 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Convolutional Recurrent Learning for Efficient Event-based Neuromorphic Object Detection
Jun 16, 2025Leveraging the high temporal resolution and dynamic range, object detection with event cameras can enhance the performance and safety of automotive and robotics applications in real-world scenarios. However, processing sparse event data requires compute-intensive convolutional recurrent units, complicating their integration into resource-constrained edge applications. Here, we propose the Sparse Event-based Efficient Detector (SEED) for efficient event-based object detection on neuromorphic processors. We introduce sparse convolutional recurrent learning, which achieves over 92% activation sparsity in recurrent processing, vastly reducing the cost for spatiotemporal reasoning on sparse event data. We validated our method on Prophesee's 1 Mpx and Gen1 event-based object detection datasets. Notably, SEED sets a new benchmark in computational efficiency for event-based object detection which requires long-term temporal learning. Compared to state-of-the-art methods, SEED significantly reduces synaptic operations while delivering higher or same-level mAP. Our hardware simulations showcase the critical role of SEED's hardware-aware design in achieving energy-efficient and low-latency neuromorphic processing.
Efficient Synaptic Delay Implementation in Digital Event-Driven AI Accelerators
Jan 23, 2025Synaptic delay parameterization of neural network models have remained largely unexplored but recent literature has been showing promising results, suggesting the delay parameterized models are simpler, smaller, sparser, and thus more energy efficient than similar performing (e.g. task accuracy) non-delay parameterized ones. We introduce Shared Circular Delay Queue (SCDQ), a novel hardware structure for supporting synaptic delays on digital neuromorphic accelerators. Our analysis and hardware results show that it scales better in terms of memory, than current commonly used approaches, and is more amortizable to algorithm-hardware co-optimizations, where in fact, memory scaling is modulated by model sparsity and not merely network size. Next to memory we also report performance on latency area and energy per inference.
Energy-efficient SNN Architecture using 3nm FinFET Multiport SRAM-based CIM with Online Learning
Oct 11, 2024



Current Artificial Intelligence (AI) computation systems face challenges, primarily from the memory-wall issue, limiting overall system-level performance, especially for Edge devices with constrained battery budgets, such as smartphones, wearables, and Internet-of-Things sensor systems. In this paper, we propose a new SRAM-based Compute-In-Memory (CIM) accelerator optimized for Spiking Neural Networks (SNNs) Inference. Our proposed architecture employs a multiport SRAM design with multiple decoupled Read ports to enhance the throughput and Transposable Read-Write ports to facilitate online learning. Furthermore, we develop an Arbiter circuit for efficient data-processing and port allocations during the computation. Results for a 128$\times$128 array in 3nm FinFET technology demonstrate a 3.1$\times$ improvement in speed and a 2.2$\times$ enhancement in energy efficiency with our proposed multiport SRAM design compared to the traditional single-port design. At system-level, a throughput of 44 MInf/s at 607 pJ/Inf and 29mW is achieved.
Overcoming the Limitations of Layer Synchronization in Spiking Neural Networks
Aug 09, 2024Currently, neural-network processing in machine learning applications relies on layer synchronization, whereby neurons in a layer aggregate incoming currents from all neurons in the preceding layer, before evaluating their activation function. This is practiced even in artificial Spiking Neural Networks (SNNs), which are touted as consistent with neurobiology, in spite of processing in the brain being, in fact asynchronous. A truly asynchronous system however would allow all neurons to evaluate concurrently their threshold and emit spikes upon receiving any presynaptic current. Omitting layer synchronization is potentially beneficial, for latency and energy efficiency, but asynchronous execution of models previously trained with layer synchronization may entail a mismatch in network dynamics and performance. We present a study that documents and quantifies this problem in three datasets on our simulation environment that implements network asynchrony, and we show that models trained with layer synchronization either perform sub-optimally in absence of the synchronization, or they will fail to benefit from any energy and latency reduction, when such a mechanism is in place. We then "make ends meet" and address the problem with unlayered backprop, a novel backpropagation-based training method, for learning models suitable for asynchronous processing. We train with it models that use different neuron execution scheduling strategies, and we show that although their neurons are more reactive, these models consistently exhibit lower overall spike density (up to 50%), reach a correct decision faster (up to 2x) without integrating all spikes, and achieve superior accuracy (up to 10% higher). Our findings suggest that asynchronous event-based (neuromorphic) AI computing is indeed more efficient, but we need to seriously rethink how we train our SNN models, to benefit from it.
