 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Experimental Study of Reduced-Voltage Operation in Modern FPGAs for Neural Network Acceleration
May 04, 2020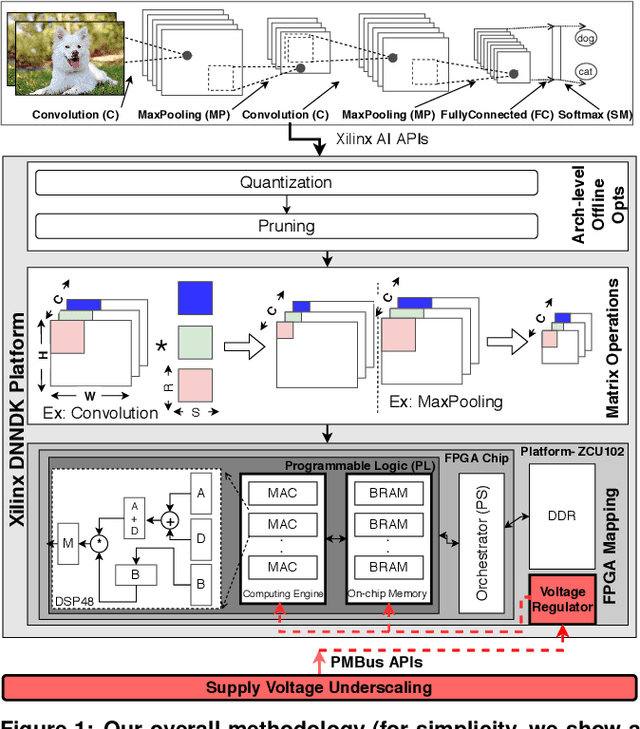
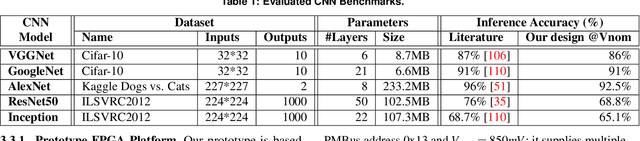
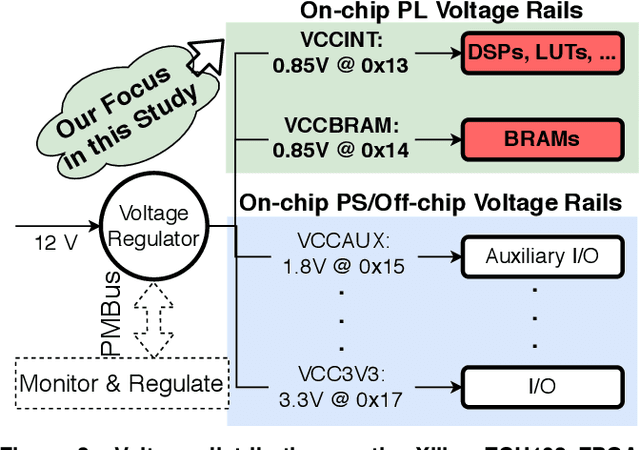
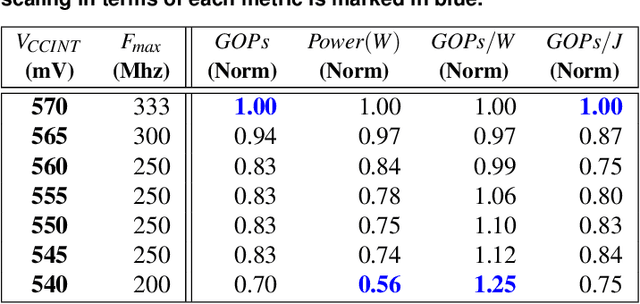
We empirically evaluate an undervolting technique, i.e., underscaling the circuit supply voltage below the nominal level, to improve the power-efficiency of Convolutional Neural Network (CNN) accelerators mapped to Field Programmable Gate Arrays (FPGAs). Undervolting below a safe voltage level can lead to timing faults due to excessive circuit latency increase. We evaluate the reliability-power trade-off for such accelerators. Specifically, we experimentally study the reduced-voltage operation of multiple components of real FPGAs, characterize the corresponding reliability behavior of CNN accelerators, propose techniques to minimize the drawbacks of reduced-voltage operation, and combine undervolting with architectural CNN optimization techniques, i.e., quantization and pruning. We investigate the effect of environmental temperature on the reliability-power trade-off of such accelerators. We perform experiments on three identical samples of modern Xilinx ZCU102 FPGA platforms with five state-of-the-art image classification CNN benchmarks. This approach allows us to study the effects of our undervolting technique for both software and hardware variability. We achieve more than 3X power-efficiency (GOPs/W) gain via undervolting. 2.6X of this gain is the result of eliminating the voltage guardband region, i.e., the safe voltage region below the nominal level that is set by FPGA vendor to ensure correct functionality in worst-case environmental and circuit conditions. 43% of the power-efficiency gain is due to further undervolting below the guardband, which comes at the cost of accuracy loss in the CNN accelerator. We evaluate an effective frequency underscaling technique that prevents this accuracy loss, and find that it reduces the power-efficiency gain from 43% to 25%.
