 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOKI: a 0.266 pJ/SOP Digital SNN Accelerator with Multi-Cycle Clock-Gated SRAM in 22nm
Nov 14, 2025
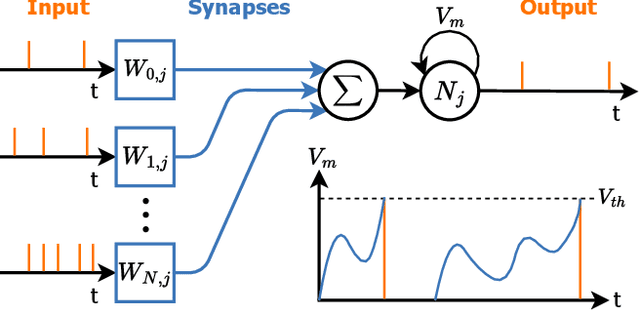


Bio-inspired sensors like Dynamic Vision Sensors (DVS) and silicon cochleas are often combined with Spiking Neural Networks (SNNs), enabling efficient, event-driven processing similar to biological sensory systems. To realize the low-power constraints of the edge, the SNN should run on a hardware architecture that can exploit the sparse nature of the spikes. In this paper, we introduce LOKI, a digital architecture for Fully-Connected (FC) SNNs. By using Multi-Cycle Clock-Gated (MCCG) SRAMs, LOKI can operate at 0.59 V, while running at a clock frequency of 667 MHz. At full throughput, LOKI only consumes 0.266 pJ/SOP. We evaluate LOKI on both the Neuromorphic MNIST (N-MNIST) and the Keyword Spotting k(KWS) tasks, achieving 98.0 % accuracy at 119.8 nJ/inference and 93.0 % accuracy at 546.5 nJ/inference respectively.
Traces Propagation: Memory-Efficient and Scalable Forward-Only Learning in Spiking Neural Networks
Sep 16, 2025Spiking Neural Networks (SNNs) provide an efficient framework for processing dynamic spatio-temporal signals and for investigating the learning principles underlying biological neural systems. A key challenge in training SNNs is to solve both spatial and temporal credit assignment. The dominant approach for training SNNs is Backpropagation Through Time (BPTT) with surrogate gradients. However, BPTT is in stark contrast with the spatial and temporal locality observed in biological neural systems and leads to high computational and memory demands, limiting efficient training strategies and on-device learning. Although existing local learning rules achieve local temporal credit assignment by leveraging eligibility traces, they fail to address the spatial credit assignment without resorting to auxiliary layer-wise matrices, which increase memory overhead and hinder scalability, especially on embedded devices. In this work, we propose Traces Propagation (TP), a forward-only, memory-efficient, scalable, and fully local learning rule that combines eligibility traces with a layer-wise contrastive loss without requiring auxiliary layer-wise matrices. TP outperforms other fully local learning rules on NMNIST and SHD datasets. On more complex datasets such as DVS-GESTURE and DVS-CIFAR10, TP showcases competitive performance and scales effectively to deeper SNN architectures such as VGG-9, while providing favorable memory scaling compared to prior fully local scalable rules, for datasets with a significant number of classes. Finally, we show that TP is well suited for practical fine-tuning tasks, such as keyword spotting on the Google Speech Commands dataset, thus paving the way for efficient learning at the edge.
STEM: Spatial-Temporal Mapping Tool For Spiking Neural Networks
Feb 05, 2025



Spiking Neural Networks (SNNs) are promising bio-inspired third-generation neural networks. Recent research has trained deep SNN models with accuracy on par with Artificial Neural Networks (ANNs). Although the event-driven and sparse nature of SNNs show potential for more energy efficient computation than ANNs, SNN neurons have internal states which evolve over time. Keeping track of SNN states can significantly increase data movement and storage requirements, potentially losing its advantages with respect to ANNs. This paper investigates the energy effects of having neuron states, and how it is influenced by the chosen mapping to realistic hardware architectures with advanced memory hierarchies. Therefore, we develop STEMS, a mapping design space exploration tool for SNNs. STEMS models SNN's stateful behavior and explores intra-layer and inter-layer mapping optimizations to minimize data movement, considering both spatial and temporal SNN dimensions. Using STEMS, we show up to 12x reduction in off-chip data movement and 5x reduction in energy (on top of intra-layer optimizations), on two event-based vision SNN benchmarks. Finally, neuron states may not be needed for all SNN layers. By optimizing neuron states for one of our benchmarks, we show 20x reduction in neuron states and 1.4x better performance without accuracy loss.
Hardware-In-The-Loop Training of a 4f Optical Correlator with Logarithmic Complexity Reduction for CNNs
Jan 07, 2025

