 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridFL: A Federated Learning Approach for Financial Crime Detection
Feb 22, 2026Federated learning (FL) is a privacy-preserving machine learning paradigm that enables multiple parties to collaboratively train models on privately owned data without sharing raw information. While standard FL typically addresses either horizontal or vertical data partitions, many real-world scenarios exhibit a complex hybrid distribution. This paper proposes Hybrid Federated Learning (HybridFL) to address data split both horizontally across disjoint users and vertically across complementary feature sets. We evaluate HybridFL in a financial crime detection context, where a transaction party holds transaction-level attributes and multiple banks maintain private account-level features. By integrating horizontal aggregation and vertical feature fusion, the proposed architecture enables joint learning while strictly preserving data locality. Experiments on AMLSim and SWIFT datasets demonstrate that HybridFL significantly outperforms the transaction-only local model and achieves performance comparable to a centralized benchmark.
Reliable Brain Tumor Segmentation Based on Spiking Neural Networks with Efficient Training
Jan 23, 2026We propose a reliable and energy-efficient framework for 3D brain tumor segmentation using spiking neural networks (SNNs). A multi-view ensemble of sagittal, coronal, and axial SNN models provides voxel-wise uncertainty estimation and enhances segmentation robustness. To address the high computational cost in training SNN models for semantic image segmentation, we employ Forward Propagation Through Time (FPTT), which maintains temporal learning efficiency with significantly reduced computational cost. Experiments on the Multimodal Brain Tumor Segmentation Challenges (BraTS 2017 and BraTS 2023) demonstrate competitive accuracy, well-calibrated uncertainty, and an 87% reduction in FLOPs, underscoring the potential of SNNs for reliable, low-power medical IoT and Point-of-Care systems.
Context-aware Sparse Spatiotemporal Learning for Event-based Vision
Aug 27, 2025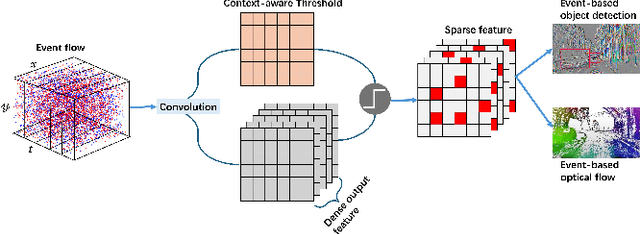
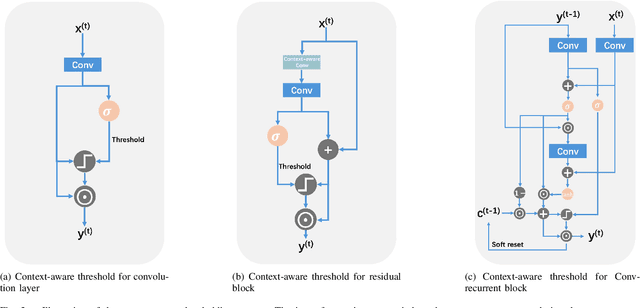
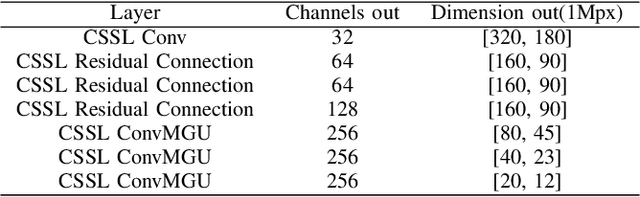
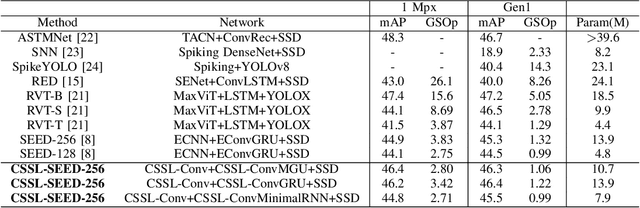
Event-based camera has emerged as a promising paradigm for robot perception, offering advantages with high temporal resolution, high dynamic range, and robustness to motion blur. However, existing deep learning-based event processing methods often fail to fully leverage the sparse nature of event data, complicating their integration into resource-constrained edge applications. While neuromorphic computing provides an energy-efficient alternative, spiking neural networks struggle to match of performance of state-of-the-art models in complex event-based vision tasks, like object detection and optical flow. Moreover, achieving high activation sparsity in neural networks is still difficult and often demands careful manual tuning of sparsity-inducing loss terms. Here, we propose Context-aware Sparse Spatiotemporal Learning (CSSL), a novel framework that introduces context-aware thresholding to dynamically regulate neuron activations based on the input distribution, naturally reducing activation density without explicit sparsity constraints. Applied to event-based object detection and optical flow estimation, CSSL achieves comparable or superior performance to state-of-the-art methods while maintaining extremely high neuronal sparsity. Our experimental results highlight CSSL's crucial role in enabling efficient event-based vision for neuromorphic processing.
