thereby suppressing the subdominant singular value σ_2 and filtering out high-frequency feature components. We derive a spectral bound linking σ_2 to the network's effective depth, showing that high-entropy constraints restrict feature transformation to a shallow effective receptive field. Furthermore, we formally demonstrate that Layer Normalization fails to mitigate this collapse in noise-dominated regimes; specifically, when spectral filtering degrades the Signal-to-Noise Ratio (SNR) below a critical threshold, geometric structure is irreversibly lost to noise-induced orthogonal collapse. Our findings highlight a fundamental trade-off between entropic stability and spectral expressivity in DSM-constrained networks.
Neighbor-aware Instance Refining with Noisy Labels for Cross-Modal Retrieval
Dec 30, 2025In recent years, Cross-Modal Retrieval (CMR) has made significant progress in the field of multi-modal analysis. However, since it is time-consuming and labor-intensive to collect large-scale and well-annotated data, the annotation of multi-modal data inevitably contains some noise. This will degrade the retrieval performance of the model. To tackle the problem, numerous robust CMR methods have been developed, including robust learning paradigms, label calibration strategies, and instance selection mechanisms. Unfortunately, they often fail to simultaneously satisfy model performance ceilings, calibration reliability, and data utilization rate. To overcome the limitations, we propose a novel robust cross-modal learning framework, namely Neighbor-aware Instance Refining with Noisy Labels (NIRNL). Specifically, we first propose Cross-modal Margin Preserving (CMP) to adjust the relative distance between positive and negative pairs, thereby enhancing the discrimination between sample pairs. Then, we propose Neighbor-aware Instance Refining (NIR) to identify pure subset, hard subset, and noisy subset through cross-modal neighborhood consensus. Afterward, we construct different tailored optimization strategies for this fine-grained partitioning, thereby maximizing the utilization of all available data while mitigating error propagation. Extensive experiments on three benchmark datasets demonstrate that NIRNL achieves state-of-the-art performance, exhibiting remarkable robustness, especially under high noise rates.
Benchmarking Table Comprehension In The Wild
Dec 13, 2024



Large Language Models (LLMs), while being increasingly dominant on a myriad of knowledge-intensive activities, have only had limited success understanding lengthy table-text mixtures, such as academic papers and financial reports. Recent advances of long-context LLMs have opened up new possibilities for this field. Nonetheless, we identify two roadblocks: (1) Prior benchmarks of table question answering (TableQA) have focused on isolated tables without context, making it hard to evaluate models in real-world scenarios. (2) Prior benchmarks have focused on some narrow skill sets of table comprehension such as table recognition, data manipulation/calculation, table summarization etc., while a skilled human employs those skills collectively. In this work, we introduce TableQuest, a new benchmark designed to evaluate the holistic table comprehension capabilities of LLMs in the natural table-rich context of financial reports. We employ a rigorous data processing and filtering procedure to ensure that the question-answer pairs are logical, reasonable, and diverse. We experiment with 7 state-of-the-art models, and find that despite reasonable accuracy in locating facts, they often falter when required to execute more sophisticated reasoning or multi-step calculations. We conclude with a qualitative study of the failure modes and discuss the challenges of constructing a challenging benchmark. We make the evaluation data, judging procedure and results of this study publicly available to facilitate research in this field.