Event-based Optical Flow on Neuromorphic Processor: ANN vs. SNN Comparison based on Activation Sparsification
Jul 29, 2024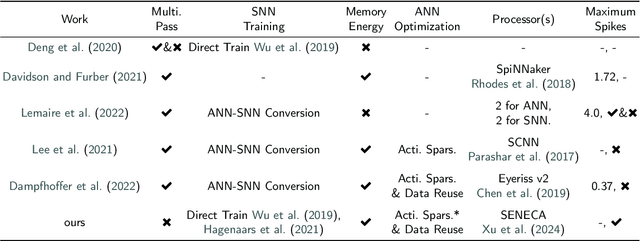
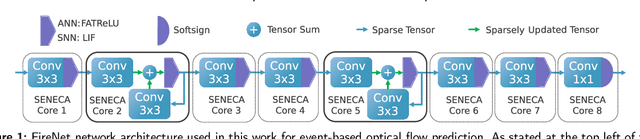
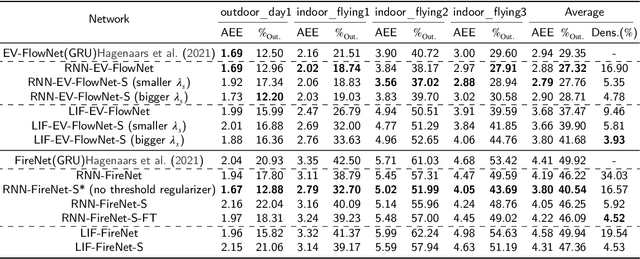
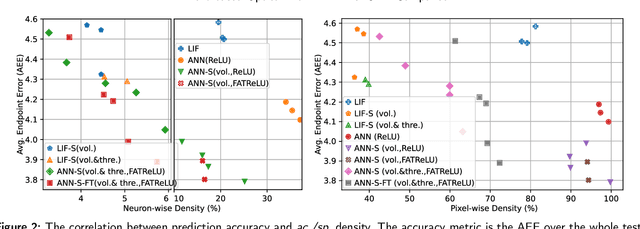
Spiking neural networks (SNNs) for event-based optical flow are claimed to be computationally more efficient than their artificial neural networks (ANNs) counterparts, but a fair comparison is missing in the literature. In this work, we propose an event-based optical flow solution based on activation sparsification and a neuromorphic processor, SENECA. SENECA has an event-driven processing mechanism that can exploit the sparsity in ANN activations and SNN spikes to accelerate the inference of both types of neural networks. The ANN and the SNN for comparison have similar low activation/spike density (~5%) thanks to our novel sparsification-aware training. In the hardware-in-loop experiments designed to deduce the average time and energy consumption, the SNN consumes 44.9ms and 927.0 microjoules, which are 62.5% and 75.2% of the ANN's consumption, respectively. We find that SNN's higher efficiency attributes to its lower pixel-wise spike density (43.5% vs. 66.5%) that requires fewer memory access operations for neuron states.
