 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEON: Enabling Efficient Support for Nonlinear Operations in Resistive RAM-based Neural Network Accelerators
Nov 10, 2022Resistive Random-Access Memory (RRAM) is well-suited to accelerate neural network (NN) workloads as RRAM-based Processing-in-Memory (PIM) architectures natively support highly-parallel multiply-accumulate (MAC) operations that form the backbone of most NN workloads. Unfortunately, NN workloads such as transformers require support for non-MAC operations (e.g., softmax) that RRAM cannot provide natively. Consequently, state-of-the-art works either integrate additional digital logic circuits to support the non-MAC operations or offload the non-MAC operations to CPU/GPU, resulting in significant performance and energy efficiency overheads due to data movement. In this work, we propose NEON, a novel compiler optimization to enable the end-to-end execution of the NN workload in RRAM. The key idea of NEON is to transform each non-MAC operation into a lightweight yet highly-accurate neural network. Utilizing neural networks to approximate the non-MAC operations provides two advantages: 1) We can exploit the key strength of RRAM, i.e., highly-parallel MAC operation, to flexibly and efficiently execute non-MAC operations in memory. 2) We can simplify RRAM's microarchitecture by eliminating the additional digital logic circuits while reducing the data movement overheads. Acceleration of the non-MAC operations in memory enables NEON to achieve a 2.28x speedup compared to an idealized digital logic-based RRAM. We analyze the trade-offs associated with the transformation and demonstrate feasible use cases for NEON across different substrates.
An Experimental Study of Reduced-Voltage Operation in Modern FPGAs for Neural Network Acceleration
May 04, 2020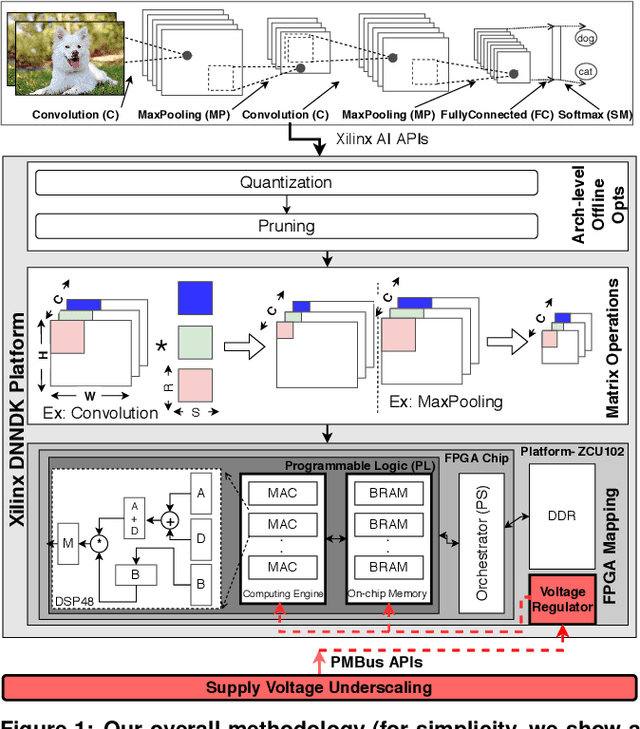
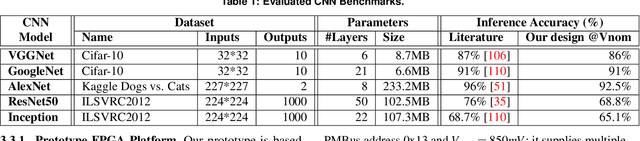
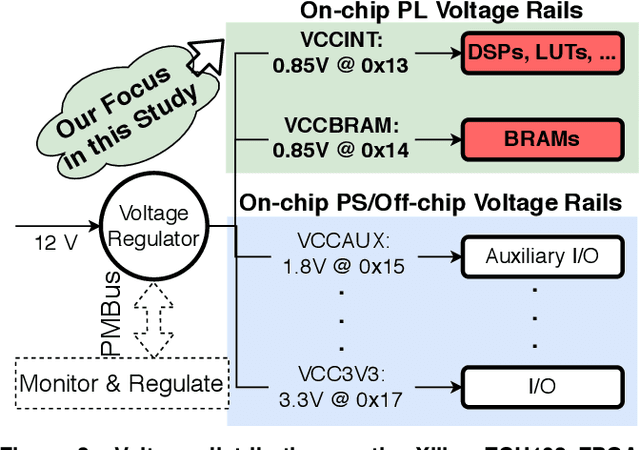
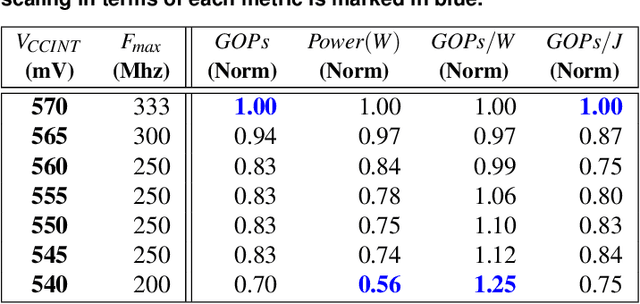
We empirically evaluate an undervolting technique, i.e., underscaling the circuit supply voltage below the nominal level, to improve the power-efficiency of Convolutional Neural Network (CNN) accelerators mapped to Field Programmable Gate Arrays (FPGAs). Undervolting below a safe voltage level can lead to timing faults due to excessive circuit latency increase. We evaluate the reliability-power trade-off for such accelerators. Specifically, we experimentally study the reduced-voltage