 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-aware Diffusion-Enhanced Multimedia Recommendation
Jul 22, 2025



Multimedia recommendations aim to use rich multimedia content to enhance historical user-item interaction information, which can not only indicate the content relatedness among items but also reveal finer-grained preferences of users. In this paper, we propose a Knowledge-aware Diffusion-Enhanced architecture using contrastive learning paradigms (KDiffE) for multimedia recommendations. Specifically, we first utilize original user-item graphs to build an attention-aware matrix into graph neural networks, which can learn the importance between users and items for main view construction. The attention-aware matrix is constructed by adopting a random walk with a restart strategy, which can preserve the importance between users and items to generate aggregation of attention-aware node features. Then, we propose a guided diffusion model to generate strongly task-relevant knowledge graphs with less noise for constructing a knowledge-aware contrastive view, which utilizes user embeddings with an edge connected to an item to guide the generation of strongly task-relevant knowledge graphs for enhancing the item's semantic information. We perform comprehensive experiments on three multimedia datasets that reveal the effectiveness of our KDiffE and its components on various state-of-the-art methods. Our source codes are available https://github.com/1453216158/KDiffE.
Efficient Point Transformer with Dynamic Token Aggregating for Point Cloud Processing
May 23, 2024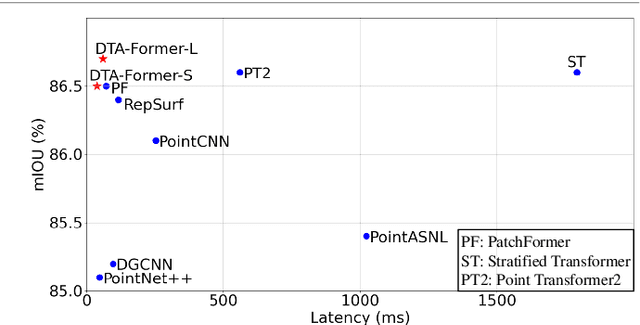
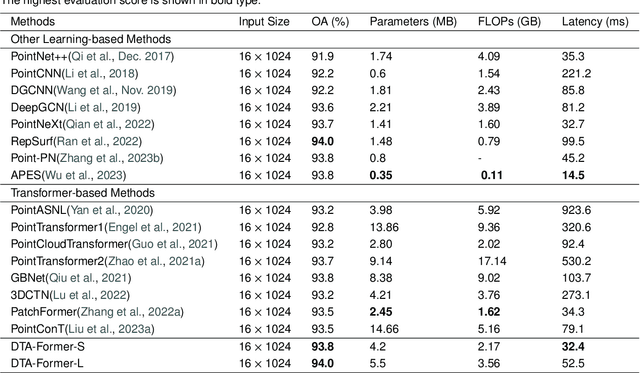
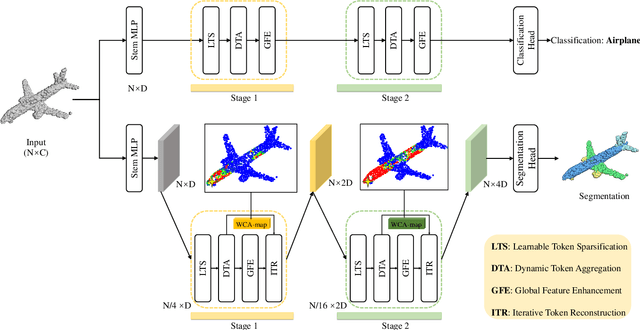
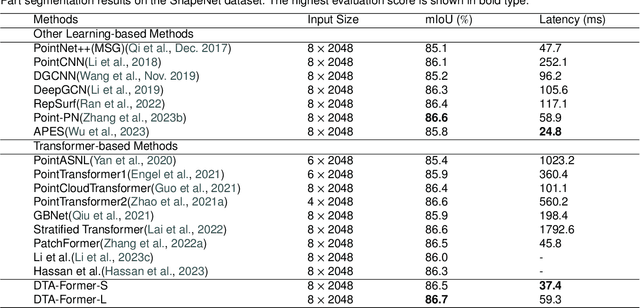
Recently, point cloud processing and analysis have made great progress due to the development of 3D Transformers. However, existing 3D Transformer methods usually are computationally expensive and inefficient due to their huge and redundant attention maps. They also tend to be slow due to requiring time-consuming point cloud sampling and grouping processes. To address these issues, we propose an efficient point TransFormer with Dynamic Token Aggregating (DTA-Former) for point cloud representation and processing. Firstly, we propose an efficient Learnable Token Sparsification (LTS) block, which considers both local and global semantic information for the adaptive selection of key tokens. Secondly, to achieve the feature aggregation for