 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonia: A Multi-Agent Reinforcement Learning Approach to Data Placement and Migration in Hybrid Storage Systems
Mar 26, 2025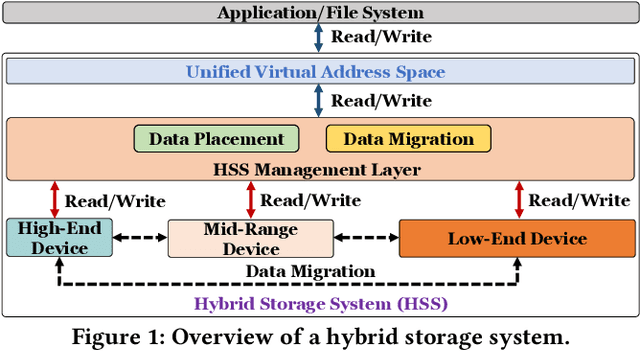
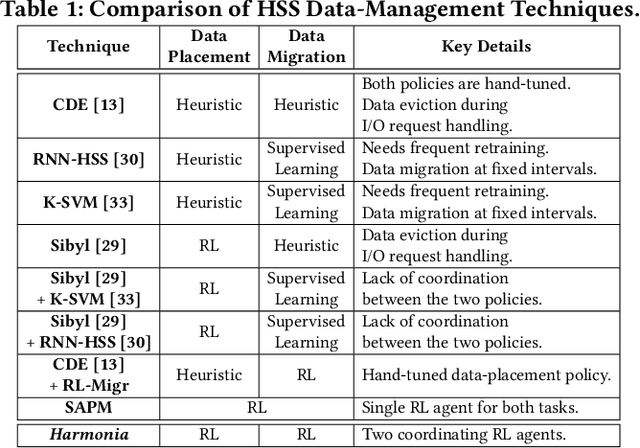

Hybrid storage systems (HSS) combine multiple storage devices with diverse characteristics to achieve high performance and capacity at low cost. The performance of an HSS highly depends on the effectiveness of two key policies: (1) the data-placement policy, which determines the best-fit storage device for incoming data, and (2) the data-migration policy, which rearranges stored data across the devices to sustain high HSS performance. Prior works focus on improving only data placement or only data migration in HSS, which leads to sub-optimal HSS performance. Unfortunately, no prior work tries to optimize both policies together. Our goal is to design a holistic data-management technique for HSS that optimizes both data-placement and data-migration policies to fully exploit the potential of an HSS. We propose Harmonia, a multi-agent reinforcement learning (RL)-based data-management technique that employs two light-weight autonomous RL agents, a data-placement agent and a data-migration agent, which adapt their policies for the current workload and HSS configuration, and coordinate with each other to improve overall HSS performance. We evaluate Harmonia on a real HSS with up to four heterogeneous storage devices with diverse characteristics. Our evaluation using 17 data-intensive workloads on performance-optimized (cost-optimized) HSS with two storage devices shows that, on average, Harmonia (1) outperforms the best-performing prior approach by 49.5% (31.7%), (2) bridges the performance gap between the best-performing prior work and Oracle by 64.2% (64.3%). On an HSS with three (four) devices, Harmonia outperforms the best-performing prior work by 37.0% (42.0%). Harmonia's performance benefits come with low latency (240ns for inference) and storage overheads (206 KiB for both RL agents together). We plan to open-source Harmonia's implementation to aid future research on HSS.
NEON: Enabling Efficient Support for Nonlinear Operations in Resistive RAM-based Neural Network Accelerators
Nov 10, 2022Resistive Random-Access Memory (RRAM) is well-suited to accelerate neural network (NN) workloads as RRAM-based Processing-in-Memory (PIM) architectures natively support highly-parallel multiply-accumulate (MAC) operations that form the backbone of most NN workloads. Unfortunately, NN workloads such as transformers require support for non-MAC operations (e.g., softmax) that RRAM cannot provide natively. Consequently, state-of-the-art works either integrate additional digital logic circuits to support the non-MAC operations or offload the non-MAC operations to CPU/GPU, resulting in significant performance and energy efficiency overheads due to data movement. In this work, we propose NEON, a novel compiler optimization to enable the end-to-end execution of the NN workload in RRAM. The key idea of NEON is to transform each non-MAC operation into a lightweight yet highly-accurate neural network. Utilizing neural networks to approximate the non-MAC operations provides two advantages: 1) We can exploit the key strength of RRAM, i.e., highly-parallel MAC operation, to flexibly and efficiently execute non-MAC operations in memory. 2) We can simplify RRAM's microarchitecture by eliminating the additional digital logic circuits while reducing the data movement overheads. Acceleration of the non-MAC operations in memory enables NEON to achieve a 2.28x speedup compared to an idealized digital logic-based RRAM. We analyze the trade-offs associated with the transformation and demonstrate feasible use cases for NEON across different substrates.
