 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAthena: Synergizing Data Prefetching and Off-Chip Prediction via Online Reinforcement Learning
Jan 24, 2026Prefetching and off-chip prediction are two techniques proposed to hide long memory access latencies in high-performance processors. In this work, we demonstrate that: (1) prefetching and off-chip prediction often provide complementary performance benefits, yet (2) naively combining them often fails to realize their full performance potential, and (3) existing prefetcher control policies leave significant room for performance improvement behind. Our goal is to design a holistic framework that can autonomously learn to coordinate an off-chip predictor with multiple prefetchers employed at various cache levels. To this end, we propose a new technique called Athena, which models the coordination between prefetchers and off-chip predictor (OCP) as a reinforcement learning (RL) problem. Athena acts as the RL agent that observes multiple system-level features (e.g., prefetcher/OCP accuracy, bandwidth usage) over an epoch of program execution, and uses them as state information to select a coordination action (i.e., enabling the prefetcher and/or OCP, and adjusting prefetcher aggressiveness). At the end of every epoch, Athena receives a numerical reward that measures the change in multiple system-level metrics (e.g., number of cycles taken to execute an epoch). Athena uses this reward to autonomously and continuously learn a policy to coordinate prefetchers with OCP. Our extensive evaluation using a diverse set of memory-intensive workloads shows that Athena consistently outperforms prior state-of-the-art coordination policies across a wide range of system configurations with various combinations of underlying prefetchers, OCPs, and main memory bandwidths, while incurring only modest storage overhead. Athena is freely available at https://github.com/CMU-SAFARI/Athena.
A Tensor Compiler for Processing-In-Memory Architectures
Nov 19, 2025Processing-In-Memory (PIM) devices integrated with high-performance Host processors (e.g., GPUs) can accelerate memory-intensive kernels in Machine Learning (ML) models, including Large Language Models (LLMs), by leveraging high memory bandwidth at PIM cores. However, Host processors and PIM cores require different data layouts: Hosts need consecutive elements distributed across DRAM banks, while PIM cores need them within local banks. This necessitates data rearrangements in ML kernel execution that pose significant performance and programmability challenges, further exacerbated by the need to support diverse PIM backends. Current compilation approaches lack systematic optimization for diverse ML kernels across multiple PIM backends and may largely ignore data rearrangements during compute code optimization. We demonstrate that data rearrangements and compute code optimization are interdependent, and need to be jointly optimized during the tuning process. To address this, we design DCC, the first data-centric ML compiler for PIM systems that jointly co-optimizes data rearrangements and compute code in a unified tuning process. DCC integrates a multi-layer PIM abstraction that enables various data distribution and processing strategies on different PIM backends. DCC enables effective co-optimization by mapping data partitioning strategies to compute loop partitions, applying PIM-specific code optimizations and leveraging a fast and accurate performance prediction model to select optimal configurations. Our evaluations in various individual ML kernels demonstrate that DCC achieves up to 7.68x speedup (2.7x average) on HBM-PIM and up to 13.17x speedup (5.75x average) on AttAcc PIM backend over GPU-only execution. In end-to-end LLM inference, DCC on AttAcc accelerates GPT-3 and LLaMA-2 by up to 7.71x (4.88x average) over GPU.