This work evaluates a forward-only learning algorithm on the MNIST dataset with hardware-in-the-loop training of a 4f optical correlator, achieving 87.6% accuracy with O(n2) complexity, compared to backpropagation, which achieves 88.8% accuracy with O(n2 log n) complexity.
Probabilistic Inference in the Era of Tensor Networks and Differential Programming
May 22, 2024



Probabilistic inference is a fundamental task in modern machine learning. Recent advances in tensor network (TN) contraction algorithms have enabled the development of better exact inference methods. However, many common inference tasks in probabilistic graphical models (PGMs) still lack corresponding TN-based adaptations. In this work, we advance the connection between PGMs and TNs by formulating and implementing tensor-based solutions for the following inference tasks: (i) computing the partition function, (ii) computing the marginal probability of sets of variables in the model, (iii) determining the most likely assignment to a set of variables, and (iv) the same as (iii) but after having marginalized a different set of variables. We also present a generalized method for generating samples from a learned probability distribution. Our work is motivated by recent technical advances in the fields of quantum circuit simulation, quantum many-body physics, and statistical physics. Through an experimental evaluation, we demonstrate that the integration of these quantum technologies with a series of algorithms introduced in this study significantly improves the effectiveness of existing methods for solving probabilistic inference tasks.
LEAPER: Modeling Cloud FPGA-based Systems via Transfer Learning
Aug 22, 2022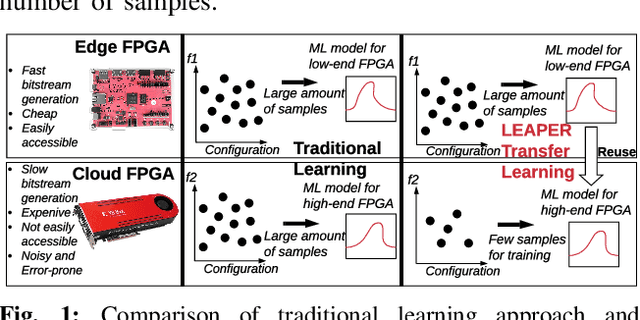
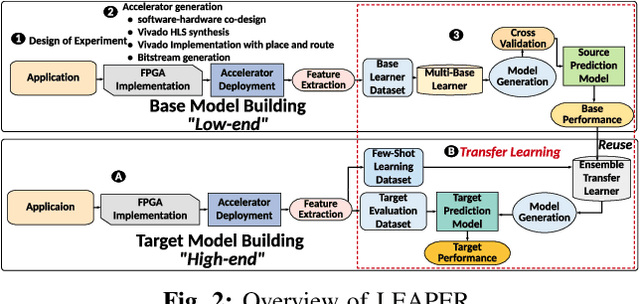
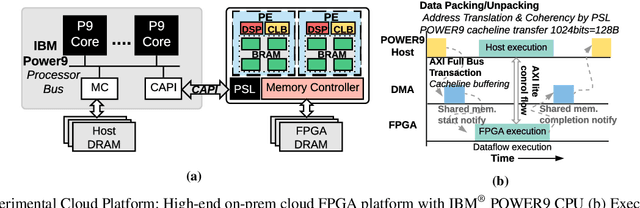
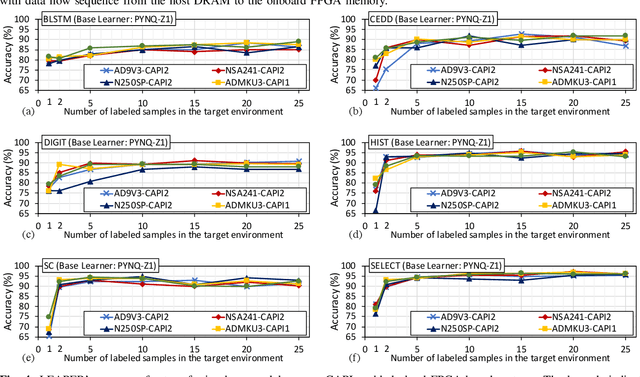
Machine-learning-based models have recently gained traction as a way to overcome the slow downstream implementation process of FPGAs by building models that provide fast and accurate performance predictions. However, these models suffer from two main limitations: (1) training requires large amounts of data (features extracted from FPGA synthesis and implementation reports), which is cost-inefficient because of the time-consuming FPGA design cycle; (2) a model trained for a specific environment cannot predict for a new, unknown environment. In a cloud system, where getting access to platforms is typically costly, data collection for ML models can significantly increase the total cost-ownership (TCO) of a system. To overcome these limitations, we propose LEAPER, a transfer learning-based approach for FPGA-based systems that adapts an existing ML-based model to a new, unknown environment to provide fast and accurate performance and resource utilization predictions. Experimental results show that our approach delivers, on average, 85% accuracy when we use our transferred model for prediction in a cloud environment with 5-shot learning and reduces design-space exploration time by 10x, from days to only a few hours.
Sibyl: Adaptive and Extensible Data Placement in Hybrid Storage Systems Using Online Reinforcement Learning
May 15, 2022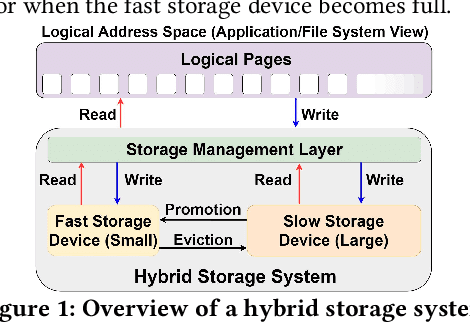