Sibyl: Adaptive and Extensible Data Placement in Hybrid Storage Systems Using Online Reinforcement Learning
May 15, 2022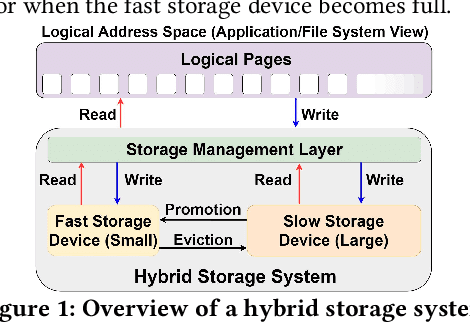

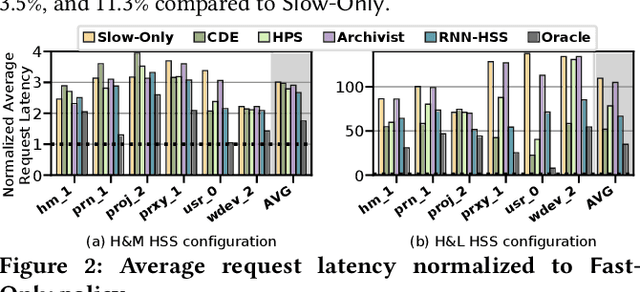
Hybrid storage systems (HSS) use multiple different storage devices to provide high and scalable storage capacity at high performance. Recent research proposes various techniques that aim to accurately identify performance-critical data to place it in a "best-fit" storage device. Unfortunately, most of these techniques are rigid, which (1) limits their adaptivity to perform well for a wide range of workloads and storage device configurations, and (2) makes it difficult for designers to extend these techniques to different storage system configurations (e.g., with a different number or different types of storage devices) than the configuration they are designed for. We introduce Sibyl, the first technique that uses reinforcement learning for data placement in hybrid storage systems. Sibyl observes different features of the running workload as well as the storage devices to make system-aware data placement decisions. For every decision it makes, Sibyl receives a reward from the system that it uses to evaluate the long-term performance impact of its decision and continuously optimizes its data placement policy online. We implement Sibyl on real systems with various HSS configurations. Our results show that Sibyl provides 21.6%/19.9% performance improvement in a performance-oriented/cost-oriented HSS configuration compared to the best previous data placement technique. Our evaluation using an HSS configuration with three different storage devices shows that Sibyl outperforms the state-of-the-art data placement policy by 23.9%-48.2%, while significantly reducing the system architect's burden in designing a data placement mechanism that can simultaneously incorporate three storage devices. We show that Sibyl achieves 80% of the performance of an oracle policy that has complete knowledge of future access patterns while incurring a very modest storage overhead of only 124.4 KiB.
DeepSketch: A New Machine Learning-Based Reference Search Technique for Post-Deduplication Delta Compression
Feb 17, 2022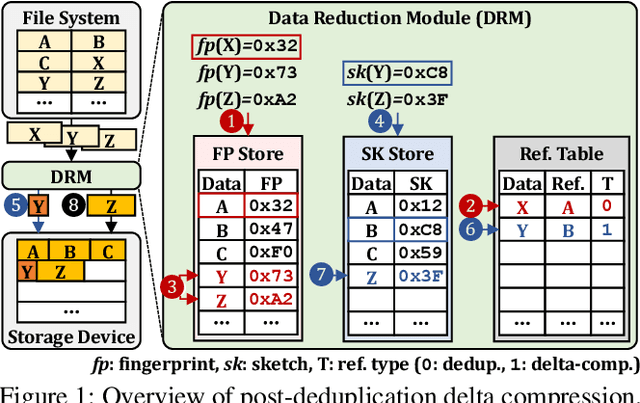
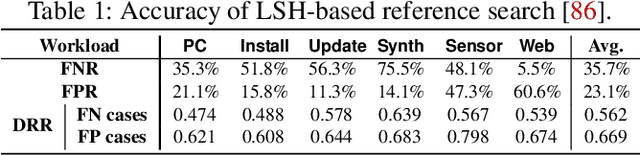
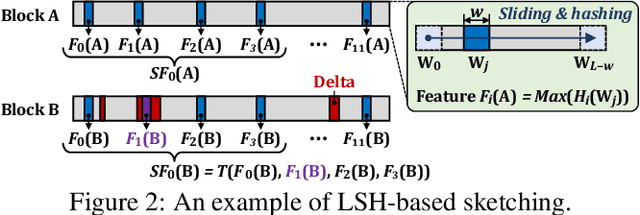
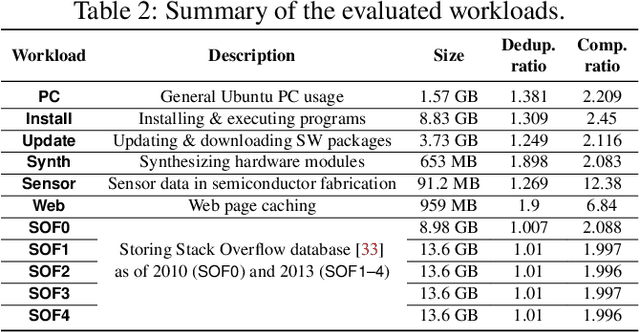
Data reduction in storage systems is becoming increasingly important as an effective solution to minimize the management cost of a data center. To maximize data-reduction efficiency, existing post-deduplication delta-compression techniques perform delta compression along with traditional data deduplication and lossless compression. Unfortunately, we observe that existing techniques achieve significantly lower data-reduction ratios than the optimal due to their limited accuracy in identifying similar data blocks. In this paper, we propose DeepSketch, a new reference search technique for post-deduplication delta compression that leverages the learning-to-hash method to achieve higher accuracy in reference search for delta compression, thereby improving data-reduction efficiency. DeepSketch uses a deep neural network to extract a data block's sketch, i.e., to create an approximate data signature of the block that can preserve similarity with other blocks. Our evaluation using eleven real-world workloads shows that DeepSketch improves the data-reduction ratio by up to 33% (21% on average) over a state-of-the-art post-deduplication delta-compression technique.