EON-1: A Brain-Inspired Processor for Near-Sensor Extreme Edge Online Feature Extraction
Jun 25, 2024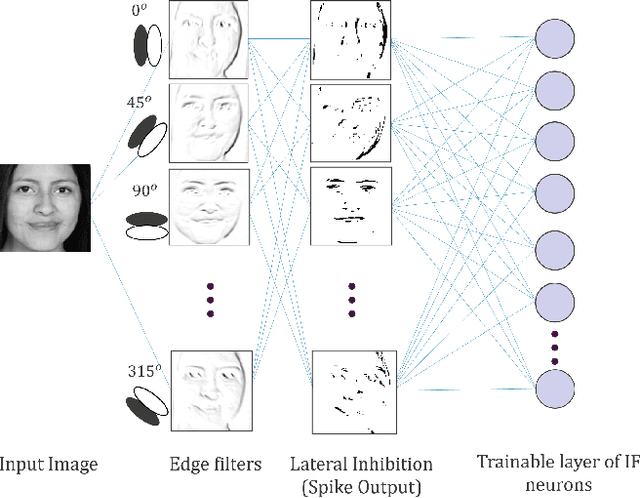
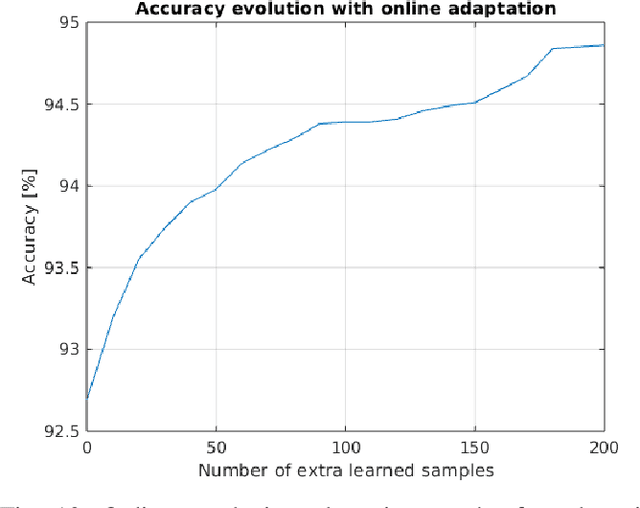
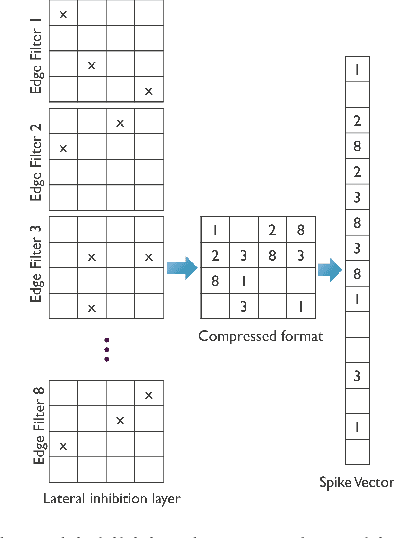
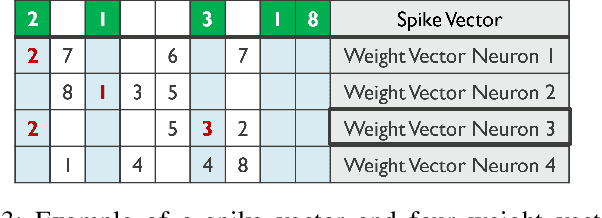
For Edge AI applications, deploying online learning and adaptation on resource-constrained embedded devices can deal with fast sensor-generated streams of data in changing environments. However, since maintaining low-latency and power-efficient inference is paramount at the Edge, online learning and adaptation on the device should impose minimal additional overhead for inference. With this goal in mind, we explore energy-efficient learning and adaptation on-device for streaming-data Edge AI applications using Spiking Neural Networks (SNNs), which follow the principles of brain-inspired computing, such as high-parallelism, neuron co-located memory and compute, and event-driven processing. We propose EON-1, a brain-inspired processor for near-sensor extreme edge online feature extraction, that integrates a fast online learning and adaptation algorithm. We report results of only 1% energy overhead for learning, by far the lowest overhead when compared to other SoTA solutions, while attaining comparable inference accuracy. Furthermore, we demonstrate that EON-1 is up for the challenge of low-latency processing of HD and UHD streaming video in real-time, with learning enabled.
