 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidet: Task Mapping Programming Paradigm for Deep Learning Tensor Programs
Paper and Code
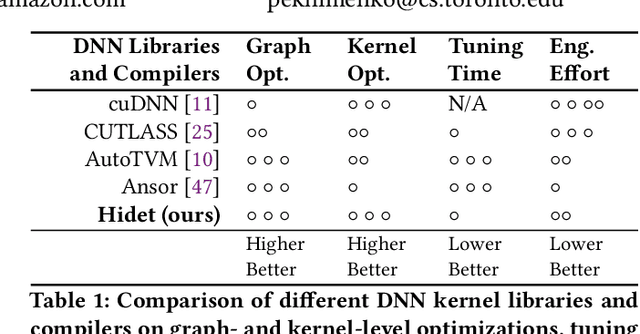
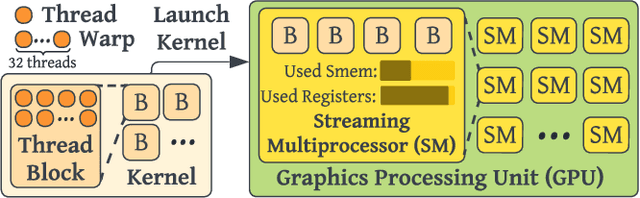
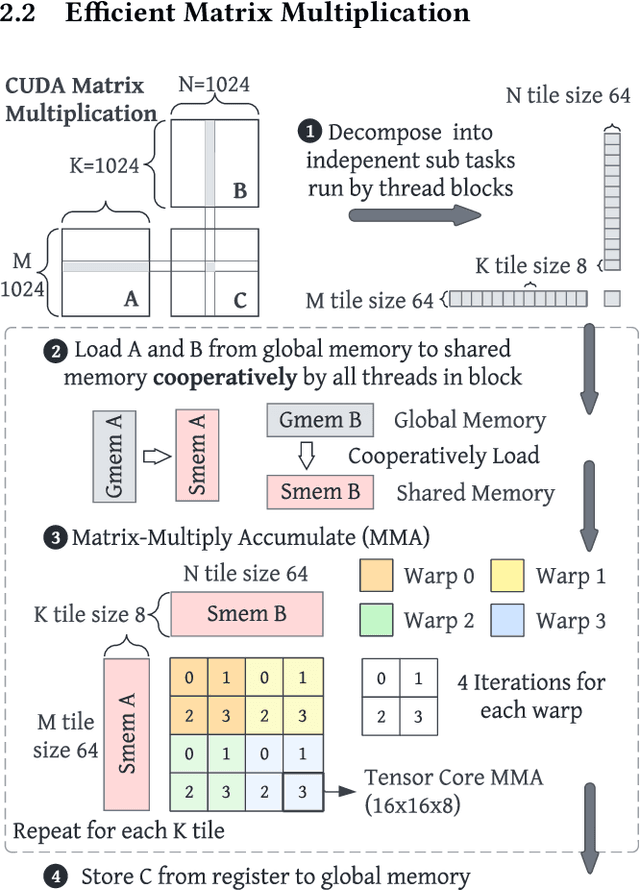
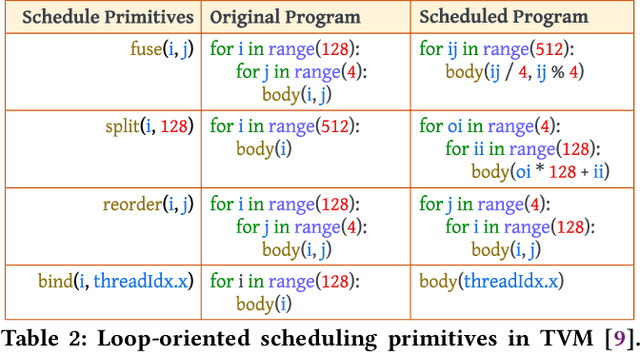
As deep learning models nowadays are widely adopted by both cloud services and edge devices, the latency of deep learning model inferences becomes crucial to provide efficient model serving. However, it is challenging to develop efficient tensor programs for deep learning operators due to the high complexity of modern accelerators (e.g., NVIDIA GPUs and Google TPUs) and the rapidly growing number of operators. Deep learning compilers, such as Apache TVM, adopt declarative scheduling primitives to lower the bar of developing tensor programs. However, we show that this approach is insufficient to cover state-of-the-art tensor program optimizations (e.g., double buffering). In this paper, we propose to embed the scheduling process into tensor programs and use dedicated mappings, called task mappings, to define the computation assignment and ordering directly in the tensor programs. This new approach greatly enriches the expressible optimizations by allowing developers to manipulate tensor programs at a much finer granularity (e.g., allowing program statement-level optimizations). We call the proposed method the task-mapping-oriented programming paradigm. With the proposed paradigm, we implement a deep learning compiler - Hidet. Extensive experiments on modern convolution and transformer models show that Hidet outperforms state-of-the-art DNN inference framework, ONNX Runtime, and compiler, TVM equipped with scheduler AutoTVM and Ansor, by up to 1.48x (1.22x on average) with enriched optimizations. It also reduces the tuning time by 20x and 11x compared with AutoTVM and Ansor, respectively.