Sparse Convolutional Recurrent Learning for Efficient Event-based Neuromorphic Object Detection
Jun 16, 2025Leveraging the high temporal resolution and dynamic range, object detection with event cameras can enhance the performance and safety of automotive and robotics applications in real-world scenarios. However, processing sparse event data requires compute-intensive convolutional recurrent units, complicating their integration into resource-constrained edge applications. Here, we propose the Sparse Event-based Efficient Detector (SEED) for efficient event-based object detection on neuromorphic processors. We introduce sparse convolutional recurrent learning, which achieves over 92% activation sparsity in recurrent processing, vastly reducing the cost for spatiotemporal reasoning on sparse event data. We validated our method on Prophesee's 1 Mpx and Gen1 event-based object detection datasets. Notably, SEED sets a new benchmark in computational efficiency for event-based object detection which requires long-term temporal learning. Compared to state-of-the-art methods, SEED significantly reduces synaptic operations while delivering higher or same-level mAP. Our hardware simulations showcase the critical role of SEED's hardware-aware design in achieving energy-efficient and low-latency neuromorphic processing.
SteelBlastQC: Shot-blasted Steel Surface Dataset with Interpretable Detection of Surface Defects
Apr 29, 2025Automating the quality control of shot-blasted steel surfaces is crucial for improving manufacturing efficiency and consistency. This study presents a dataset of 1654 labeled RGB images (512x512) of steel surfaces, classified as either "ready for paint" or "needs shot-blasting." The dataset captures real-world surface defects, including discoloration, welding lines, scratches and corrosion, making it well-suited for training computer vision models. Additionally, three classification approaches were evaluated: Compact Convolutional Transformers (CCT), Support Vector Machines (SVM) with ResNet-50 feature extraction, and a Convolutional Autoencoder (CAE). The supervised methods (CCT and SVM) achieve 95% classification accuracy on the test set, with CCT leveraging transformer-based attention mechanisms and SVM offering a computationally efficient alternative. The CAE approach, while less effective, establishes a baseline for unsupervised quality control. We present interpretable decision-making by all three neural networks, allowing industry users to visually pinpoint problematic regions and understand the model's rationale. By releasing the dataset and baseline codes, this work aims to support further research in defect detection, advance the development of interpretable computer vision models for quality control, and encourage the adoption of automated inspection systems in industrial applications.
