 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBHCast: Unlocking Black Hole Plasma Dynamics from a Single Blurry Image with Long-Term Forecasting
Mar 24, 2026The Event Horizon Telescope (EHT) delivered the first image of a black hole by capturing the light from its surrounding accretion flow, revealing structure but not dynamics. Simulations of black hole accretion dynamics are essential for interpreting EHT images but costly to generate and impractical for inference. Motivated by this bottleneck, BHCast presents a framework for forecasting black hole plasma dynamics from a single, blurry snapshot, such as those captured by the EHT. At its core, BHCast is a neural model that transforms a static image into forecasted future frames, revealing the underlying dynamics hidden within one snapshot. With a multi-scale pyramid loss, we demonstrate how autoregressive forecasting can simultaneously super-resolve and evolve a blurry frame into a coherent, high-resolution movie that remains stable over long time horizons. From forecasted dynamics, we can then extract interpretable spatio-temporal features, such as pattern speed (rotation rate) and pitch angle. Finally, BHCast uses gradient-boosting trees to recover black hole properties from these plasma features, including the spin and viewing inclination angle. The separation between forecasting and inference provides modular flexibility, interpretability, and robust uncertainty quantification. We demonstrate the effectiveness of BHCast on simulations of two distinct black hole accretion systems, Sagittarius A* and M87*, by testing on simulated frames blurred to EHT resolution and real EHT images of M87*. Ultimately, our methodology establishes a scalable paradigm for solving inverse problems, demonstrating the potential of learned dynamics to unlock insights from resolution-limited scientific data.
StreamFusion: Scalable Sequence Parallelism for Distributed Inference of Diffusion Transformers on GPUs
Jan 28, 2026Diffusion Transformers (DiTs) have gained increasing adoption in high-quality image and video generation. As demand for higher-resolution images and longer videos increases, single-GPU inference becomes inefficient due to increased latency and large activation sizes. Current frameworks employ sequence parallelism (SP) techniques such as Ulysses Attention and Ring Attention to scale inference. However, these implementations have three primary limitations: (1) suboptimal communication patterns for network topologies on modern GPU machines, (2) latency bottlenecks from all-to-all operations in inter-machine communication, and (3) GPU sender-receiver synchronization and computation overheads from using two-sided communication libraries. To address these issues, we present StreamFusion, a topology-aware efficient DiT serving engine. StreamFusion incorporates three key innovations: (1) a topology-aware sequence parallelism technique that accounts for inter- and intra-machine bandwidth differences, (2) Torus Attention, a novel SP technique enabling overlapping of inter-machine all-to-all operations with computation, and (3) a one-sided communication implementation that minimizes GPU sender-receiver synchronization and computation overheads. Our experiments demonstrate that StreamFusion outperforms the state-of-the-art approach by an average of $1.35\times$ (up to $1.77\times$).
A Tensor Compiler for Processing-In-Memory Architectures
Nov 19, 2025Processing-In-Memory (PIM) devices integrated with high-performance Host processors (e.g., GPUs) can accelerate memory-intensive kernels in Machine Learning (ML) models, including Large Language Models (LLMs), by leveraging high memory bandwidth at PIM cores. However, Host processors and PIM cores require different data layouts: Hosts need consecutive elements distributed across DRAM banks, while PIM cores need them within local banks. This necessitates data rearrangements in ML kernel execution that pose significant performance and programmability challenges, further exacerbated by the need to support diverse PIM backends. Current compilation approaches lack systematic optimization for diverse ML kernels across multiple PIM backends and may largely ignore data rearrangements during compute code optimization. We demonstrate that data rearrangements and compute code optimization are interdependent, and need to be jointly optimized during the tuning process. To address this, we design DCC, the first data-centric ML compiler for PIM systems that jointly co-optimizes data rearrangements and compute code in a unified tuning process. DCC integrates a multi-layer PIM abstraction that enables various data distribution and processing strategies on different PIM backends. DCC enables effective co-optimization by mapping data partitioning strategies to compute loop partitions, applying PIM-specific code optimizations and leveraging a fast and accurate performance prediction model to select optimal configurations. Our evaluations in various individual ML kernels demonstrate that DCC achieves up to 7.68x speedup (2.7x average) on HBM-PIM and up to 13.17x speedup (5.75x average) on AttAcc PIM backend over GPU-only execution. In end-to-end LLM inference, DCC on AttAcc accelerates GPT-3 and LLaMA-2 by up to 7.71x (4.88x average) over GPU.
