 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tensor Compiler for Processing-In-Memory Architectures
Nov 19, 2025Processing-In-Memory (PIM) devices integrated with high-performance Host processors (e.g., GPUs) can accelerate memory-intensive kernels in Machine Learning (ML) models, including Large Language Models (LLMs), by leveraging high memory bandwidth at PIM cores. However, Host processors and PIM cores require different data layouts: Hosts need consecutive elements distributed across DRAM banks, while PIM cores need them within local banks. This necessitates data rearrangements in ML kernel execution that pose significant performance and programmability challenges, further exacerbated by the need to support diverse PIM backends. Current compilation approaches lack systematic optimization for diverse ML kernels across multiple PIM backends and may largely ignore data rearrangements during compute code optimization. We demonstrate that data rearrangements and compute code optimization are interdependent, and need to be jointly optimized during the tuning process. To address this, we design DCC, the first data-centric ML compiler for PIM systems that jointly co-optimizes data rearrangements and compute code in a unified tuning process. DCC integrates a multi-layer PIM abstraction that enables various data distribution and processing strategies on different PIM backends. DCC enables effective co-optimization by mapping data partitioning strategies to compute loop partitions, applying PIM-specific code optimizations and leveraging a fast and accurate performance prediction model to select optimal configurations. Our evaluations in various individual ML kernels demonstrate that DCC achieves up to 7.68x speedup (2.7x average) on HBM-PIM and up to 13.17x speedup (5.75x average) on AttAcc PIM backend over GPU-only execution. In end-to-end LLM inference, DCC on AttAcc accelerates GPT-3 and LLaMA-2 by up to 7.71x (4.88x average) over GPU.
Accelerating Graph Neural Networks on Real Processing-In-Memory Systems
Feb 26, 2024



Graph Neural Networks (GNNs) are emerging ML models to analyze graph-structure data. Graph Neural Network (GNN) execution involves both compute-intensive and memory-intensive kernels, the latter dominates the total time, being significantly bottlenecked by data movement between memory and processors. Processing-In-Memory (PIM) systems can alleviate this data movement bottleneck by placing simple processors near or inside to memory arrays. In this work, we introduce PyGim, an efficient ML framework that accelerates GNNs on real PIM systems. We propose intelligent parallelization techniques for memory-intensive kernels of GNNs tailored for real PIM systems, and develop handy Python API for them. We provide hybrid GNN execution, in which the compute-intensive and memory-intensive kernels are executed in processor-centric and memory-centric computing systems, respectively, to match their algorithmic nature. We extensively evaluate PyGim on a real-world PIM system with 1992 PIM cores using emerging GNN models, and demonstrate that it outperforms its state-of-the-art CPU counterpart on Intel Xeon by on average 3.04x, and achieves higher resource utilization than CPU and GPU systems. Our work provides useful recommendations for software, system and hardware designers. PyGim will be open-sourced to enable the widespread use of PIM systems in GNNs.