People Talking and AI Listening: How Stigmatizing Language in EHR Notes Affect AI Performance
May 17, 2023

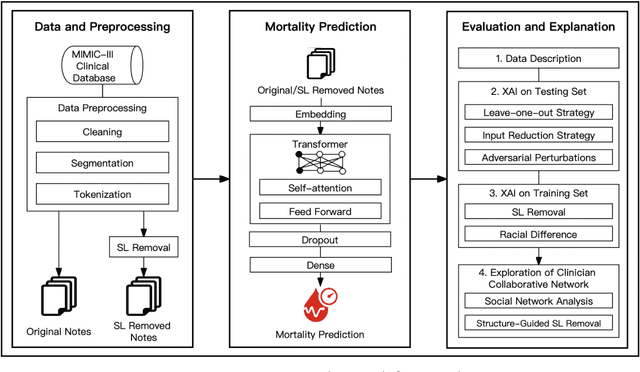
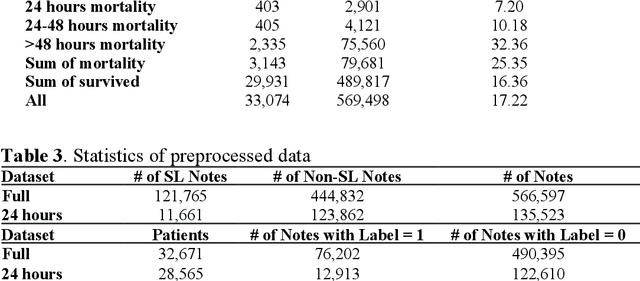
Electronic health records (EHRs) serve as an essential data source for the envisioned artificial intelligence (AI)-driven transformation in healthcare. However, clinician biases reflected in EHR notes can lead to AI models inheriting and amplifying these biases, perpetuating health disparities. This study investigates the impact of stigmatizing language (SL) in EHR notes on mortality prediction using a Transformer-based deep learning model and explainable AI (XAI) techniques. Our findings demonstrate that SL written by clinicians adversely affects AI performance, particularly so for black patients, highlighting SL as a source of racial disparity in AI model development. To explore an operationally efficient way to mitigate SL's impact, we investigate patterns in the generation of SL through a clinicians' collaborative network, identifying central clinicians as having a stronger impact on racial disparity in the AI model. We find that removing SL written by central clinicians is a more efficient bias reduction strategy than eliminating all SL in the entire corpus of data. This study provides actionable insights for responsible AI development and contributes to understanding clinician behavior and EHR note writing in healthcare.
RAF: Holistic Compilation for Deep Learning Model Training
Mar 08, 2023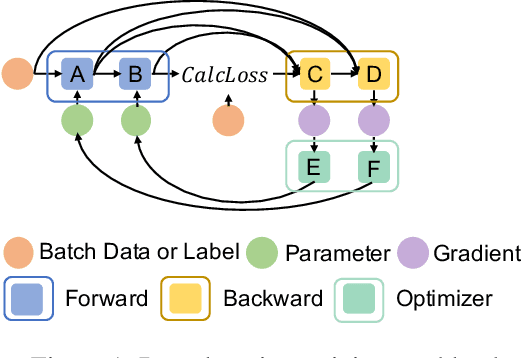
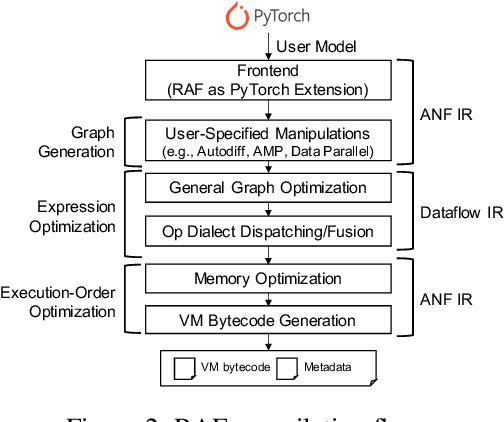

As deep learning is pervasive in modern applications, many deep learning frameworks are presented for deep learning practitioners to develop and train DNN models rapidly. Meanwhile, as training large deep learning models becomes a trend in recent years, the training throughput and memory footprint are getting crucial. Accordingly, optimizing training workloads with compiler optimizations is inevitable and getting more and more attentions. However, existing deep learning compilers (DLCs) mainly target inference and do not incorporate holistic optimizations, such as automatic differentiation and automatic mixed precision, in training workloads. In this paper, we present RAF, a deep learning compiler for training. Unlike existing DLCs, RAF accepts a forward model and in-house generates a training graph. Accordingly, RAF is able to systematically consolidate graph optimizations for performance, memory and distributed training. In addition, to catch up to the state-of-the-art performance with hand-crafted kernel libraries as well as tensor compilers, RAF proposes an operator dialect mechanism to seamlessly integrate all possible kernel implementations. We demonstrate that by in-house training graph generation and operator dialect mechanism, we are able to perform holistic optimizations and achieve either better training throughput or larger batch size against PyTorch (eager and torchscript mode), XLA, and DeepSpeed for popular transformer models on GPUs.