DPQuant: Efficient and Differentially-Private Model Training via Dynamic Quantization Scheduling
Sep 03, 2025Differentially-Private SGD (DP-SGD) is a powerful technique to protect user privacy when using sensitive data to train neural networks. During training, converting model weights and activations into low-precision formats, i.e., quantization, can drastically reduce training times, energy consumption, and cost, and is thus a widely used technique. In this work, we demonstrate that quantization causes significantly higher accuracy degradation in DP-SGD compared to regular SGD. We observe that this is caused by noise injection in DP-SGD, which amplifies quantization variance, leading to disproportionately large accuracy degradation. To address this challenge, we present QPQuant, a dynamic quantization framework that adaptively selects a changing subset of layers to quantize at each epoch. Our method combines two key ideas that effectively reduce quantization variance: (i) probabilistic sampling of the layers that rotates which layers are quantized every epoch, and (ii) loss-aware layer prioritization, which uses a differentially private loss sensitivity estimator to identify layers that can be quantized with minimal impact on model quality. This estimator consumes a negligible fraction of the overall privacy budget, preserving DP guarantees. Empirical evaluations on ResNet18, ResNet50, and DenseNet121 across a range of datasets demonstrate that DPQuant consistently outperforms static quantization baselines, achieving near Pareto-optimal accuracy-compute trade-offs and up to 2.21x theoretical throughput improvements on low-precision hardware, with less than 2% drop in validation accuracy.
Tilus: A Virtual Machine for Arbitrary Low-Precision GPGPU Computation in LLM Serving
Apr 25, 2025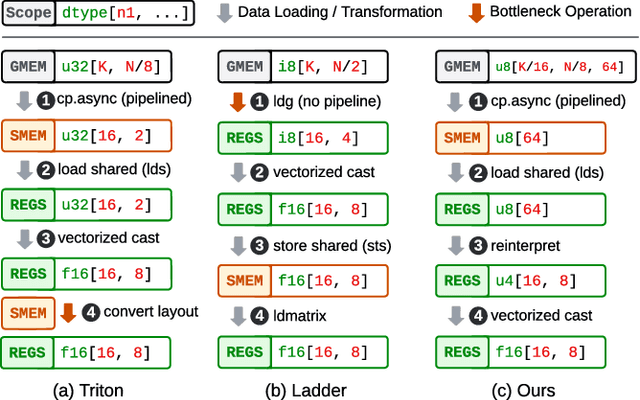
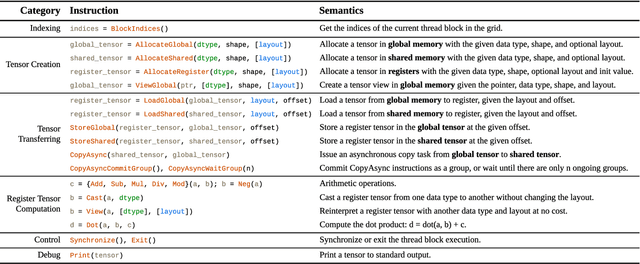
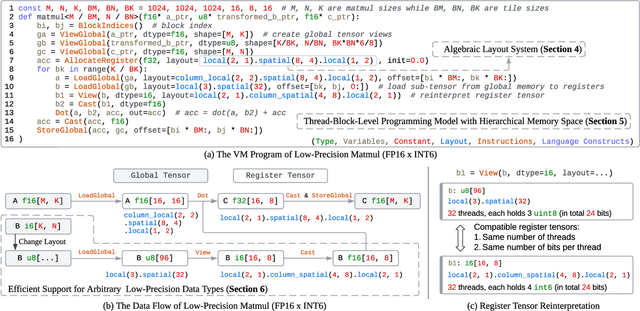
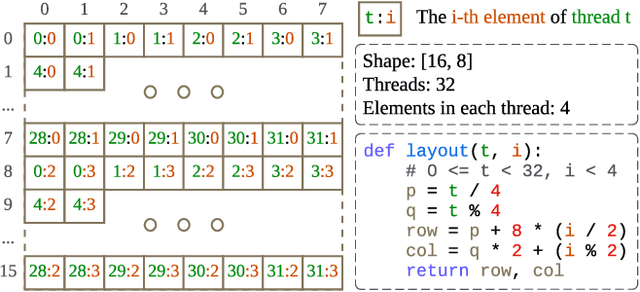
Serving Large Language Models (LLMs) is critical for AI-powered applications but demands substantial computational resources, particularly in memory bandwidth and computational throughput. Low-precision computation has emerged as a key technique to improve efficiency while reducing resource consumption. Existing approaches for generating low-precision kernels are limited to weight bit widths that are powers of two and suffer from suboptimal performance due to high-level GPU programming abstractions. These abstractions restrict critical optimizations, such as fine-grained register management and optimized memory access patterns, which are essential for efficient low-precision computations. In this paper, we introduce a virtual machine (VM) designed for General-Purpose GPU (GPGPU) computing, enabling support for low-precision data types with arbitrary bit widths while maintaining GPU programmability. The proposed VM features a thread-block-level programming model, a hierarchical memory space, a novel algebraic layout system, and extensive support for diverse low-precision data types. VM programs are compiled into highly efficient GPU programs with automatic vectorization and instruction selection. Extensive experiments demonstrate that our VM efficiently supports a full spectrum of low-precision data types, and outperforms state-of-the-art low-precision kernels on their supported types. Compared to existing compilers like Triton and Ladder, as well as hand-optimized kernels such as QuantLLM and Marlin, our VM achieves performance improvements of 1.75x, 2.61x, 1.29x and 1.03x, respectively.