Harmonia: A Multi-Agent Reinforcement Learning Approach to Data Placement and Migration in Hybrid Storage Systems
Mar 26, 2025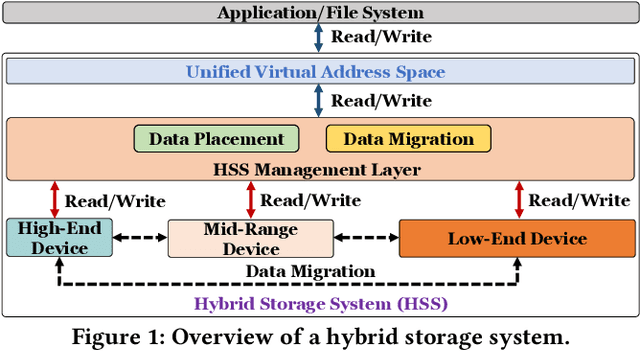
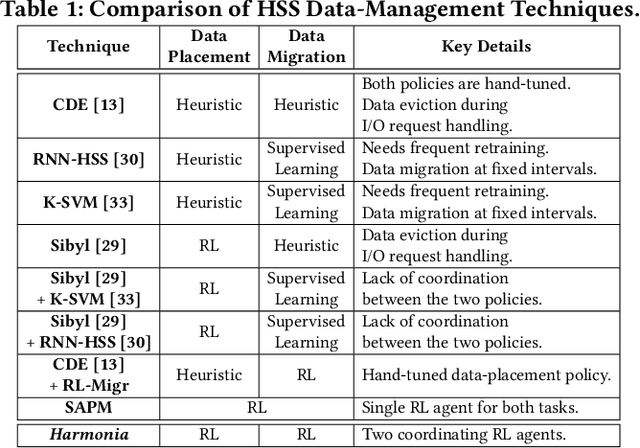

Hybrid storage systems (HSS) combine multiple storage devices with diverse characteristics to achieve high performance and capacity at low cost. The performance of an HSS highly depends on the effectiveness of two key policies: (1) the data-placement policy, which determines the best-fit storage device for incoming data, and (2) the data-migration policy, which rearranges stored data across the devices to sustain high HSS performance. Prior works focus on improving only data placement or only data migration in HSS, which leads to sub-optimal HSS performance. Unfortunately, no prior work tries to optimize both policies together. Our goal is to design a holistic data-management technique for HSS that optimizes both data-placement and data-migration policies to fully exploit the potential of an HSS. We propose Harmonia, a multi-agent reinforcement learning (RL)-based data-management technique that employs two light-weight autonomous RL agents, a data-placement agent and a data-migration agent, which adapt their policies for the current workload and HSS configuration, and coordinate with each other to improve overall HSS performance. We evaluate Harmonia on a real HSS with up to four heterogeneous storage devices with diverse characteristics. Our evaluation using 17 data-intensive workloads on performance-optimized (cost-optimized) HSS with two storage devices shows that, on average, Harmonia (1) outperforms the best-performing prior approach by 49.5% (31.7%), (2) bridges the performance gap between the best-performing prior work and Oracle by 64.2% (64.3%). On an HSS with three (four) devices, Harmonia outperforms the best-performing prior work by 37.0% (42.0%). Harmonia's performance benefits come with low latency (240ns for inference) and storage overheads (206 KiB for both RL agents together). We plan to open-source Harmonia's implementation to aid future research on HSS.
PAPI: Exploiting Dynamic Parallelism in Large Language Model Decoding with a Processing-In-Memory-Enabled Computing System
Feb 21, 2025Large language models (LLMs) are widely used for natural language understanding and text generation. An LLM model relies on a time-consuming step called LLM decoding to generate output tokens. Several prior works focus on improving the performance of LLM decoding using parallelism techniques, such as batching and speculative decoding. State-of-the-art LLM decoding has both compute-bound and memory-bound kernels. Some prior works statically identify and map these different kernels to a heterogeneous architecture consisting of both processing-in-memory (PIM) units and computation-centric accelerators. We observe that characteristics of LLM decoding kernels (e.g., whether or not a kernel is memory-bound) can change dynamically due to parameter changes to meet user and/or system demands, making (1) static kernel mapping to PIM units and computation-centric accelerators suboptimal, and (2) one-size-fits-all approach of designing PIM units inefficient due to a large degree of heterogeneity even in memory-bound kernels. In this paper, we aim to accelerate LLM decoding while considering the dynamically changing characteristics of the kernels involved. We propose PAPI (PArallel Decoding with PIM), a PIM-enabled heterogeneous architecture that exploits dynamic scheduling of compute-bound or memory-bound kernels to suitable hardware units. PAPI has two key mechanisms: (1) online kernel characterization to dynamically schedule kernels to the most suitable hardware units at runtime and (2) a PIM-enabled heterogeneous computing system that harmoniously orchestrates both computation-centric processing units and hybrid PIM units with different computing capabilities. Our experimental results on three broadly-used LLMs show that PAPI achieves 1.8$\times$ and 11.1$\times$ speedups over a state-of-the-art heterogeneous LLM accelerator and a state-of-the-art PIM-only LLM accelerator, respectively.