TRIP: Trainable Region-of-Interest Prediction for Hardware-Efficient Neuromorphic Processing on Event-based Vision
Jun 25, 2024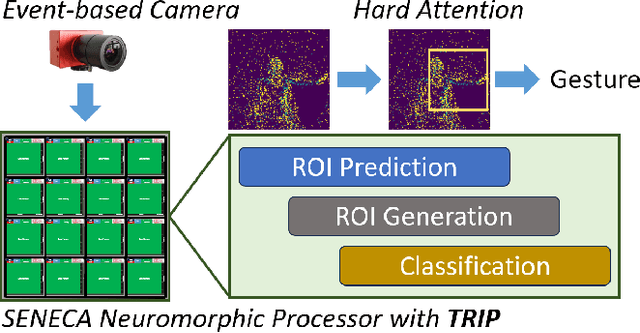
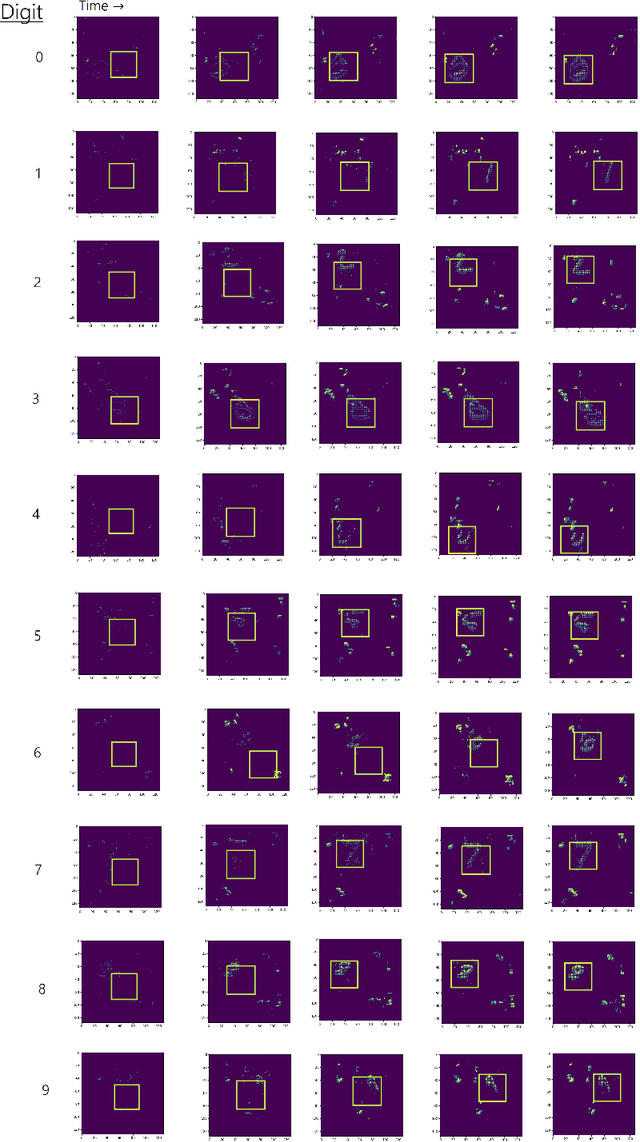
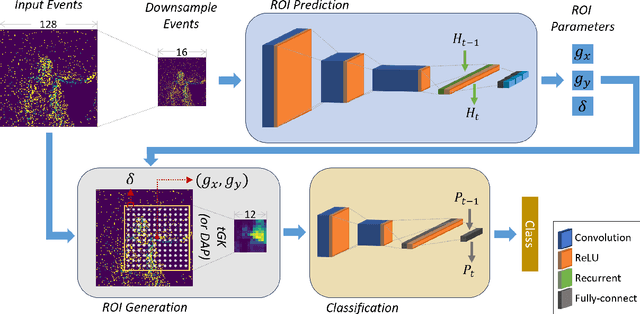
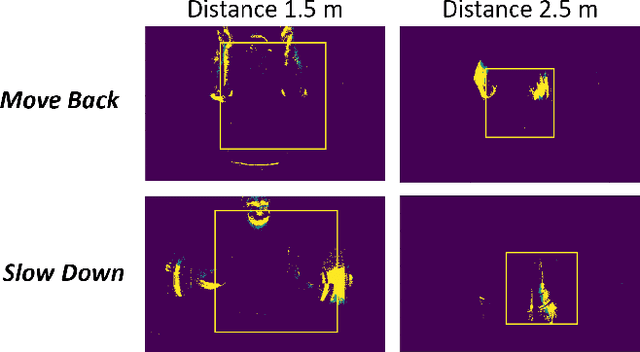
Neuromorphic processors are well-suited for efficiently handling sparse events from event-based cameras. However, they face significant challenges in the growth of computing demand and hardware costs as the input resolution increases. This paper proposes the Trainable Region-of-Interest Prediction (TRIP), the first hardware-efficient hard attention framework for event-based vision processing on a neuromorphic processor. Our TRIP framework actively produces low-resolution Region-of-Interest (ROIs) for efficient and accurate classification. The framework exploits sparse events' inherent low information density to reduce the overhead of ROI prediction. We introduced extensive hardware-aware optimizations for TRIP and implemented the hardware-optimized algorithm on the SENECA neuromorphic processor. We utilized multiple event-based classification datasets for evaluation. Our approach achieves state-of-the-art accuracies in all datasets and produces reasonable ROIs with varying locations and sizes. On the DvsGesture dataset, our solution requires 46x less computation than the state-of-the-art while achieving higher accuracy. Furthermore, TRIP enables more than 2x latency and energy improvements on the SENECA neuromorphic processor compared to the conventional solution.