Hexcute: A Tile-based Programming Language with Automatic Layout and Task-Mapping Synthesis
Apr 22, 2025Deep learning (DL) workloads mainly run on accelerators like GPUs. Recent DL quantization techniques demand a new matrix multiplication operator with mixed input data types, further complicating GPU optimization. Prior high-level compilers like Triton lack the expressiveness to implement key optimizations like fine-grained data pipelines and hardware-friendly memory layouts for these operators, while low-level programming models, such as Hidet, Graphene, and CUTLASS, require significant programming efforts. To balance expressiveness with engineering effort, we propose Hexcute, a tile-based programming language that exposes shared memory and register abstractions to enable fine-grained optimization for these operators. Additionally, Hexcute leverages task mapping to schedule the GPU program, and to reduce programming efforts, it automates layout and task mapping synthesis with a novel type-inference-based algorithm. Our evaluation shows that Hexcute generalizes to a wide range of DL operators, achieves 1.7-11.28$\times$ speedup over existing DL compilers for mixed-type operators, and brings up to 2.91$\times$ speedup in the end-to-end evaluation.
A Virtual Machine for Arbitrary Low-Precision GPGPU Computation in LLM Serving
Apr 17, 2025Serving Large Language Models (LLMs) is critical for AI-powered applications but demands substantial computational resources, particularly in memory bandwidth and computational throughput. Low-precision computation has emerged as a key technique to improve efficiency while reducing resource consumption. Existing approaches for generating low-precision kernels are limited to weight bit widths that are powers of two and suffer from suboptimal performance due to high-level GPU programming abstractions. These abstractions restrict critical optimizations, such as fine-grained register management and optimized memory access patterns, which are essential for efficient low-precision computations. In this paper, we introduce a virtual machine (VM) designed for General-Purpose GPU (GPGPU) computing, enabling support for low-precision data types with arbitrary bit widths while maintaining GPU programmability. The proposed VM features a thread-block-level programming model, a hierarchical memory space, a novel algebraic layout system, and extensive support for diverse low-precision data types. VM programs are compiled into highly efficient GPU programs with automatic vectorization and instruction selection. Extensive experiments demonstrate that our VM efficiently supports a full spectrum of low-precision data types, and outperforms state-of-the-art low-precision kernels on their supported types. Compared to existing compilers like Triton and Ladder, as well as hand-optimized kernels such as QuantLLM and Marlin, our VM achieves performance improvements of 1.75x, 2.61x, 1.29x and 1.03x, respectively.