SwiftRL: Towards Efficient Reinforcement Learning on Real Processing-In-Memory Systems
May 07, 2024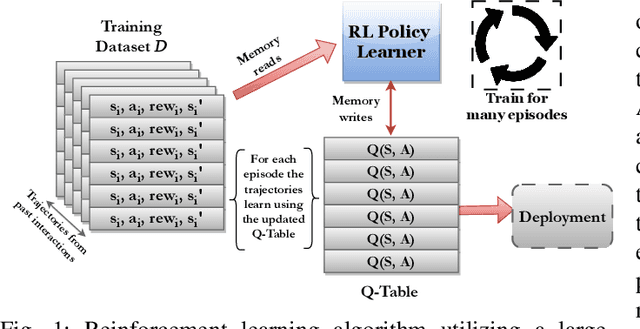
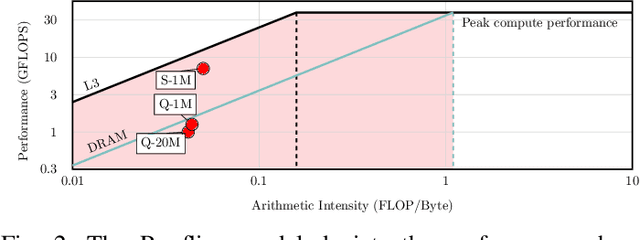
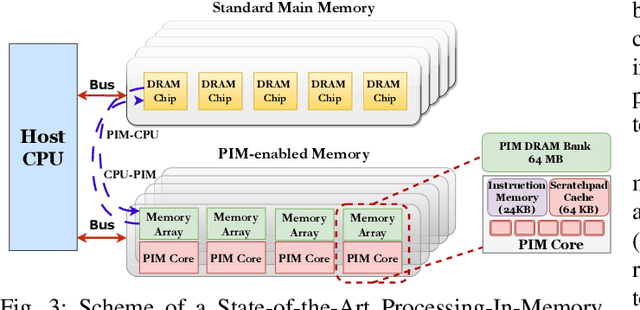
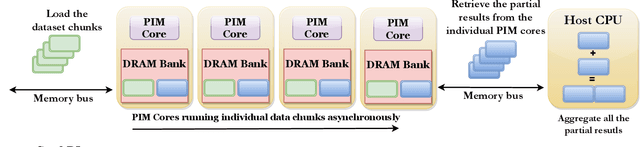
Reinforcement Learning (RL) trains agents to learn optimal behavior by maximizing reward signals from experience datasets. However, RL training often faces memory limitations, leading to execution latencies and prolonged training times. To overcome this, SwiftRL explores Processing-In-Memory (PIM) architectures to accelerate RL workloads. We achieve near-linear performance scaling by implementing RL algorithms like Tabular Q-learning and SARSA on UPMEM PIM systems and optimizing for hardware. Our experiments on OpenAI GYM environments using UPMEM hardware demonstrate superior performance compared to CPU and GPU implementations.
Analysis of Distributed Optimization Algorithms on a Real Processing-In-Memory System
Apr 10, 2024



Machine Learning (ML) training on large-scale datasets is a very expensive and time-consuming workload. Processor-centric architectures (e.g., CPU, GPU) commonly used for modern ML training workloads are limited by the data movement bottleneck, i.e., due to repeatedly accessing the training dataset. As a result, processor-centric systems suffer from performance degradation and high energy consumption. Processing-In-Memory (PIM) is a promising solution to alleviate the data movement bottleneck by placing the computation mechanisms inside or near memory. Our goal is to understand the capabilities and characteristics of popular distributed optimization algorithms on real-world PIM architectures to accelerate data-intensive ML training workloads. To this end, we 1) implement several representative centralized distributed optimization algorithms on UPMEM's real-world general-purpose PIM system, 2) rigorously evaluate these algorithms for ML training on large-scale datasets in terms of performance, accuracy, and scalability, 3) compare to conventional CPU and GPU baselines, and 4) discuss implications for future PIM hardware and the need to shift to an algorithm-hardware codesign perspective to accommodate decentralized distributed optimization algorithms. Our results demonstrate three major findings: 1) Modern general-purpose PIM architectures can be a viable alternative to state-of-the-art CPUs and GPUs for many memory-bound ML training workloads, when operations and datatypes are natively supported by PIM hardware, 2) the importance of carefully choosing the optimization algorithm that best fit PIM, and 3) contrary to popular belief, contemporary PIM architectures do not scale approximately linearly with the number of nodes for many data-intensive ML training workloads. To facilitate future research, we aim to open-source our complete codebase.