Adaptively Pruned Spiking Neural Networks for Energy-Efficient Intracortical Neural Decoding
Apr 15, 2025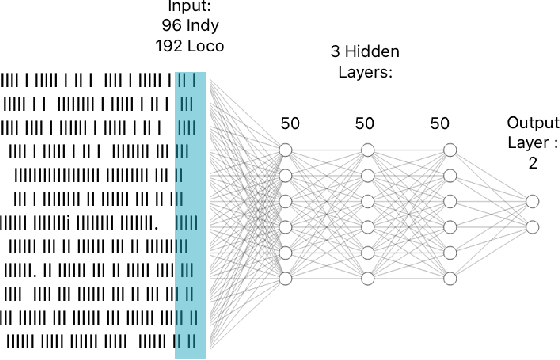
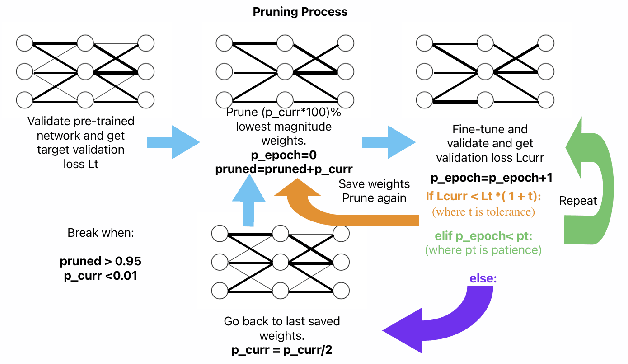
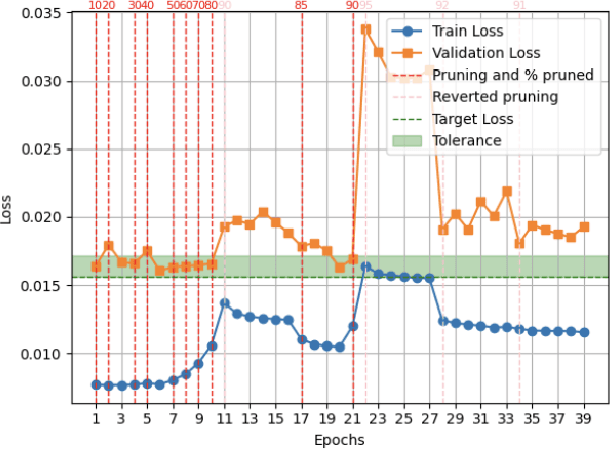
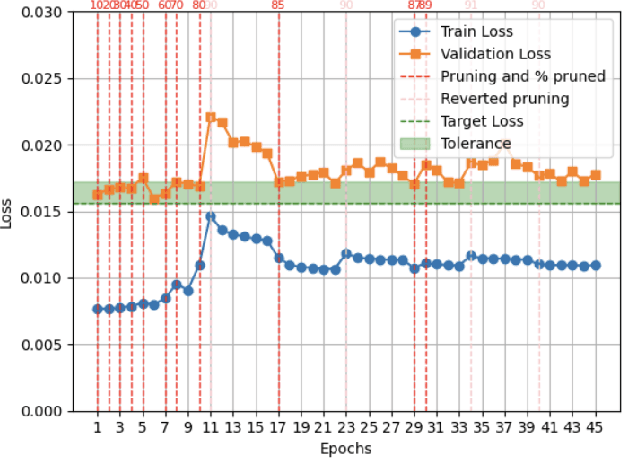
Intracortical brain-machine interfaces demand low-latency, energy-efficient solutions for neural decoding. Spiking Neural Networks (SNNs) deployed on neuromorphic hardware have demonstrated remarkable efficiency in neural decoding by leveraging sparse binary activations and efficient spatiotemporal processing. However, reducing the computational cost of SNNs remains a critical challenge for developing ultra-efficient intracortical neural implants. In this work, we introduce a novel adaptive pruning algorithm specifically designed for SNNs with high activation sparsity, targeting intracortical neural decoding. Our method dynamically adjusts pruning decisions and employs a rollback mechanism to selectively eliminate redundant synaptic connections without compromising decoding accuracy. Experimental evaluation on the NeuroBench Non-Human Primate (NHP) Motor Prediction benchmark shows that our pruned network achieves performance comparable to dense networks, with a maximum tenfold improvement in efficiency. Moreover, hardware simulation on the neuromorphic processor reveals that the pruned network operates at sub-$\mu$W power levels, underscoring its potential for energy-constrained neural implants. These results underscore the promise of our approach for advancing energy-efficient intracortical brain-machine interfaces with low-overhead on-device intelligence.