Hardware-aware training of models with synaptic delays for digital event-driven neuromorphic processors
Apr 16, 2024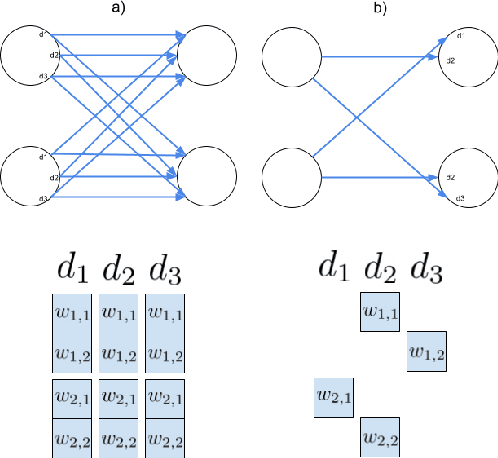
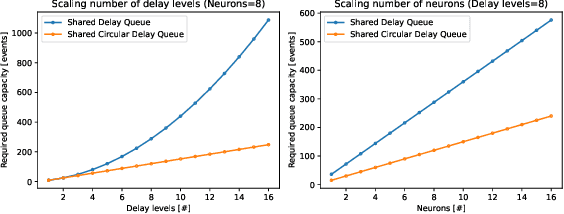
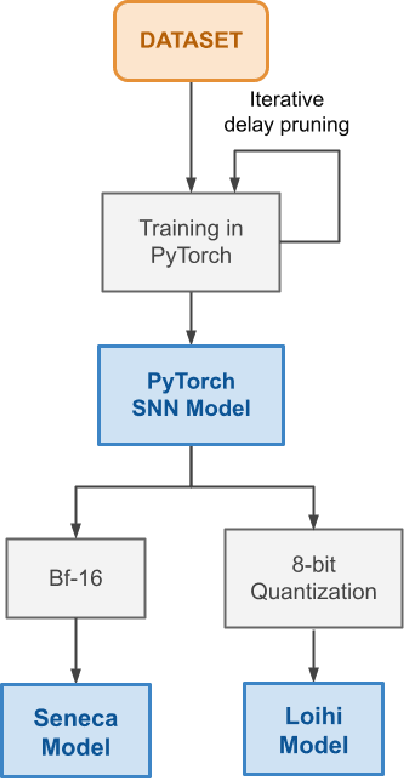
Configurable synaptic delays are a basic feature in many neuromorphic neural network hardware accelerators. However, they have been rarely used in model implementations, despite their promising impact on performance and efficiency in tasks that exhibit complex (temporal) dynamics, as it has been unclear how to optimize them. In this work, we propose a framework to train and deploy, in digital neuromorphic hardware, highly performing spiking neural network models (SNNs) where apart from the synaptic weights, the per-synapse delays are also co-optimized. Leveraging spike-based back-propagation-through-time, the training accounts for both platform constraints, such as synaptic weight precision and the total number of parameters per core, as a function of the network size. In addition, a delay pruning technique is used to reduce memory footprint with a low cost in performance. We evaluate trained models in two neuromorphic digital hardware platforms: Intel Loihi and Imec Seneca. Loihi offers synaptic delay support using the so-called Ring-Buffer hardware structure. Seneca does not provide native hardware support for synaptic delays. A second contribution of this paper is therefore a novel area- and memory-efficient hardware structure for acceleration of synaptic delays, which we have integrated in Seneca. The evaluated benchmark involves several models for solving the SHD (Spiking Heidelberg Digits) classification task, where minimal accuracy degradation during the transition from software to hardware is demonstrated. To our knowledge, this is the first work showcasing how to train and deploy hardware-aware models parameterized with synaptic delays, on multicore neuromorphic hardware accelerators.