Accelerating Graph Neural Networks on Real Processing-In-Memory Systems
Feb 26, 2024



Graph Neural Networks (GNNs) are emerging ML models to analyze graph-structure data. Graph Neural Network (GNN) execution involves both compute-intensive and memory-intensive kernels, the latter dominates the total time, being significantly bottlenecked by data movement between memory and processors. Processing-In-Memory (PIM) systems can alleviate this data movement bottleneck by placing simple processors near or inside to memory arrays. In this work, we introduce PyGim, an efficient ML framework that accelerates GNNs on real PIM systems. We propose intelligent parallelization techniques for memory-intensive kernels of GNNs tailored for real PIM systems, and develop handy Python API for them. We provide hybrid GNN execution, in which the compute-intensive and memory-intensive kernels are executed in processor-centric and memory-centric computing systems, respectively, to match their algorithmic nature. We extensively evaluate PyGim on a real-world PIM system with 1992 PIM cores using emerging GNN models, and demonstrate that it outperforms its state-of-the-art CPU counterpart on Intel Xeon by on average 3.04x, and achieves higher resource utilization than CPU and GPU systems. Our work provides useful recommendations for software, system and hardware designers. PyGim will be open-sourced to enable the widespread use of PIM systems in GNNs.
TransPimLib: A Library for Efficient Transcendental Functions on Processing-in-Memory Systems
Apr 23, 2023



Processing-in-memory (PIM) promises to alleviate the data movement bottleneck in modern computing systems. However, current real-world PIM systems have the inherent disadvantage that their hardware is more constrained than in conventional processors (CPU, GPU), due to the difficulty and cost of building processing elements near or inside the memory. As a result, general-purpose PIM architectures support fairly limited instruction sets and struggle to execute complex operations such as transcendental functions and other hard-to-calculate operations (e.g., square root). These operations are particularly important for some modern workloads, e.g., activation functions in machine learning applications. In order to provide support for transcendental (and other hard-to-calculate) functions in general-purpose PIM systems, we present \emph{TransPimLib}, a library that provides CORDIC-based and LUT-based methods for trigonometric functions, hyperbolic functions, exponentiation, logarithm, square root, etc. We develop an implementation of TransPimLib for the UPMEM PIM architecture and perform a thorough evaluation of TransPimLib's methods in terms of performance and accuracy, using microbenchmarks and three full workloads (Blackscholes, Sigmoid, Softmax). We open-source all our code and datasets at~\url{https://github.com/CMU-SAFARI/transpimlib}.
TargetCall: Eliminating the Wasted Computation in Basecalling via Pre-Basecalling Filtering
Dec 09, 2022Basecalling is an essential step in nanopore sequencing analysis where the raw signals of nanopore sequencers are converted into nucleotide sequences, i.e., reads. State-of-the-art basecallers employ complex deep learning models to achieve high basecalling accuracy. This makes basecalling computationally-inefficient and memory-hungry; bottlenecking the entire genome analysis pipeline. However, for many applications, the majority of reads do no match the reference genome of interest (i.e., target reference) and thus are discarded in later steps in the genomics pipeline, wasting the basecalling computation. To overcome this issue, we propose TargetCall, the first fast and widely-applicable pre-basecalling filter to eliminate the wasted computation in basecalling. TargetCall's key idea is to discard reads that will not match the target reference (i.e., off-target reads) prior to basecalling. TargetCall consists of two main components: (1) LightCall, a lightweight neural network basecaller that produces noisy reads; and (2) Similarity Check, which labels each of these noisy reads as on-target or off-target by matching them to the target reference. TargetCall filters out all off-target reads before basecalling; and the highly-accurate but slow basecalling is performed only on the raw signals whose noisy reads are labeled as on-target. Our thorough experimental evaluations using both real and simulated data show that TargetCall 1) improves the end-to-end basecalling performance of the state-of-the-art basecaller by 3.31x while maintaining high (98.88%) sensitivity in keeping on-target reads, 2) maintains high accuracy in downstream analysis, 3) precisely filters out up to 94.71% of off-target reads, and 4) achieves better performance, sensitivity, and generality compared to prior works. We freely open-source TargetCall at https://github.com/CMU-SAFARI/TargetCall.