operation of multiple components of real FPGAs, characterize the corresponding reliability behavior of CNN accelerators, propose techniques to minimize the drawbacks of reduced-voltage operation, and combine undervolting with architectural CNN optimization techniques, i.e., quantization and pruning. We investigate the effect of environmental temperature on the reliability-power trade-off of such accelerators. We perform experiments on three identical samples of modern Xilinx ZCU102 FPGA platforms with five state-of-the-art image classification CNN benchmarks. This approach allows us to study the effects of our undervolting technique for both software and hardware variability. We achieve more than 3X power-efficiency (GOPs/W) gain via undervolting. 2.6X of this gain is the result of eliminating the voltage guardband region, i.e., the safe voltage region below the nominal level that is set by FPGA vendor to ensure correct functionality in worst-case environmental and circuit conditions. 43% of the power-efficiency gain is due to further undervolting below the guardband, which comes at the cost of accuracy loss in the CNN accelerator. We evaluate an effective frequency underscaling technique that prevents this accuracy loss, and find that it reduces the power-efficiency gain from 43% to 25%.
On the Resilience of Deep Learning for Reduced-voltage FPGAs
Dec 26, 2019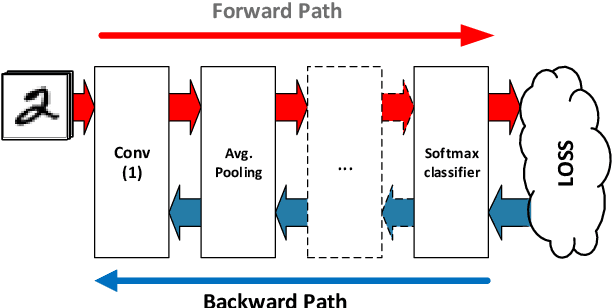
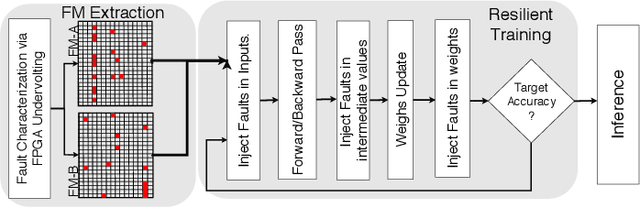
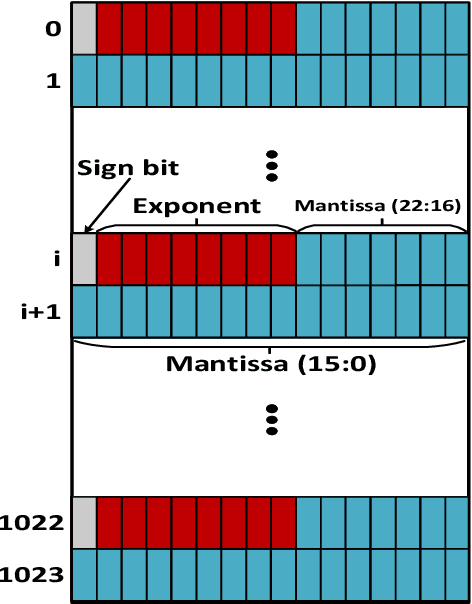
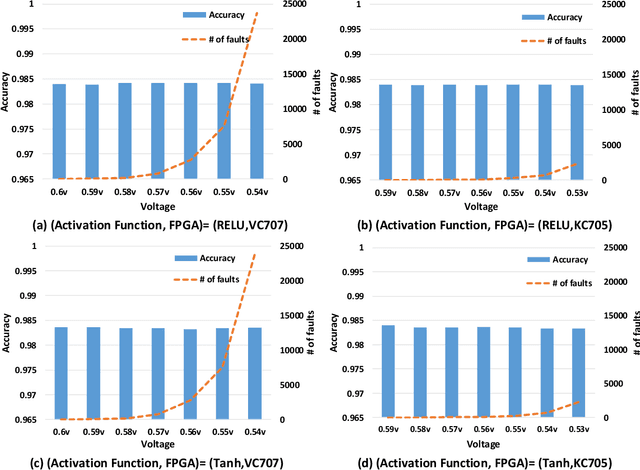
Deep Neural Networks (DNNs) are inherently computation-intensive and also power-hungry. Hardware accelerators such as Field Programmable Gate Arrays (FPGAs) are a promising solution that can satisfy these requirements for both embedded and High-Performance Computing (HPC) systems. In FPGAs, as well as CPUs and GPUs, aggressive voltage scaling below the nominal level is an effective technique for power dissipation minimization. Unfortunately, bit-flip faults start to appear as the voltage is scaled down closer to the transistor threshold due to timing issues, thus creating a resilience issue. This paper experimentally evaluates the resilience of the training phase of DNNs in the presence of voltage underscaling related faults of FPGAs, especially in on-chip memories. Toward this goal, we have experimentally evaluated the resilience of LeNet-5 and also a specially designed network for CIFAR-10 dataset with different activation functions