 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIP: Trainable Region-of-Interest Prediction for Hardware-Efficient Neuromorphic Processing on Event-based Vision
Jun 25, 2024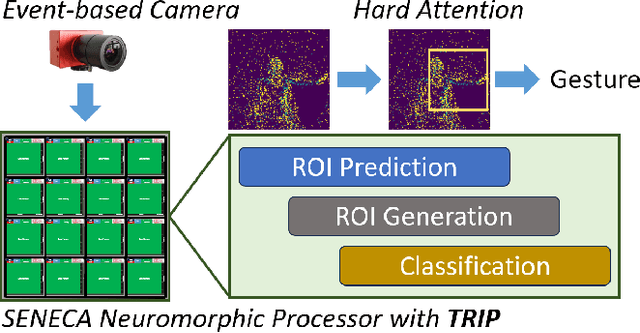
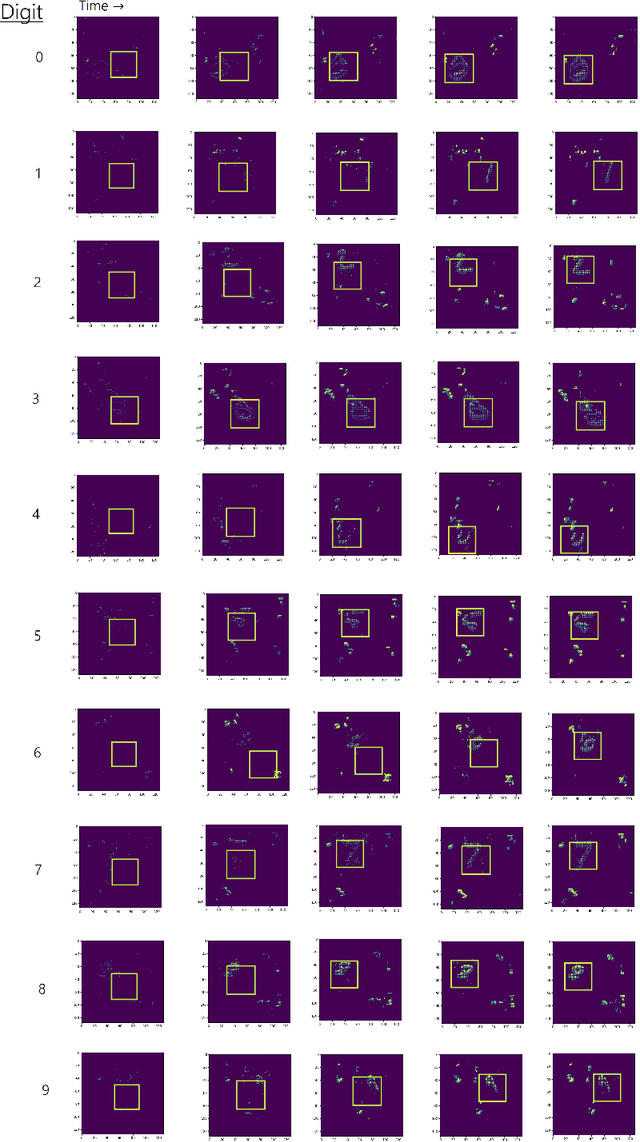
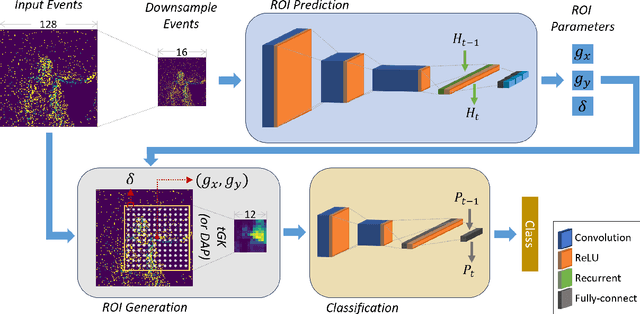
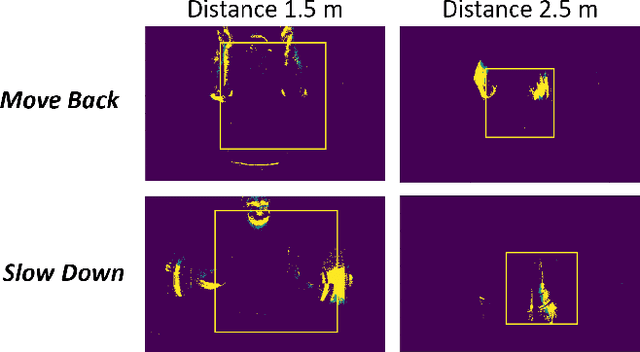
Neuromorphic processors are well-suited for efficiently handling sparse events from event-based cameras. However, they face significant challenges in the growth of computing demand and hardware costs as the input resolution increases. This paper proposes the Trainable Region-of-Interest Prediction (TRIP), the first hardware-efficient hard attention framework for event-based vision processing on a neuromorphic processor. Our TRIP framework actively produces low-resolution Region-of-Interest (ROIs) for efficient and accurate classification. The framework exploits sparse events' inherent low information density to reduce the overhead of ROI prediction. We introduced extensive hardware-aware optimizations for TRIP and implemented the hardware-optimized algorithm on the SENECA neuromorphic processor. We utilized multiple event-based classification datasets for evaluation. Our approach achieves state-of-the-art accuracies in all datasets and produces reasonable ROIs with varying locations and sizes. On the DvsGesture dataset, our solution requires 46x less computation than the state-of-the-art while achieving higher accuracy. Furthermore, TRIP enables more than 2x latency and energy improvements on the SENECA neuromorphic processor compared to the conventional solution.