Hidet: Task Mapping Programming Paradigm for Deep Learning Tensor Programs
Oct 18, 2022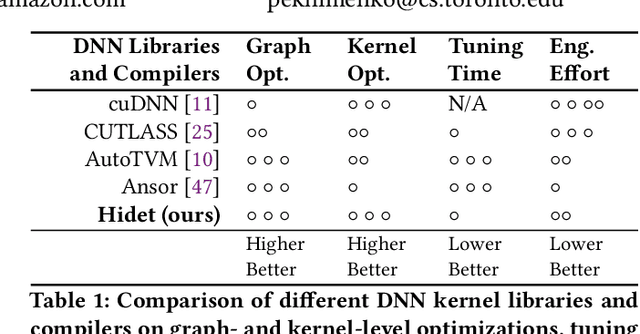
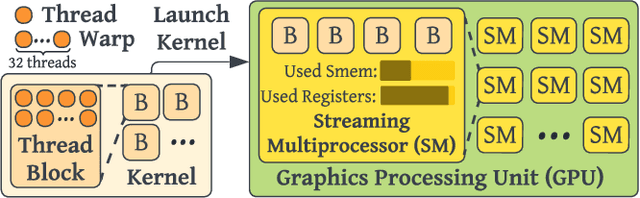
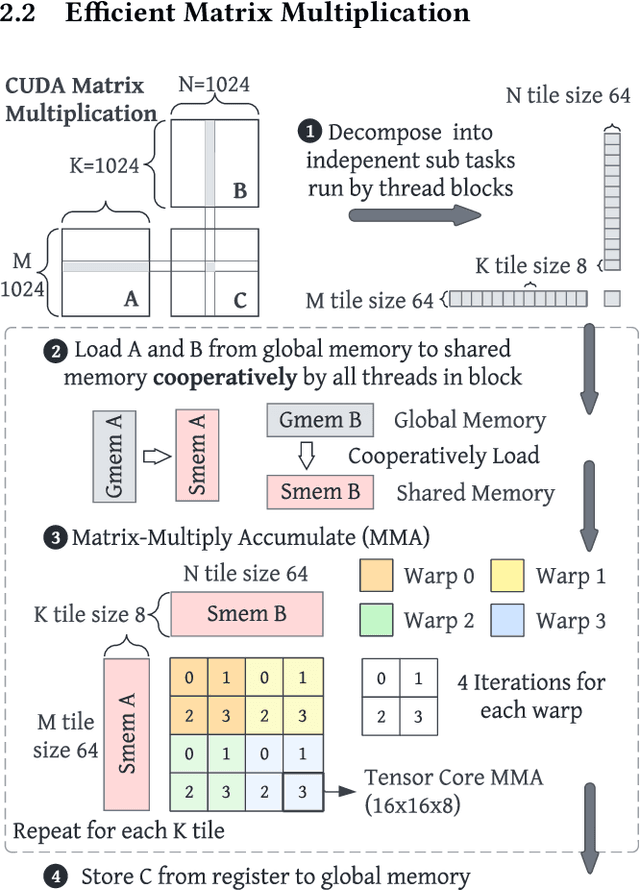
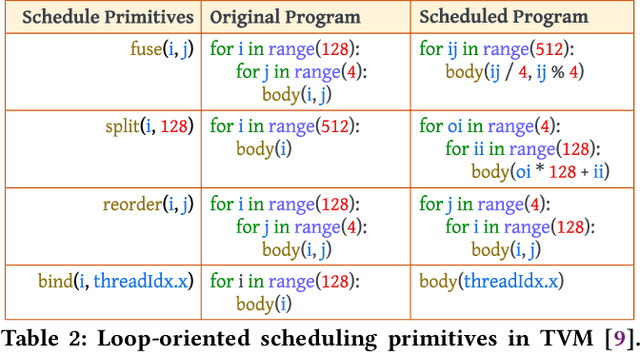
As deep learning models nowadays are widely adopted by both cloud services and edge devices, the latency of deep learning model inferences becomes crucial to provide efficient model serving. However, it is challenging to develop efficient tensor programs for deep learning operators due to the high complexity of modern accelerators (e.g., NVIDIA GPUs and Google TPUs) and the rapidly growing number of operators. Deep learning compilers, such as Apache TVM, adopt declarative scheduling primitives to lower the bar of developing tensor programs. However, we show that this approach is insufficient to cover state-of-the-art tensor program optimizations (e.g., double buffering). In this paper, we propose to embed the scheduling process into tensor programs and use dedicated mappings, called task mappings, to define the computation assignment and ordering directly in the tensor programs. This new approach greatly enriches the expressible optimizations by allowing developers to manipulate tensor programs at a much finer granularity (e.g., allowing program statement-level optimizations). We call the proposed method the task-mapping-oriented programming paradigm. With the proposed paradigm, we implement a deep learning compiler - Hidet. Extensive experiments on modern convolution and transformer models show