sparsified tokens, we present the first Dynamic Token Aggregating (DTA) block in the 3D Transformer paradigm, providing our model with strong aggregated features while preventing information loss. After that, a dual-attention Transformer-based Global Feature Enhancement (GFE) block is used to improve the representation capability of the model. Equipped with LTS, DTA, and GFE blocks, DTA-Former achieves excellent classification results via hierarchical feature learning. Lastly, a novel Iterative Token Reconstruction (ITR) block is introduced for dense prediction whereby the semantic features of tokens and their semantic relationships are gradually optimized during iterative reconstruction. Based on ITR, we propose a new W-net architecture, which is more suitable for Transformer-based feature learning than the common U-net design. Extensive experiments demonstrate the superiority of our method. It achieves SOTA performance with up to 30$\times$ faster than prior point Transformers on ModelNet40, ShapeNet, and airborne MultiSpectral LiDAR (MS-LiDAR) datasets.
People Talking and AI Listening: How Stigmatizing Language in EHR Notes Affect AI Performance
May 17, 2023

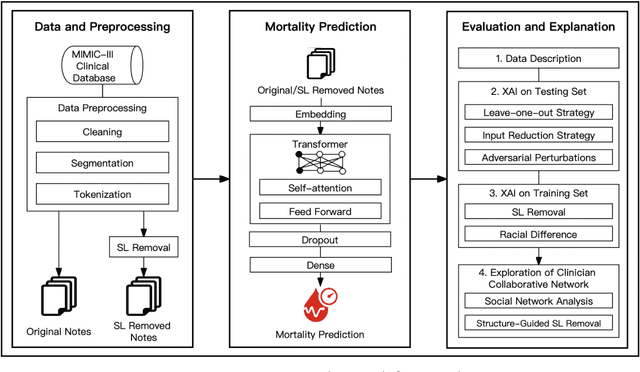
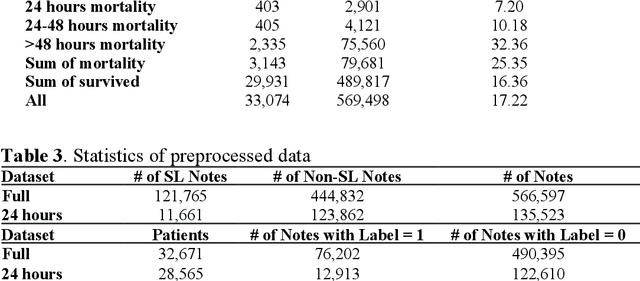
Electronic health records (EHRs) serve as an essential data source for the envisioned artificial intelligence (AI)-driven transformation in healthcare. However, clinician biases reflected in EHR notes can lead to AI models inheriting and amplifying these biases, perpetuating health disparities. This study investigates the impact of stigmatizing language (SL) in EHR notes on mortality prediction using a Transformer-based deep learning model and explainable AI (XAI) techniques. Our findings demonstrate that SL written by clinicians adversely affects AI performance, particularly so for black patients, highlighting SL as a source of racial disparity in AI model development. To explore an operationally efficient way to mitigate SL's impact, we investigate patterns in the generation of SL through a clinicians' collaborative network, identifying central clinicians as having a stronger impact on racial disparity in the AI model. We find that removing SL written by central clinicians is a more efficient bias reduction strategy than eliminating all SL in the entire corpus of data. This study provides actionable insights for responsible AI development and contributes to understanding clinician behavior and EHR note writing in healthcare.