Open the box of digital neuromorphic processor: Towards effective algorithm-hardware co-design
Mar 27, 2023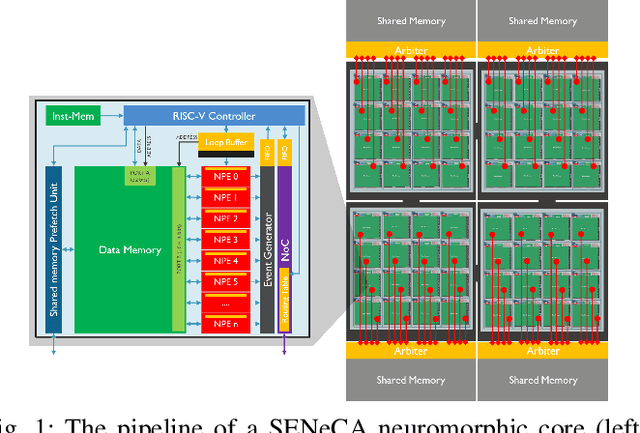
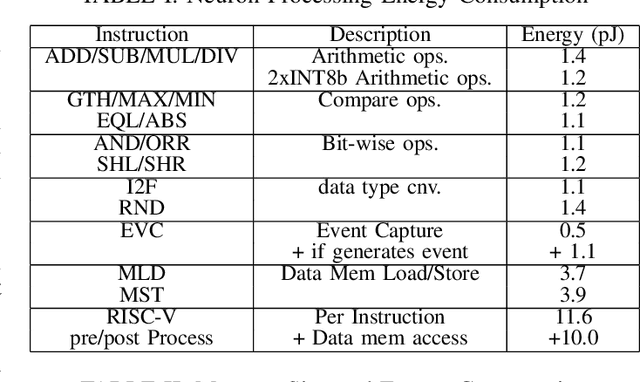
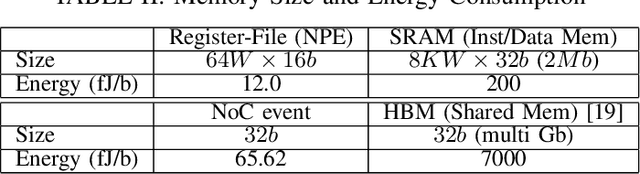
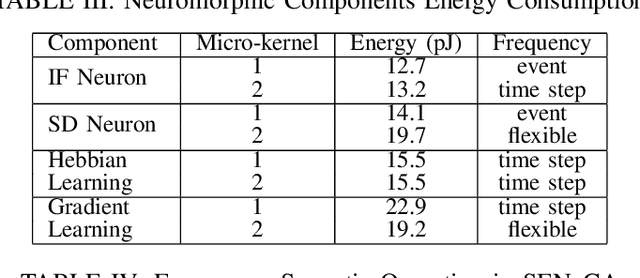
Sparse and event-driven spiking neural network (SNN) algorithms are the ideal candidate solution for energy-efficient edge computing. Yet, with the growing complexity of SNN algorithms, it isn't easy to properly benchmark and optimize their computational cost without hardware in the loop. Although digital neuromorphic processors have been widely adopted to benchmark SNN algorithms, their black-box nature is problematic for algorithm-hardware co-optimization. In this work, we open the black box of the digital neuromorphic processor for algorithm designers by presenting the neuron processing instruction set and detailed energy consumption of the SENeCA neuromorphic architecture. For convenient benchmarking and optimization, we provide the energy cost of the essential neuromorphic components in SENeCA, including neuron models and learning rules. Moreover, we exploit the SENeCA's hierarchical memory and exhibit an advantage over existing neuromorphic processors. We show the energy efficiency of SNN algorithms for video processing and online learning, and demonstrate the potential of our work for optimizing algorithm designs. Overall, we present a practical approach to enable algorithm designers to accurately benchmark SNN algorithms and pave the way towards effective algorithm-hardware co-design.