that Hidet outperforms state-of-the-art DNN inference framework, ONNX Runtime, and compiler, TVM equipped with scheduler AutoTVM and Ansor, by up to 1.48x (1.22x on average) with enriched optimizations. It also reduces the tuning time by 20x and 11x compared with AutoTVM and Ansor, respectively.
Automated PII Extraction from Social Media for Raising Privacy Awareness: A Deep Transfer Learning Approach
Nov 11, 2021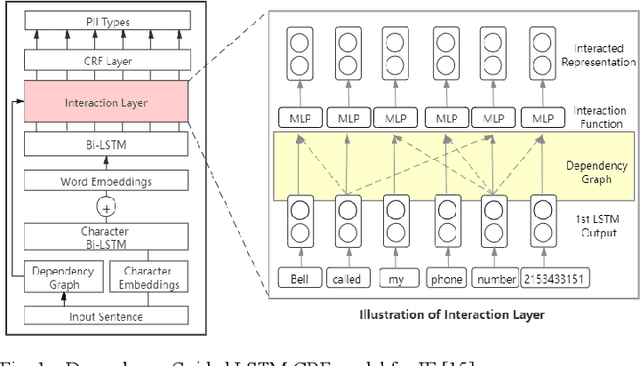
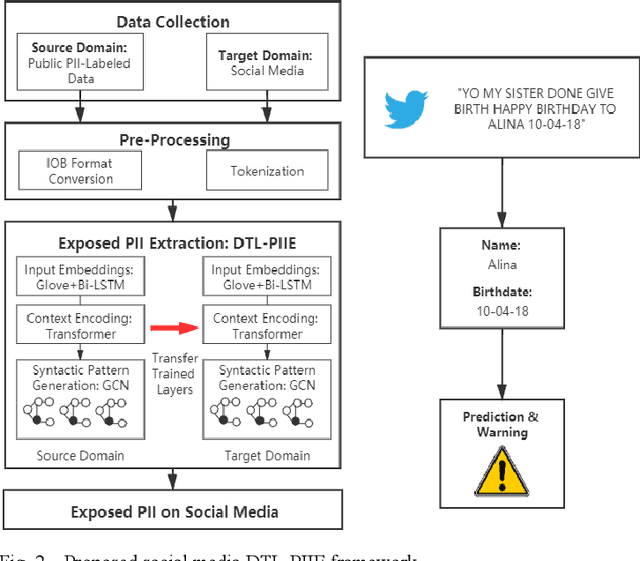
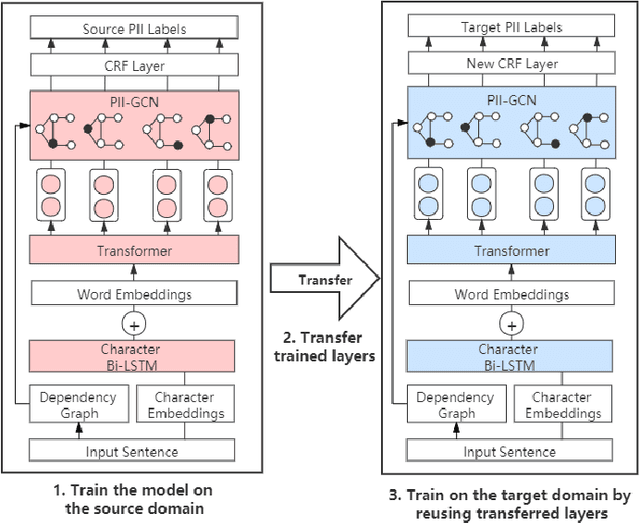
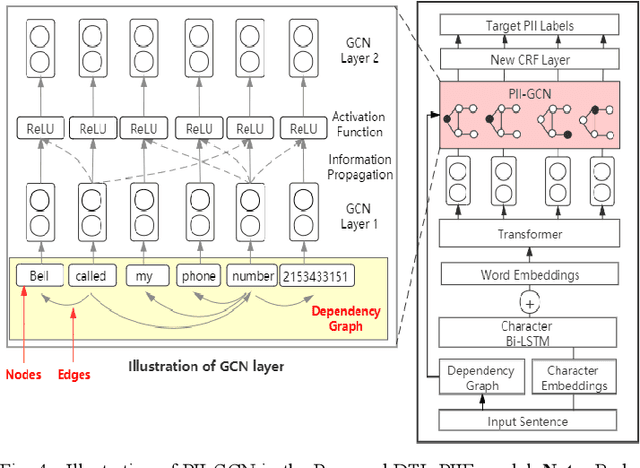
Internet users have been exposing an increasing amount of Personally Identifiable Information (PII) on social media. Such exposed PII can cause severe losses to the users, and informing users of their PII exposure is crucial to raise their privacy awareness and encourage them to take protective measures. To this end, advanced automatic techniques are needed. While Information Extraction (IE) techniques can be used to extract the PII automatically, Deep Learning (DL)-based IE models alleviate the need for feature engineering and further improve the efficiency. However, DL-based IE models often require large-scale labeled data for training, but PII-labeled social media posts are difficult to obtain due to privacy concerns. Also, these models rely heavily on pre-trained word embeddings, while PII in social media often varies in forms and thus has no fixed representations in pre-trained word embeddings. In this study, we propose the Deep Transfer Learning for PII Extraction (DTL-PIIE) framework to address these two limitations. DTL-PIIE transfers knowledge learned from publicly available PII data to social media to address the problem of rare PII-labeled data. Moreover, our framework leverages Graph Convolutional Networks (GCNs) to incorporate syntactic patterns to guide PIIE without relying on pre-trained word embeddings. Evaluation against benchmark IE models indicates that our approach outperforms state-of-the-art DL-based IE models. Our framework can facilitate various applications, such as PII misuse prediction and privacy risk assessment, protecting the privacy of internet users.
Optimizing Memory-Access Patterns for Deep Learning Accelerators
Feb 27, 2020Deep learning (DL) workloads are moving towards accelerators for faster processing and lower cost. Modern DL accelerators are good at handling the large-scale multiply-accumulate operations that dominate DL workloads; however, it is challenging to make full use of the compute power of an accelerator since the data must be properly staged in a software-managed scratchpad memory. Failing to do so can result in significant performance loss. This paper proposes a systematic approach which leverages the polyhedral model to analyze all operators of a DL model together to minimize the number of memory accesses. Experiments show that our approach can substantially reduce the impact of memory accesses required by common neural-network models on a homegrown AWS machine-learning inference chip named Inferentia, which is available through Amazon EC2 Inf1 instances.