of Rectified Linear Unit (Relu) and Hyperbolic Tangent (Tanh). We have found that modern FPGAs are robust enough in extremely low-voltage levels and that low-voltage related faults can be automatically masked within the training iterations, so there is no need for costly software- or hardware-oriented fault mitigation techniques like ECC. Approximately 10% more training iterations are needed to fill the gap in the accuracy. This observation is the result of the relatively low rate of undervolting faults, i.e., <0.1\%, measured on real FPGA fabrics. We have also increased the fault rate significantly for the LeNet-5 network by randomly generated fault injection campaigns and observed that the training accuracy starts to degrade. When the fault rate increases, the network with Tanh activation function outperforms the one with Relu in terms of accuracy, e.g., when the fault rate is 30% the accuracy difference is 4.92%.
Evaluating Built-in ECC of FPGA on-chip Memories for the Mitigation of Undervolting Faults
Mar 29, 2019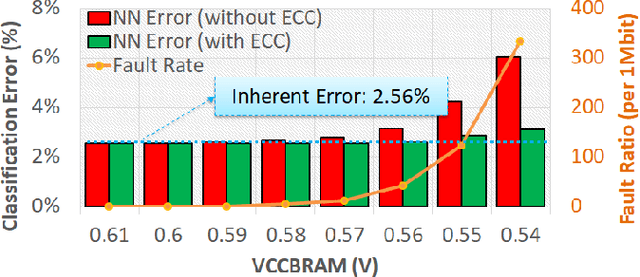

Voltage underscaling below the nominal level is an effective solution for improving energy efficiency in digital circuits, e.g., Field Programmable Gate Arrays (FPGAs). However, further undervolting below a safe voltage level and without accompanying frequency scaling leads to timing related faults, potentially undermining the energy savings. Through experimental voltage underscaling studies on commercial FPGAs, we observed that the rate of these faults exponentially increases for on-chip memories, or Block RAMs (BRAMs). To mitigate these faults, we evaluated the efficiency of the built-in Error-Correction Code (ECC) and observed that more than 90% of the faults are correctable and further 7% are detectable (but not correctable). This efficiency is the result of the single-bit type of these faults, which are then effectively covered by the Single-Error Correction and Double-Error Detection (SECDED) design of the built-in ECC. Finally, motivated by the above experimental observations, we evaluated an FPGA-based Neural Network (NN) accelerator under low-voltage operations, while built-in ECC is leveraged to mitigate undervolting faults and thus, prevent NN significant accuracy loss. In consequence, we achieve 40% of the BRAM power saving through undervolting below the minimum safe voltage level, with a negligible NN accuracy loss, thanks to the substantial fault coverage by the built-in ECC.
