 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeople Talking and AI Listening: How Stigmatizing Language in EHR Notes Affect AI Performance
May 17, 2023

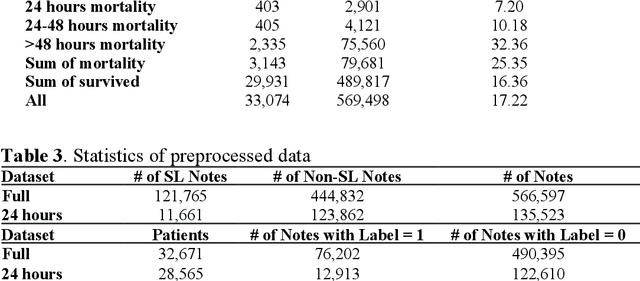
Electronic health records (EHRs) serve as an essential data source for the envisioned artificial intelligence (AI)-driven transformation in healthcare. However, clinician biases reflected in EHR notes can lead to AI models inheriting and amplifying these biases, perpetuating health disparities. This study investigates the impact of stigmatizing language (SL) in EHR notes on mortality prediction using a Transformer-based deep learning model and explainable AI (XAI) techniques. Our findings demonstrate that SL written by clinicians adversely affects AI performance, particularly so for black patients, highlighting SL as a source of racial disparity in AI model development. To explore an operationally efficient way to mitigate SL's impact, we investigate patterns in the generation of SL through a clinicians' collaborative network, identifying central clinicians as having a stronger impact on racial disparity in the AI model. We find that removing SL written by central clinicians is a more efficient bias reduction strategy than eliminating all SL in the entire corpus of data. This study provides actionable insights for responsible AI development and contributes to understanding clinician behavior and EHR note writing in healthcare.
Catch Me If You Can: Identifying Fraudulent Physician Reviews with Large Language Models Using Generative Pre-Trained Transformers
Apr 19, 2023


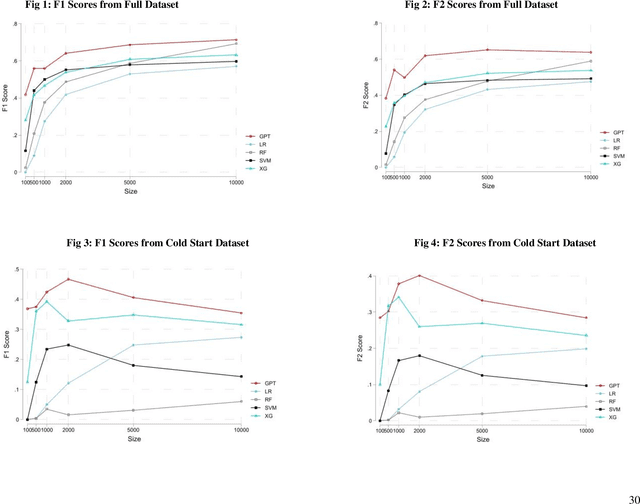
The proliferation of fake reviews of doctors has potentially detrimental consequences for patient well-being and has prompted concern among consumer protection groups and regulatory bodies. Yet despite significant advancements in the fields of machine learning and natural language processing, there remains limited comprehension of the characteristics differentiating fraudulent from authentic reviews. This study utilizes a novel pre-labeled dataset of 38048 physician reviews to establish the effectiveness of large language models in classifying reviews. Specifically, we compare the performance of traditional ML models, such as logistic regression and support vector machines, to generative pre-trained transformer models. Furthermore, we use GPT4, the newest model in the GPT family, to uncover the key dimensions along which fake and genuine physician reviews differ. Our findings reveal significantly superior performance of GPT-3 over traditional ML models in this context. Additionally, our analysis suggests that GPT3 requires a smaller training sample than traditional models, suggesting its appropriateness for tasks with scarce training data. Moreover, the superiority of GPT3 performance increases in the cold start context i.e., when there are no prior reviews of a doctor. Finally, we employ GPT4 to reveal the crucial dimensions that distinguish fake physician reviews. In sharp contrast to previous findings in the literature that were obtained using simulated data, our findings from a real-world dataset show that fake reviews are generally more clinically detailed, more reserved in sentiment, and have better structure and grammar than authentic ones.