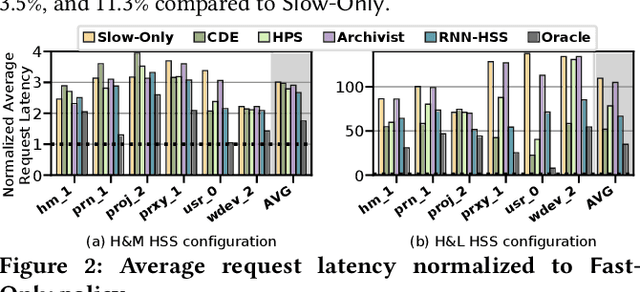
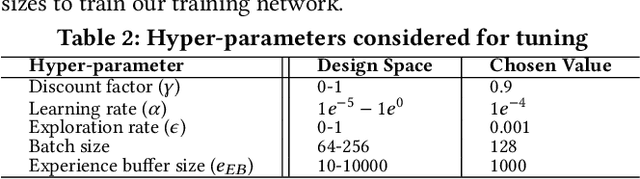
Hybrid storage systems (HSS) use multiple different storage devices to provide high and scalable storage capacity at high performance. Recent research proposes various techniques that aim to accurately identify performance-critical data to place it in a "best-fit" storage device. Unfortunately, most of these techniques are rigid, which (1) limits their adaptivity to perform well for a wide range of workloads and storage device configurations, and (2) makes it difficult for designers to extend these techniques to different storage system configurations (e.g., with a different number or different types of storage devices) than the configuration they are designed for. We introduce Sibyl, the first technique that uses reinforcement learning for data placement in hybrid storage systems. Sibyl observes different features of the running workload as well as the storage devices to make system-aware data placement decisions. For every decision it makes, Sibyl receives a reward from the system that it uses to evaluate the long-term performance impact of its decision and continuously optimizes its data placement policy online. We implement Sibyl on real systems with various HSS configurations. Our results show that Sibyl provides 21.6%/19.9% performance improvement in a performance-oriented/cost-oriented HSS configuration compared to the best previous data placement technique. Our evaluation using an HSS configuration with three different storage devices shows that Sibyl outperforms the state-of-the-art data placement policy by 23.9%-48.2%, while significantly reducing the system architect's burden in designing a data placement mechanism that can simultaneously incorporate three storage devices. We show that Sibyl achieves 80% of the performance of an oracle policy that has complete knowledge of future access patterns while incurring a very modest storage overhead of only 124.4 KiB.