ORIGAMI: A Heterogeneous Split Architecture for In-Memory Acceleration of Learning
Jan 09, 2019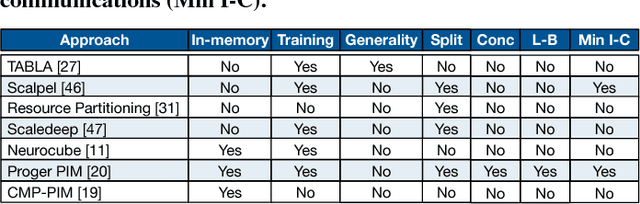
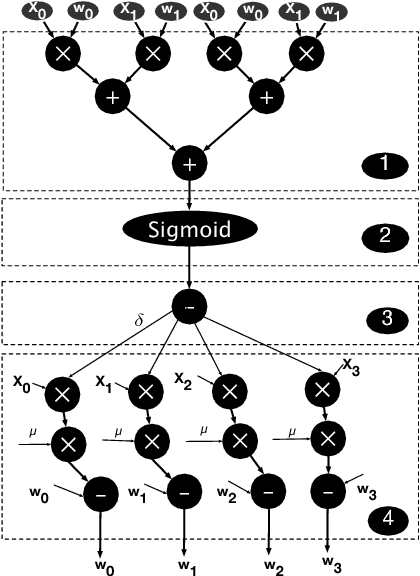
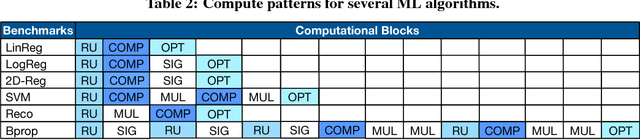
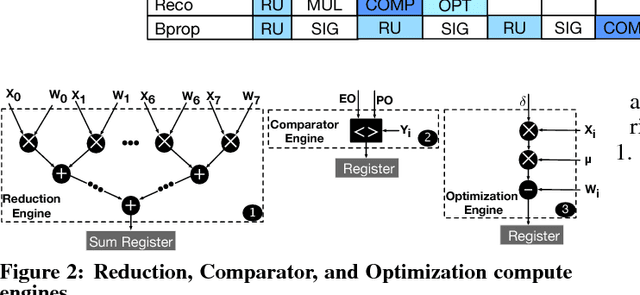
Memory bandwidth bottleneck is a major challenges in processing machine learning (ML) algorithms. In-memory acceleration has potential to address this problem; however, it needs to address two challenges. First, in-memory accelerator should be general enough to support a large set of different ML algorithms. Second, it should be efficient enough to utilize bandwidth while meeting limited power and area budgets of logic layer of a 3D-stacked memory. We observe that previous work fails to simultaneously address both challenges. We propose ORIGAMI, a heterogeneous set of in-memory accelerators, to support compute demands of different ML algorithms, and also uses an off-the-shelf compute platform (e.g.,FPGA,GPU,TPU,etc.) to utilize bandwidth without violating strict area and power budgets. ORIGAMI offers a pattern-matching technique to identify similar computation patterns of ML algorithms and extracts a compute engine for each pattern. These compute engines constitute heterogeneous accelerators integrated on logic layer of a 3D-stacked memory. Combination of these compute engines can execute any type of ML algorithms. To utilize available bandwidth without violating area and power budgets of logic layer, ORIGAMI comes with a computation-splitting compiler that divides an ML algorithm between in-memory accelerators and an out-of-the-memory platform in a balanced way and with minimum inter-communications. Combination of pattern matching and split execution offers a new design point for acceleration of ML algorithms. Evaluation results across 12 popular ML algorithms show that ORIGAMI outperforms state-of-the-art accelerator with 3D-stacked memory in terms of performance and energy-delay product (EDP) by 1.5x and 29x (up to 1.6x and 31x), respectively. Furthermore, results are within a 1% margin of an ideal system that has unlimited compute resources on logic layer of a 3D-stacked memory.