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Open the box of digital neuromorphic processor: Towards effective algorithm-hardware co-design
Mar 27, 2023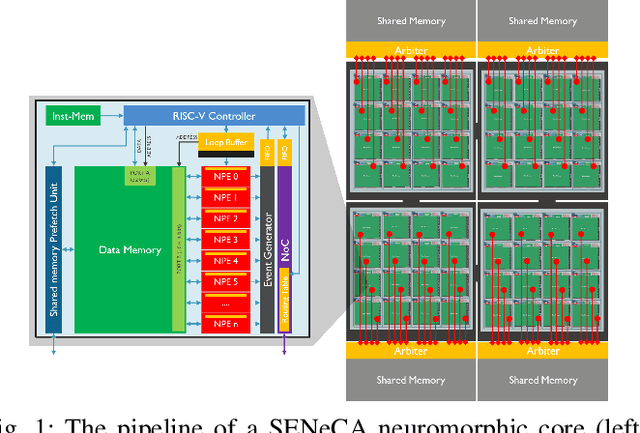
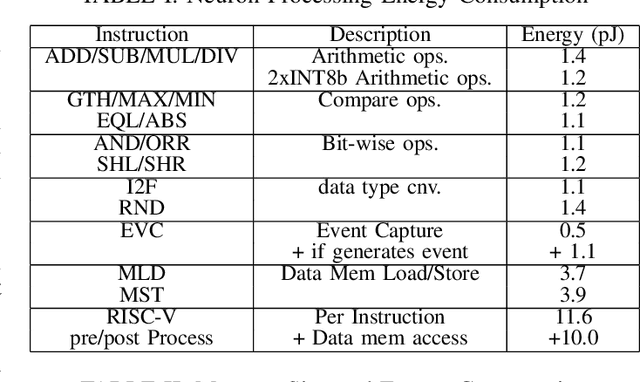
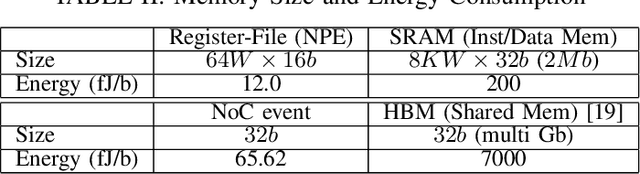
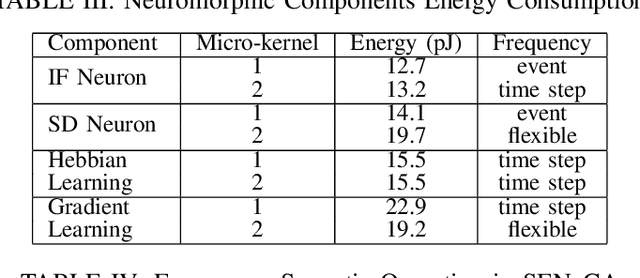
Sparse and event-driven spiking neural network (SNN) algorithms are the ideal candidate solution for energy-efficient edge computing. Yet, with the growing complexity of SNN algorithms, it isn't easy to properly benchmark and optimize their computational cost without hardware in the loop. Although digital neuromorphic processors have been widely adopted to benchmark SNN algorithms, their black-box nature is problematic for algorithm-hardware co-optimization. In this work, we open the black box of the digital neuromorphic processor for algorithm designers by presenting the neuron processing instruction set and detailed energy consumption of the SENeCA neuromorphic architecture. For convenient benchmarking and optimization, we provide the energy cost of the essential neuromorphic components in SENeCA, including neuron models and learning rules. Moreover, we exploit the SENeCA's hierarchical memory and exhibit an advantage over existing neuromorphic processors. We show the energy efficiency of SNN algorithms for video processing and online learning, and demonstrate the potential of our work for optimizing algorithm designs. Overall, we present a practical approach to enable algorithm designers to accurately benchmark SNN algorithms and pave the way towards effective algorithm-hardware co-design.