On the Resilience of RTL NN Accelerators: Fault Characterization and Mitigation
Jun 14, 2018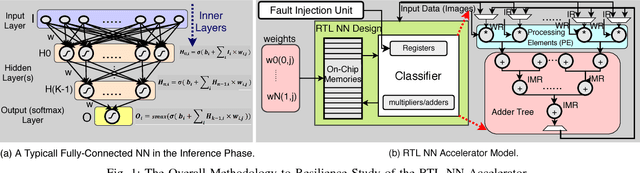
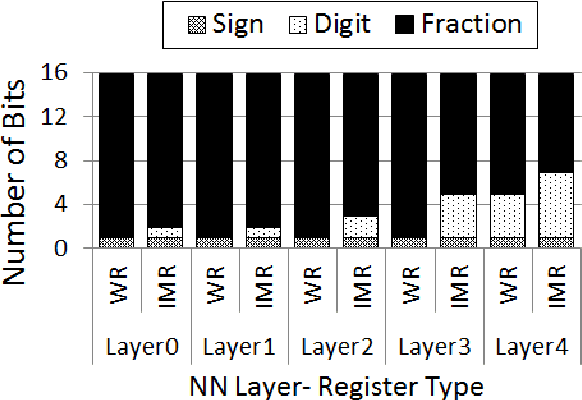
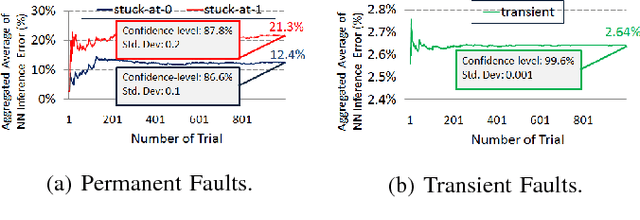
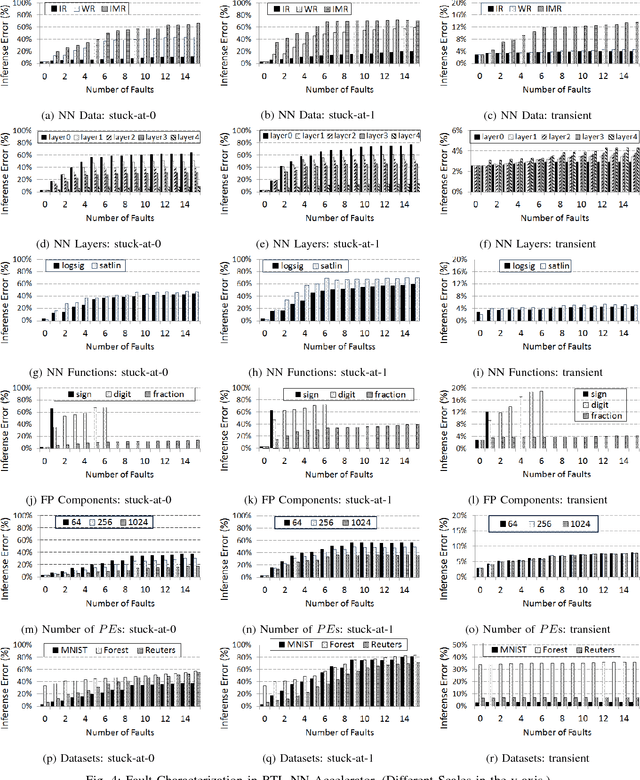
Machine Learning (ML) is making a strong resurgence in tune with the massive generation of unstructured data which in turn requires massive computational resources. Due to the inherently compute- and power-intensive structure of Neural Networks (NNs), hardware accelerators emerge as a promising solution. However, with technology node scaling below 10nm, hardware accelerators become more susceptible to faults, which in turn can impact the NN accuracy. In this paper, we study the resilience aspects of Register-Transfer Level (RTL) model of NN accelerators, in particular, fault characterization and mitigation. By following a High-Level Synthesis (HLS) approach, first, we characterize the vulnerability of various components of RTL NN. We observed that the severity of faults depends on both i) application-level specifications, i.e., NN data (inputs, weights, or intermediate), NN layers, and NN activation functions, and ii) architectural-level specifications, i.e., data representation model and the parallelism degree of the underlying accelerator. Second, motivated by characterization results, we present a low-overhead fault mitigation technique that can efficiently correct bit flips, by 47.3% better than state-of-the-art methods.