 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Synaptic Delay Implementation in Digital Event-Driven AI Accelerators
Jan 23, 2025Synaptic delay parameterization of neural network models have remained largely unexplored but recent literature has been showing promising results, suggesting the delay parameterized models are simpler, smaller, sparser, and thus more energy efficient than similar performing (e.g. task accuracy) non-delay parameterized ones. We introduce Shared Circular Delay Queue (SCDQ), a novel hardware structure for supporting synaptic delays on digital neuromorphic accelerators. Our analysis and hardware results show that it scales better in terms of memory, than current commonly used approaches, and is more amortizable to algorithm-hardware co-optimizations, where in fact, memory scaling is modulated by model sparsity and not merely network size. Next to memory we also report performance on latency area and energy per inference.
EON-1: A Brain-Inspired Processor for Near-Sensor Extreme Edge Online Feature Extraction
Jun 25, 2024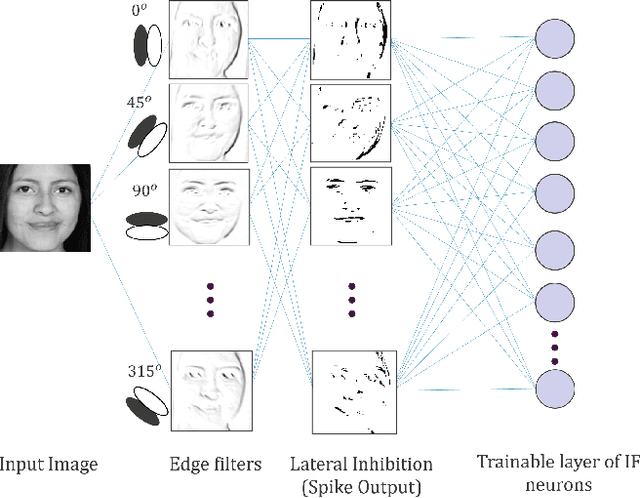
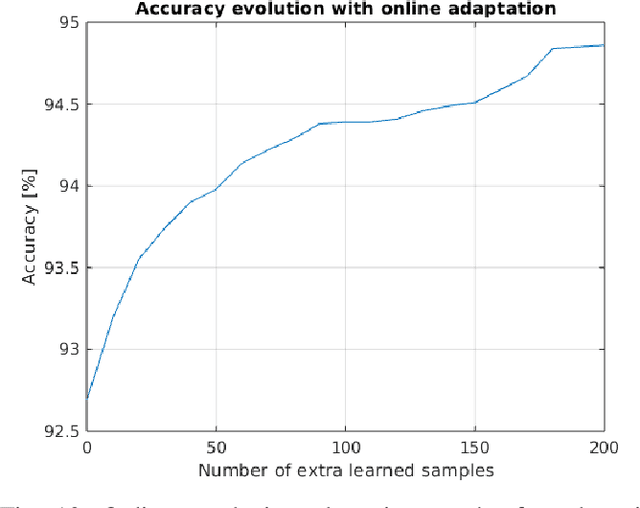
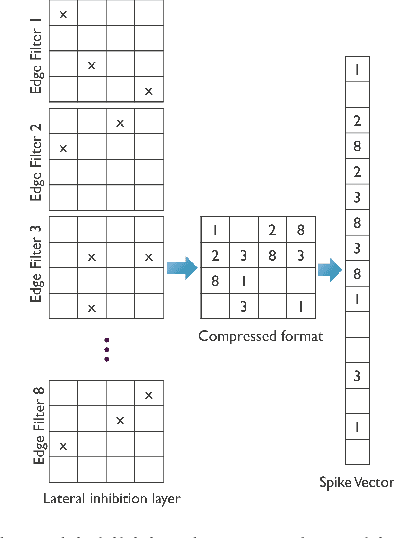
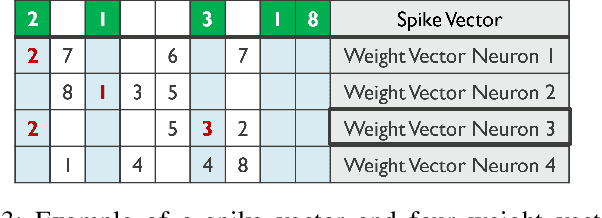
For Edge AI applications, deploying online learning and adaptation on resource-constrained embedded devices can deal with fast sensor-generated streams of data in changing environments. However, since maintaining low-latency and power-efficient inference is paramount at the Edge, online learning and adaptation on the device should impose minimal additional overhead for inference. With this goal in mind, we explore energy-efficient learning and adaptation on-device for streaming-data Edge AI applications using Spiking Neural Networks (SNNs), which follow the principles of brain-inspired computing, such as high-parallelism, neuron co-located memory and compute, and event-driven processing. We propose EON-1, a brain-inspired processor for near-sensor extreme edge online feature extraction, that integrates a fast online learning and adaptation algorithm. We report results of only 1% energy overhead for learning, by far the lowest overhead when compared to other SoTA solutions, while attaining comparable inference accuracy. Furthermore, we demonstrate that EON-1 is up for the challenge of low-latency processing of HD and UHD streaming video in real-time, with learning enabled.