Predicting the Lifespan of Industrial Printheads with Survival Analysis
Apr 10, 2025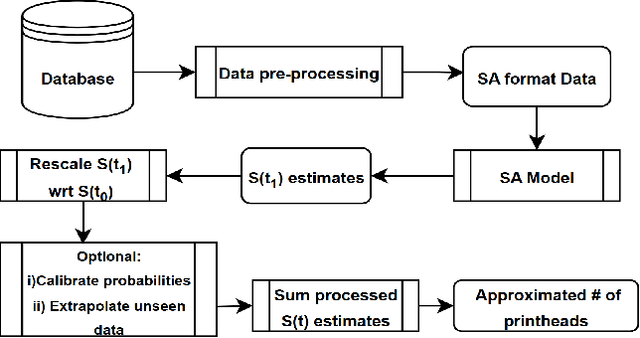
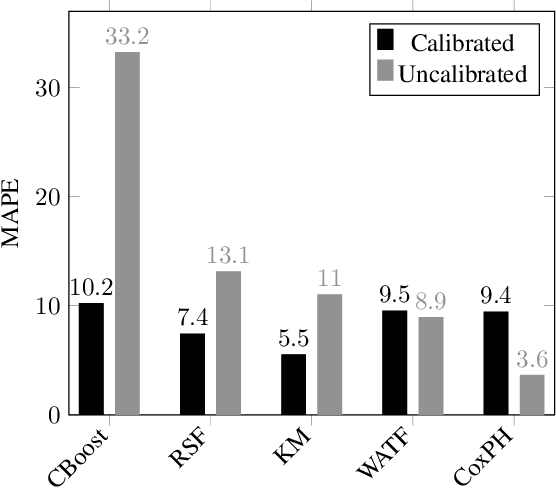
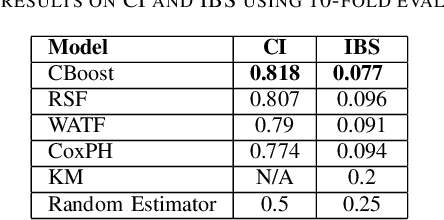
Accurately predicting the lifespan of critical device components is essential for maintenance planning and production optimization, making it a topic of significant interest in both academia and industry. In this work, we investigate the use of survival analysis for predicting the lifespan of production printheads developed by Canon Production Printing. Specifically, we focus on the application of five techniques to estimate survival probabilities and failure rates: the Kaplan-Meier estimator, Cox proportional hazard model, Weibull accelerated failure time model, random survival forest, and gradient boosting. The resulting estimates are further refined using isotonic regression and subsequently aggregated to determine the expected number of failures. The predictions are then validated against real-world ground truth data across multiple time windows to assess model reliability. Our quantitative evaluation using three performance metrics demonstrates that survival analysis outperforms industry-standard baseline methods for printhead lifespan prediction.
VFL-RPS: Relevant Participant Selection in Vertical Federated Learning
Feb 20, 2025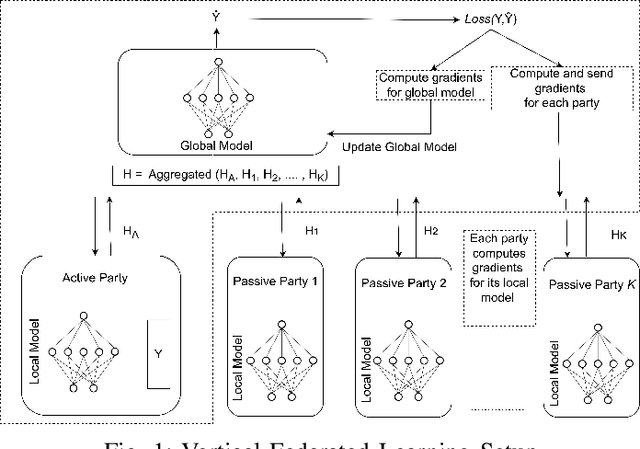
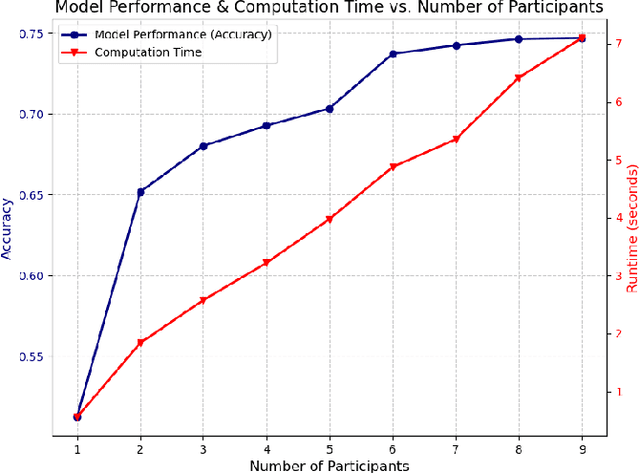
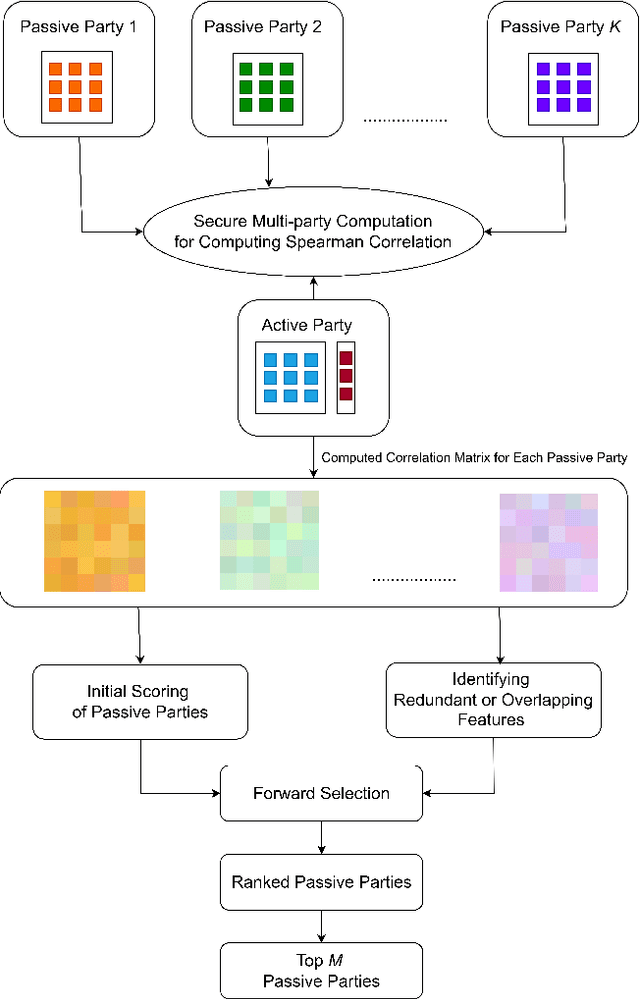
Federated Learning (FL) allows collaboration between different parties, while ensuring that the data across these parties is not shared. However, not every collaboration is helpful in terms of the resulting model performance. Therefore, it is an important challenge to select the correct participants in a collaboration. As it currently stands, most of the efforts in participant selection in the literature have focused on Horizontal Federated Learning (HFL), which assumes that all features are the same across all participants, disregarding the possibility of different features across participants which is captured in Vertical Federated Learning (VFL). To close this gap in the literature, we propose a novel method VFL-RPS for