 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Synaptic Delay Implementation in Digital Event-Driven AI Accelerators
Jan 23, 2025Synaptic delay parameterization of neural network models have remained largely unexplored but recent literature has been showing promising results, suggesting the delay parameterized models are simpler, smaller, sparser, and thus more energy efficient than similar performing (e.g. task accuracy) non-delay parameterized ones. We introduce Shared Circular Delay Queue (SCDQ), a novel hardware structure for supporting synaptic delays on digital neuromorphic accelerators. Our analysis and hardware results show that it scales better in terms of memory, than current commonly used approaches, and is more amortizable to algorithm-hardware co-optimizations, where in fact, memory scaling is modulated by model sparsity and not merely network size. Next to memory we also report performance on latency area and energy per inference.
Hardware-aware training of models with synaptic delays for digital event-driven neuromorphic processors
Apr 16, 2024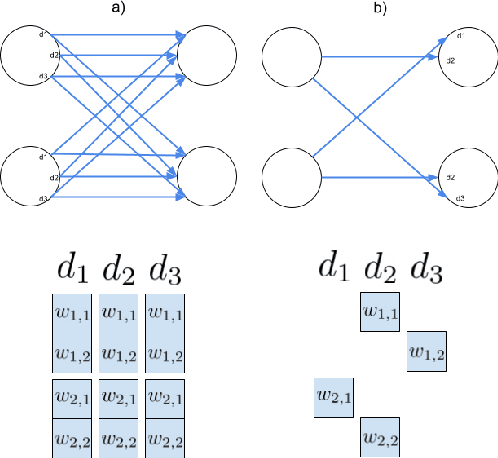
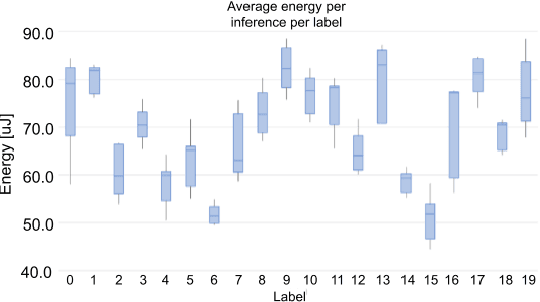
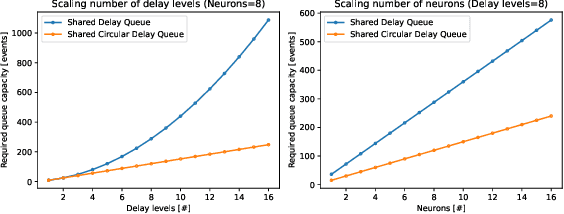
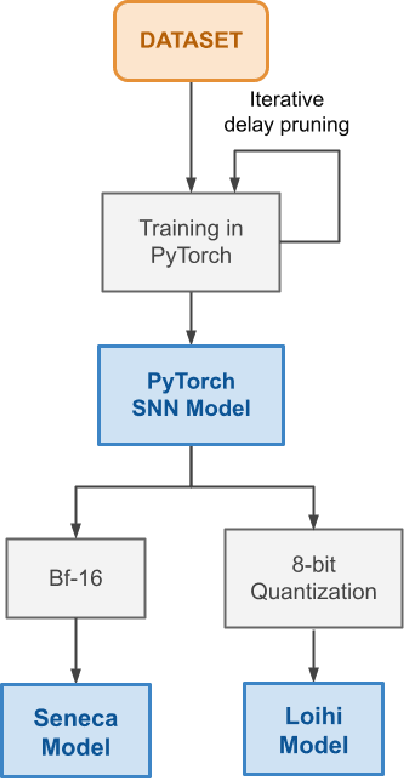
Configurable synaptic delays are a basic feature in many neuromorphic neural network hardware accelerators. However, they have been rarely used in model implementations, despite their promising impact on performance and efficiency in tasks that exhibit complex (temporal) dynamics, as it has been unclear how to optimize them. In this work, we propose a framework to train and deploy, in digital neuromorphic hardware, highly performing spiking neural network models (SNNs) where apart from the synaptic weights, the per-synapse delays are also co-optimized. Leveraging spike-based back-propagation-through-time, the training accounts for both platform constraints, such as synaptic weight precision and the total number of parameters per core, as a function of the network size. In addition, a delay pruning technique is used to reduce memory footprint with a low cost in performance. We evaluate trained models in two neuromorphic digital hardware platforms: Intel Loihi and Imec Seneca. Loihi offers synaptic delay support using the so-called Ring-Buffer hardware structure. Seneca does not provide native hardware support for synaptic delays. A second contribution of this paper is therefore a novel area- and memory-efficient hardware structure for acceleration of synaptic delays, which we have integrated in Seneca. The evaluated benchmark involves several models for solving the SHD (Spiking Heidelberg Digits) classification task, where minimal accuracy degradation during the transition from software to hardware is demonstrated. To our knowledge, this is the first work showcasing how to train and deploy hardware-aware models parameterized with synaptic delays, on multicore neuromorphic hardware accelerators.