Mist: Efficient Distributed Training of Large Language Models via Memory-Parallelism Co-Optimization
Mar 24, 2025Various parallelism, such as data, tensor, and pipeline parallelism, along with memory optimizations like activation checkpointing, redundancy elimination, and offloading, have been proposed to accelerate distributed training for Large Language Models. To find the best combination of these techniques, automatic distributed training systems are proposed. However, existing systems only tune a subset of optimizations, due to the lack of overlap awareness, inability to navigate the vast search space, and ignoring the inter-microbatch imbalance, leading to sub-optimal performance. To address these shortcomings, we propose Mist, a memory, overlap, and imbalance-aware automatic distributed training system that comprehensively co-optimizes all memory footprint reduction techniques alongside parallelism. Mist is based on three key ideas: (1) fine-grained overlap-centric scheduling, orchestrating optimizations in an overlapped manner, (2) symbolic-based performance analysis that predicts runtime and memory usage using symbolic expressions for fast tuning, and (3) imbalance-aware hierarchical tuning, decoupling the process into an inter-stage imbalance and overlap aware Mixed Integer Linear Programming problem and an intra-stage Dual-Objective Constrained Optimization problem, and connecting them through Pareto frontier sampling. Our evaluation results show that Mist achieves an average of 1.28$\times$ (up to 1.73$\times$) and 1.27$\times$ (up to 2.04$\times$) speedup compared to state-of-the-art manual system Megatron-LM and state-of-the-art automatic system Aceso, respectively.
Seesaw: High-throughput LLM Inference via Model Re-sharding
Mar 09, 2025To improve the efficiency of distributed large language model (LLM) inference, various parallelization strategies, such as tensor and pipeline parallelism, have been proposed. However, the distinct computational characteristics inherent in the two stages of LLM inference-prefilling and decoding-render a single static parallelization strategy insufficient for the effective optimization of both stages. In this work, we present Seesaw, an LLM inference engine optimized for throughput-oriented tasks. The key idea behind Seesaw is dynamic model re-sharding, a technique that facilitates the dynamic reconfiguration of parallelization strategies across stages, thereby maximizing throughput at both phases. To mitigate re-sharding overhead and optimize computational efficiency, we employ tiered KV cache buffering and transition-minimizing scheduling. These approaches work synergistically to reduce the overhead caused by frequent stage transitions while ensuring maximum batching efficiency. Our evaluation demonstrates that Seesaw achieves a throughput increase of up to 1.78x (1.36x on average) compared to vLLM, the most widely used state-of-the-art LLM inference engine.
APPL: A Prompt Programming Language for Harmonious Integration of Programs and Large Language Model Prompts
Jun 19, 2024Large Language Models (LLMs) have become increasingly capable of handling diverse tasks with the aid of well-crafted prompts and integration of external tools, but as task complexity rises, the workflow involving LLMs can be complicated and thus challenging to implement and maintain. To address this challenge, we propose APPL, A Prompt Programming Language that acts as a bridge between computer programs and LLMs, allowing seamless embedding of prompts into Python functions, and vice versa. APPL provides an intuitive and Python-native syntax, an efficient parallelized runtime with asynchronous semantics, and a tracing module supporting effective failure diagnosis and replaying without extra costs. We demonstrate that APPL programs are intuitive, concise, and efficient through three representative scenarios: Chain-of-Thought with self-consistency (CoT-SC), ReAct tool use agent, and multi-agent chat. Experiments on three parallelizable workflows further show that APPL can effectively parallelize independent LLM calls, with a significant speedup ratio that almost matches the estimation.