Horizontally Fused Training Array: An Effective Hardware Utilization Squeezer for Training Novel Deep Learning Models
Feb 07, 2021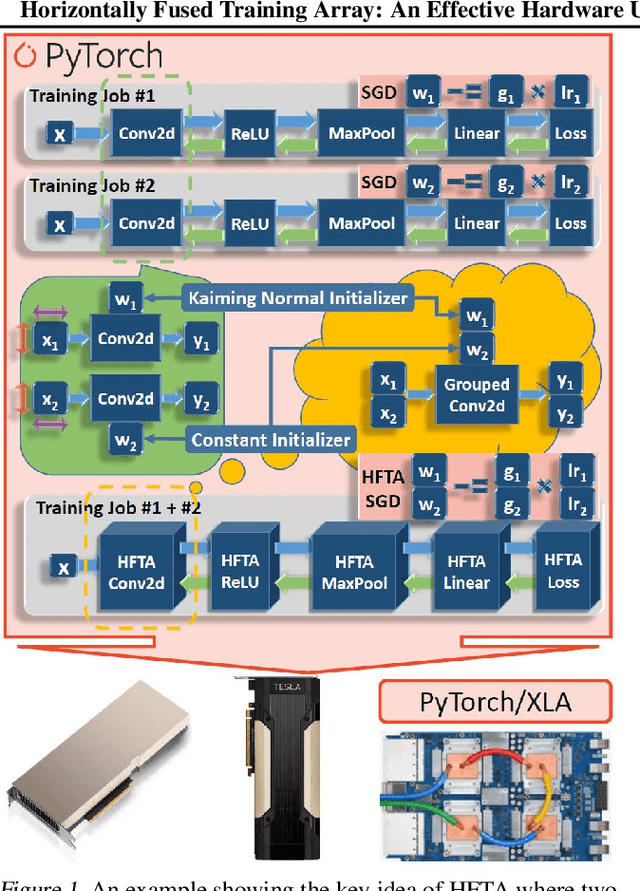
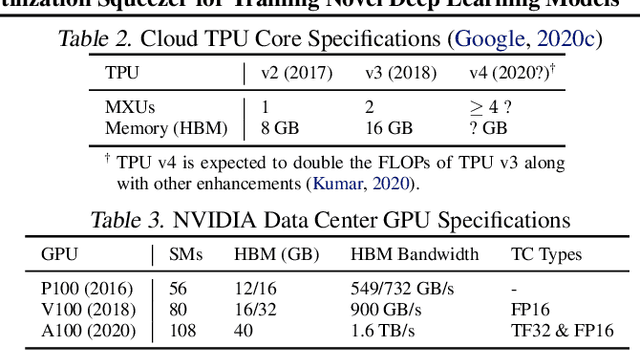

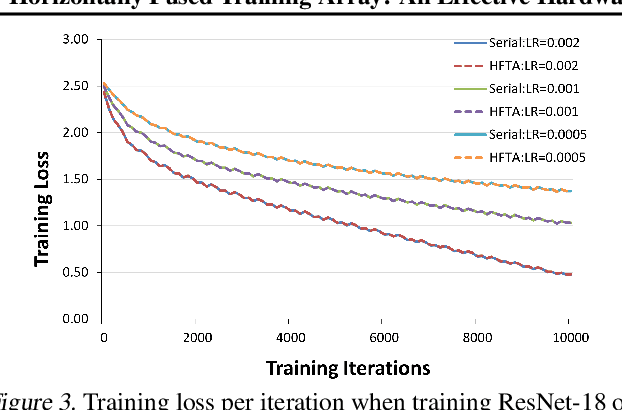
Driven by the tremendous effort in researching novel deep learning (DL) algorithms, the training cost of developing new models increases staggeringly in recent years. To reduce this training cost and optimize the cluster-wide hardware resource usage, we analyze GPU cluster usage statistics from a well-known research institute. Our study reveals that single-accelerator training jobs can dominate the cluster-wide resource consumption when launched repetitively (e.g., for hyper-parameter tuning) while severely underutilizing the hardware. This is because DL researchers and practitioners often lack the required expertise to independently optimize their own workloads. Fortunately, we observe that such workloads have the following unique characteristics: (i) the models among jobs often have the same types of operators with the same shapes, and (ii) the inter-model horizontal fusion of such operators is mathematically equivalent to other already well-optimized operators. Thus, to help DL researchers and practitioners effectively and easily improve the hardware utilization of their novel DL training workloads, we propose Horizontally Fused Training Array (HFTA). HFTA is a new DL framework extension library that horizontally fuses the models from different repetitive jobs deeply down to operators, and then trains those models simultaneously on a shared accelerator. On three emerging DL training workloads and state-of-the-art accelerators (GPUs and TPUs), HFTA demonstrates strong effectiveness in squeezing out hardware utilization and achieves up to $15.1 \times$ higher training throughput vs. the standard practice of running each job on a separate accelerator.