TRIP: Trainable Region-of-Interest Prediction for Hardware-Efficient Neuromorphic Processing on Event-based Vision
Jun 25, 2024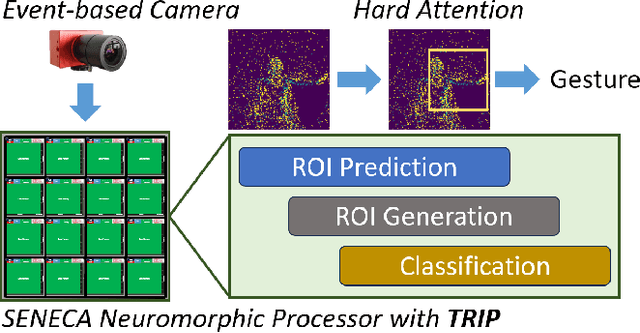
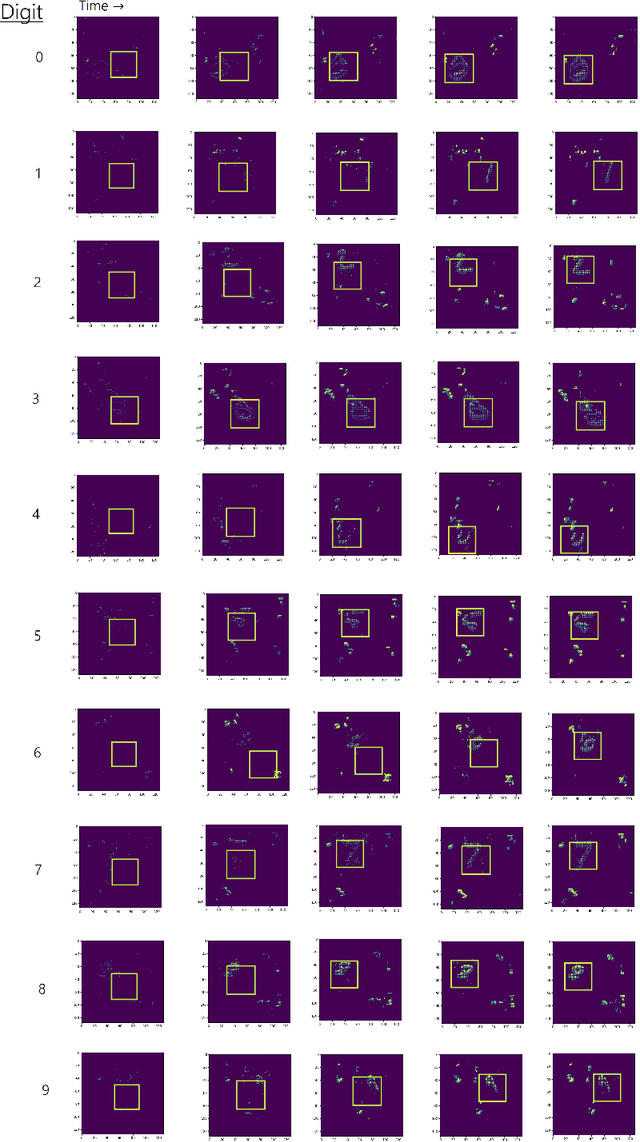
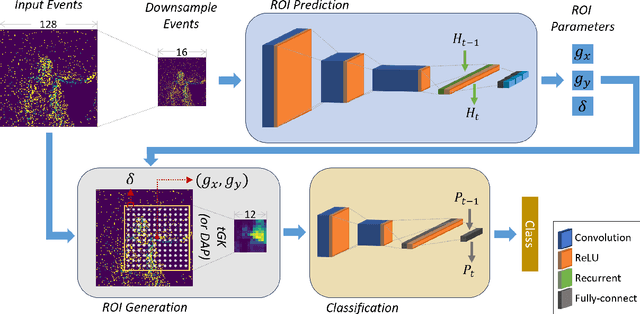
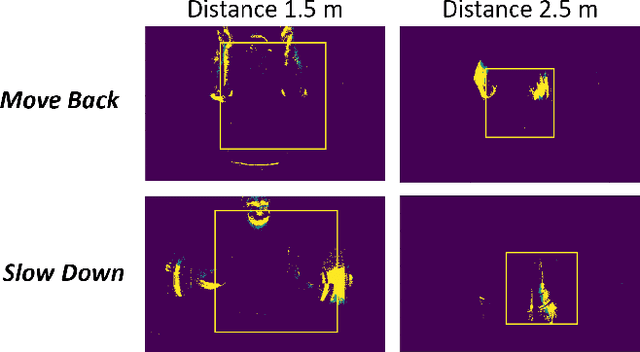
Neuromorphic processors are well-suited for efficiently handling sparse events from event-based cameras. However, they face significant challenges in the growth of computing demand and hardware costs as the input resolution increases. This paper proposes the Trainable Region-of-Interest Prediction (TRIP), the first hardware-efficient hard attention framework for event-based vision processing on a neuromorphic processor. Our TRIP framework actively produces low-resolution Region-of-Interest (ROIs) for efficient and accurate classification. The framework exploits sparse events' inherent low information density to reduce the overhead of ROI prediction. We introduced extensive hardware-aware optimizations for TRIP and implemented the hardware-optimized algorithm on the SENECA neuromorphic processor. We utilized multiple event-based classification datasets for evaluation. Our approach achieves state-of-the-art accuracies in all datasets and produces reasonable ROIs with varying locations and sizes. On the DvsGesture dataset, our solution requires 46x less computation than the state-of-the-art while achieving higher accuracy. Furthermore, TRIP enables more than 2x latency and energy improvements on the SENECA neuromorphic processor compared to the conventional solution.