Catch Me If You Can: Identifying Fraudulent Physician Reviews with Large Language Models Using Generative Pre-Trained Transformers
Apr 19, 2023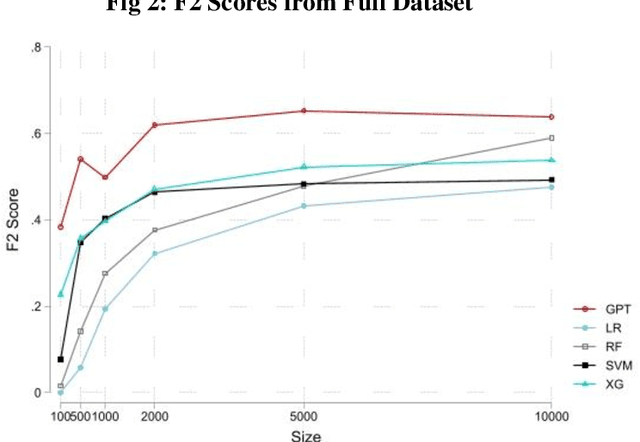


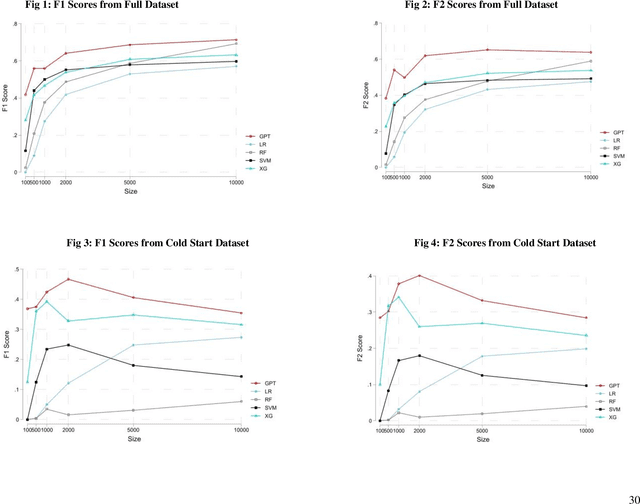
The proliferation of fake reviews of doctors has potentially detrimental consequences for patient well-being and has prompted concern among consumer protection groups and regulatory bodies. Yet despite significant advancements in the fields of machine learning and natural language processing, there remains limited comprehension of the characteristics differentiating fraudulent from authentic reviews. This study utilizes a novel pre-labeled dataset of 38048 physician reviews to establish the effectiveness of large language models in classifying reviews. Specifically, we compare the performance of traditional ML models, such as logistic regression and support vector machines, to generative pre-trained transformer models. Furthermore, we use GPT4, the newest model in the GPT family, to uncover the key dimensions along which fake and genuine physician reviews differ. Our findings reveal significantly superior performance of GPT-3 over traditional ML models in this context. Additionally, our analysis suggests that GPT3 requires a smaller training sample than traditional models, suggesting its appropriateness for tasks with scarce training data. Moreover, the superiority of GPT3 performance increases in the cold start context i.e., when there are no prior reviews of a doctor. Finally, we employ GPT4 to reveal the crucial dimensions that distinguish fake physician reviews. In sharp contrast to previous findings in the literature that were obtained using simulated data, our findings from a real-world dataset show that fake reviews are generally more clinically detailed, more reserved in sentiment, and have better structure and grammar than authentic ones.