ORIGAMI: A Heterogeneous Split Architecture for In-Memory Acceleration of Learning
Jan 09, 2019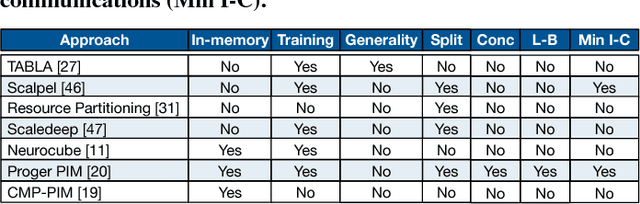
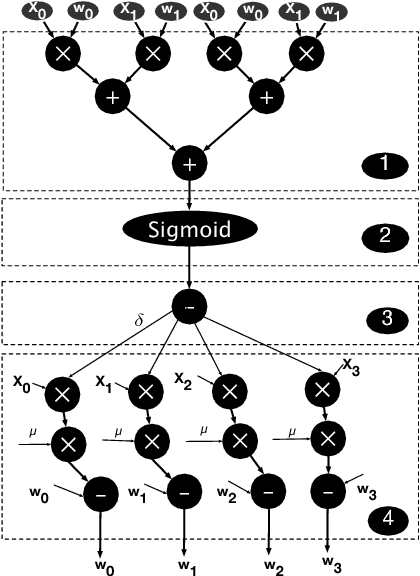
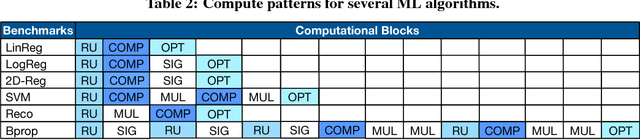
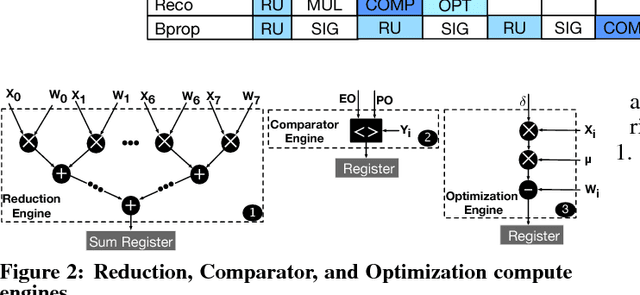
Memory bandwidth bottleneck is a major challenges in processing machine learning (ML) algorithms. In-memory acceleration has potential to address this problem; however, it needs to address two challenges. First, in-memory accelerator should be general enough to support a large set of different ML algorithms. Second, it should be efficient enough to utilize bandwidth while meeting limited power and area budgets of logic layer of a 3D-stacked memory. We observe that previous work fails to simultaneously address both challenges. We propose ORIGAMI, a heterogeneous set of in-memory accelerators, to support compute demands of different ML algorithms, and also uses an off-the-shelf compute platform (e.g.,FPGA,GPU,TPU,etc.) to utilize bandwidth without violating strict area and power budgets. ORIGAMI offers a pattern-matching technique to identify similar computation patterns of ML algorithms and extracts a compute engine for each pattern. These compute engines constitute heterogeneous accelerators integrated on logic layer of a 3D-stacked memory. Combination of these compute engines can execute any type of ML algorithms. To utilize available bandwidth without violating area and power budgets of logic layer, ORIGAMI comes with a computation-splitting compiler that divides an ML algorithm between in-memory accelerators and an out-of-the-memory platform in a balanced way and with minimum inter-communications. Combination of pattern matching and split execution offers a new design point for acceleration of ML algorithms. Evaluation results across 12 popular ML algorithms show that ORIGAMI outperforms state-of-the-art accelerator with 3D-stacked memory in terms of performance and energy-delay product (EDP) by 1.5x and 29x (up to 1.6x and 31x), respectively. Furthermore, results are within a 1% margin of an ideal system that has unlimited compute resources on logic layer of a 3D-stacked memory.
A Heuristic Routing Mechanism Using a New Addressing Scheme
Oct 10, 2007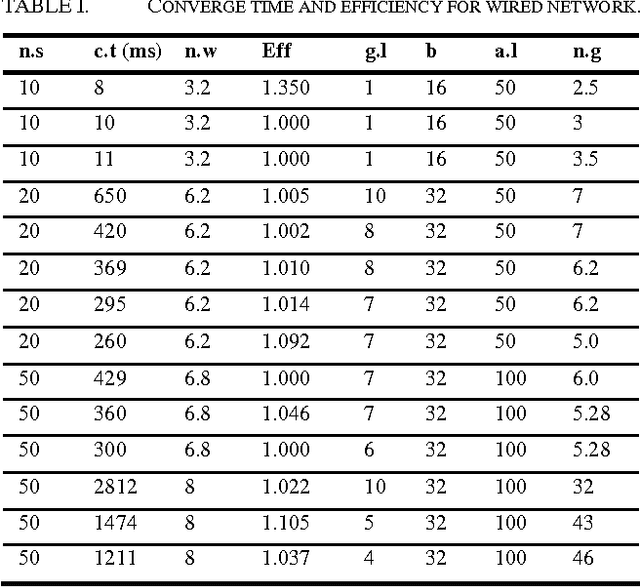

Current methods of routing are based on network information in the form of routing tables, in which routing protocols determine how to update the tables according to the network changes. Despite the variability of data in routing tables, node addresses are constant. In this paper, we first introduce the new concept of variable addresses, which results in a novel framework to cope with routing problems using heuristic solutions. Then we propose a heuristic routing mechanism based on the application of genes for determination of network addresses in a variable address network and describe how this method flexibly solves different problems and induces new ideas in providing integral solutions for variety of problems. The case of ad-hoc networks is where simulation results are more supportive and original solutions have been proposed for issues like mobility.
* 8 pages, because of lack of space journal reference just contains the reference to the proceeding