 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORIGAMI: A Heterogeneous Split Architecture for In-Memory Acceleration of Learning
Paper and Code
Jan 09, 2019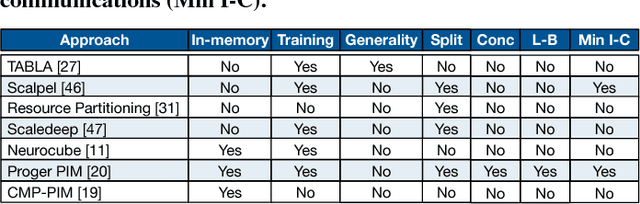
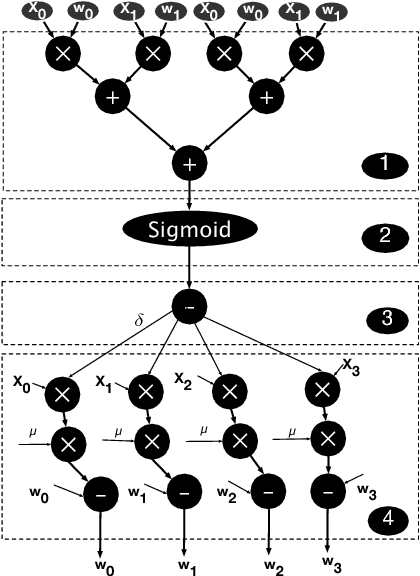
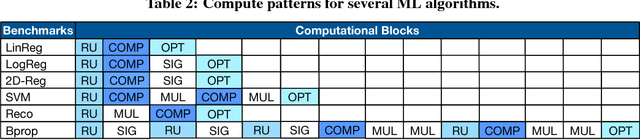
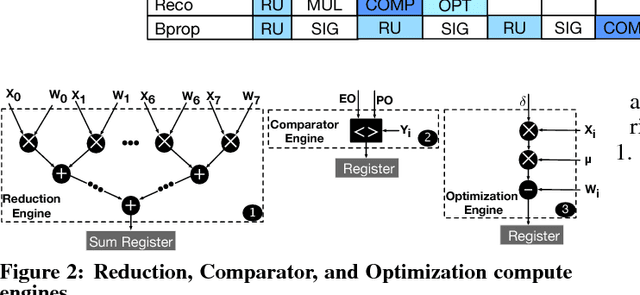
Memory bandwidth bottleneck is a major challenges in processing machine learning (ML) algorithms. In-memory acceleration has potential to address this problem; however, it needs to address two challenges. First, in-memory accelerator should be general enough to support a large set of different ML algorithms. Second, it should be efficient enough to utilize bandwidth while meeting limited power and area budgets of logic layer of a 3D-stacked memory. We observe that previous work fails to simultaneously address both challenges. We propose ORIGAMI, a heterogeneous set of in-memory accelerators, to support compute demands of different ML algorithms, and also uses an off-the-shelf compute platform (e.g.,FPGA,GPU,TPU,etc.) to utilize bandwidth without violating strict area and power budgets. ORIGAMI offers a pattern-matching technique to identify similar computation patterns of ML algorithms and extracts a compute engine for each pattern. These compute engines constitute heterogeneous accelerators integrated on logic layer of a 3D-stacked memory. Combination of these compute engines can execute any type of ML algorithms. To utilize available bandwidth without violating area and power budgets of logic layer, ORIGAMI comes with a computation-splitting compiler that divides an ML algorithm between in-memory accelerators and an out-of-the-memory platform in a balanced way and with minimum inter-communications. Combination of pattern matching and split execution offers a new design point for acceleration of ML algorithms. Evaluation results across 12 popular ML algorithms show that ORIGAMI outperforms state-of-the-art accelerator with 3D-stacked memory in terms of performance and energy-delay product (EDP) by 1.5x and 29x (up to 1.6x and 31x), respectively. Furthermore, results are within a 1% margin of an ideal system that has unlimited compute resources on logic layer of a 3D-stacked memory.