Evident: a Development Methodology and a Knowledge Base Topology for Data Mining, Machine Learning and General Knowledge Management
Nov 09, 2022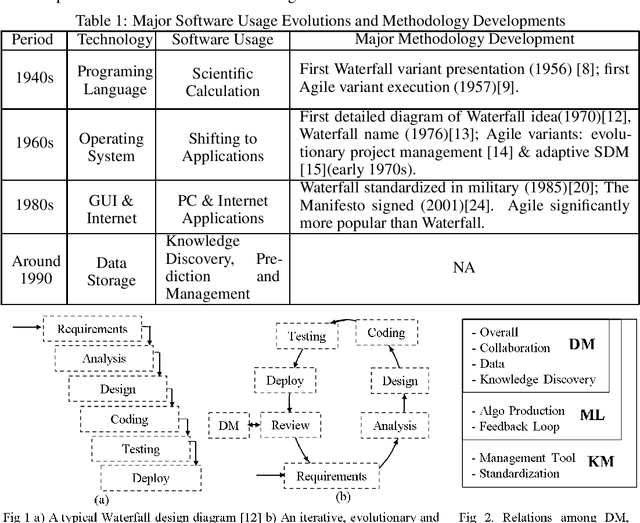
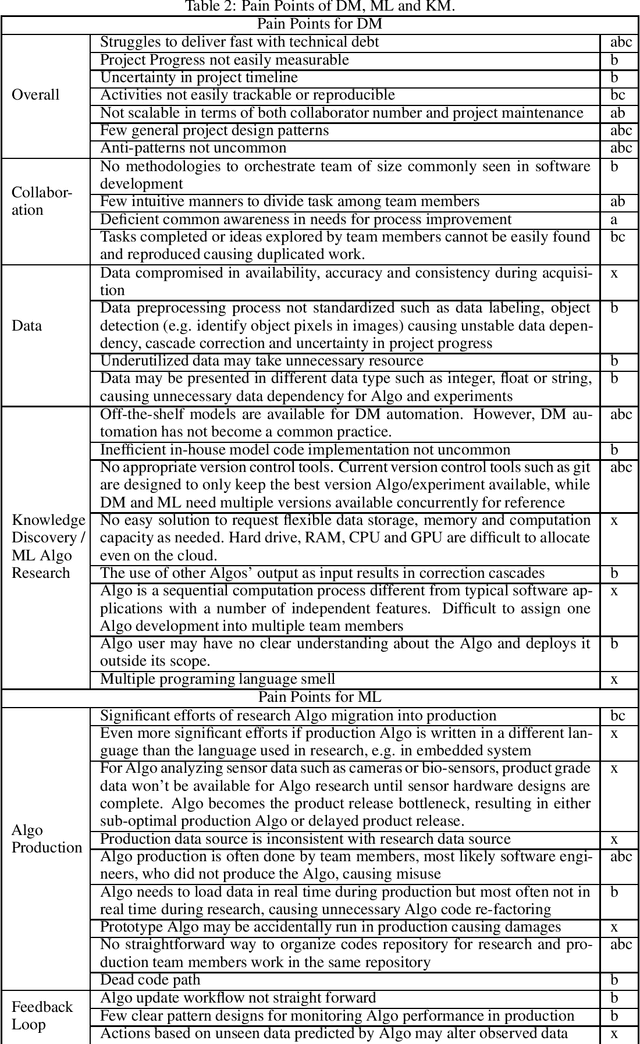
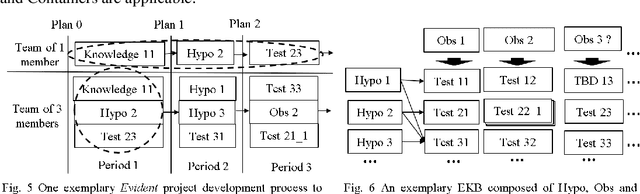
Software has been developed for knowledge discovery, prediction and management for over 30 years. However, there are still unresolved pain points when using existing project development and artifact management methodologies. Historically, there has been a lack of applicable methodologies. Further, methodologies that have been applied, such as Agile, have several limitations including scientific unfalsifiability that reduce their applicability. Evident, a development methodology rooted in the philosophy of logical reasoning and EKB, a knowledge base topology, are proposed. Many pain points in data mining, machine learning and general knowledge management are alleviated conceptually. Evident can be extended potentially to accelerate philosophical exploration, science discovery, education as well as knowledge sharing & retention across the globe. EKB offers one solution of storing information as knowledge, a granular level above data. Related topics in computer history, software engineering, database, sensor, philosophy, and project & organization & military managements are also discussed.