 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Convolutional Recurrent Learning for Efficient Event-based Neuromorphic Object Detection
Jun 16, 2025Leveraging the high temporal resolution and dynamic range, object detection with event cameras can enhance the performance and safety of automotive and robotics applications in real-world scenarios. However, processing sparse event data requires compute-intensive convolutional recurrent units, complicating their integration into resource-constrained edge applications. Here, we propose the Sparse Event-based Efficient Detector (SEED) for efficient event-based object detection on neuromorphic processors. We introduce sparse convolutional recurrent learning, which achieves over 92% activation sparsity in recurrent processing, vastly reducing the cost for spatiotemporal reasoning on sparse event data. We validated our method on Prophesee's 1 Mpx and Gen1 event-based object detection datasets. Notably, SEED sets a new benchmark in computational efficiency for event-based object detection which requires long-term temporal learning. Compared to state-of-the-art methods, SEED significantly reduces synaptic operations while delivering higher or same-level mAP. Our hardware simulations showcase the critical role of SEED's hardware-aware design in achieving energy-efficient and low-latency neuromorphic processing.
STEM: Spatial-Temporal Mapping Tool For Spiking Neural Networks
Feb 05, 2025



Spiking Neural Networks (SNNs) are promising bio-inspired third-generation neural networks. Recent research has trained deep SNN models with accuracy on par with Artificial Neural Networks (ANNs). Although the event-driven and sparse nature of SNNs show potential for more energy efficient computation than ANNs, SNN neurons have internal states which evolve over time. Keeping track of SNN states can significantly increase data movement and storage requirements, potentially losing its advantages with respect to ANNs. This paper investigates the energy effects of having neuron states, and how it is influenced by the chosen mapping to realistic hardware architectures with advanced memory hierarchies. Therefore, we develop STEMS, a mapping design space exploration tool for SNNs. STEMS models SNN's stateful behavior and explores intra-layer and inter-layer mapping optimizations to minimize data movement, considering both spatial and temporal SNN dimensions. Using STEMS, we show up to 12x reduction in off-chip data movement and 5x reduction in energy (on top of intra-layer optimizations), on two event-based vision SNN benchmarks. Finally, neuron states may not be needed for all SNN layers. By optimizing neuron states for one of our benchmarks, we show 20x reduction in neuron states and 1.4x better performance without accuracy loss.
THOR -- A Neuromorphic Processor with 7.29G TSOP$^2$/mm$^2$Js Energy-Throughput Efficiency
Dec 03, 2022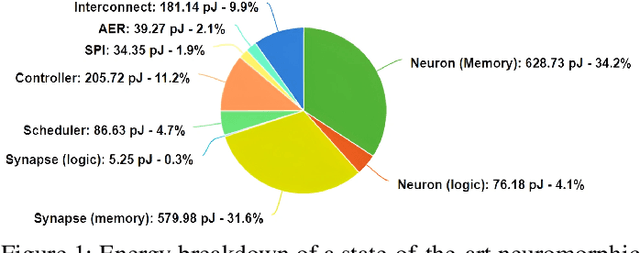
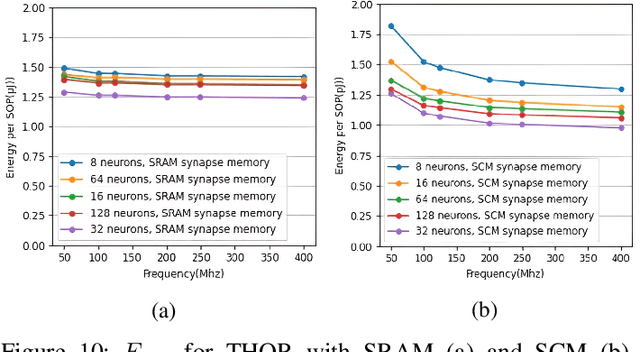
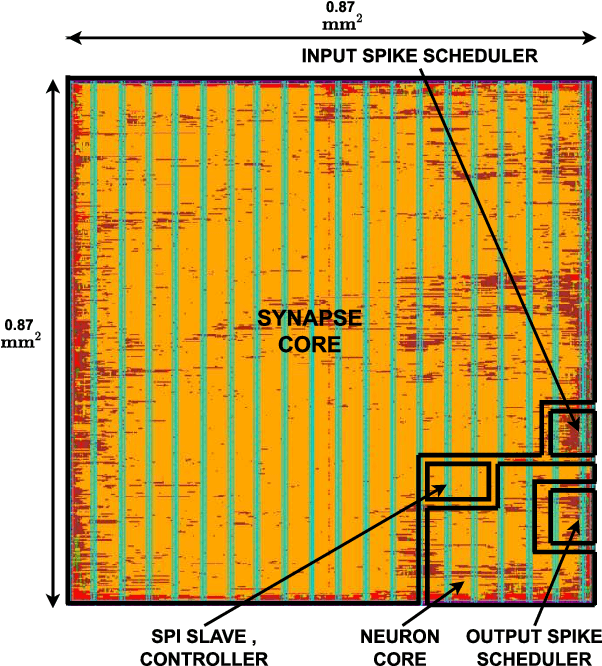
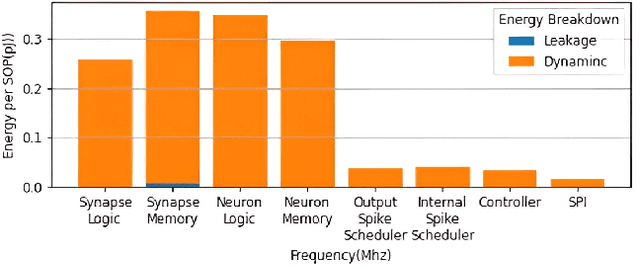
Neuromorphic computing using biologically inspired Spiking Neural Networks (SNNs) is a promising solution to meet Energy-Throughput (ET) efficiency needed for edge computing devices. Neuromorphic hardware architectures that emulate SNNs in analog/mixed-signal domains have been proposed to achieve order-of-magnitude higher energy efficiency than all-digital architectures, however at the expense of limited scalability, susceptibility to noise, complex verification, and poor flexibility. On the other hand, state-of-the-art digital neuromorphic architectures focus either on achieving high energy efficiency (Joules/synaptic operation (SOP)) or throughput efficiency (SOPs/second/area), resulting in poor ET efficiency. In this work, we present THOR, an all-digital neuromorphic processor with a novel memory hierarchy and neuron update architecture that addresses both energy consumption and throughput bottlenecks. We implemented THOR in 28nm FDSOI CMOS technology and our post-layout results demonstrate an ET efficiency of 7.29G $\text{TSOP}^2/\text{mm}^2\text{Js}$ at 0.9V, 400 MHz, which represents a 3X improvement over state-of-the-art digital neuromorphic processors.