participant selection in VFL, as a pre-training step. We have tested our method on several data sets performing both regression and classification tasks, showing that our method leads to comparable results as using all data by only selecting a few participants. In addition, we show that our method outperforms existing methods for participant selection in VFL.
Overcoming the Limitations of Layer Synchronization in Spiking Neural Networks
Aug 09, 2024



Currently, neural-network processing in machine learning applications relies on layer synchronization, whereby neurons in a layer aggregate incoming currents from all neurons in the preceding layer, before evaluating their activation function. This is practiced even in artificial Spiking Neural Networks (SNNs), which are touted as consistent with neurobiology, in spite of processing in the brain being, in fact asynchronous. A truly asynchronous system however would allow all neurons to evaluate concurrently their threshold and emit spikes upon receiving any presynaptic current. Omitting layer synchronization is potentially beneficial, for latency and energy efficiency, but asynchronous execution of models previously trained with layer synchronization may entail a mismatch in network dynamics and performance. We present a study that documents and quantifies this problem in three datasets on our simulation environment that implements network asynchrony, and we show that models trained with layer synchronization either perform sub-optimally in absence of the synchronization, or they will fail to benefit from any energy and latency reduction, when such a mechanism is in place. We then "make ends meet" and address the problem with unlayered backprop, a novel backpropagation-based training method, for learning models suitable for asynchronous processing. We train with it models that use different neuron execution scheduling strategies, and we show that although their neurons are more reactive, these models consistently exhibit lower overall spike density (up to 50%), reach a correct decision faster (up to 2x) without integrating all spikes, and achieve superior accuracy (up to 10% higher). Our findings suggest that asynchronous event-based (neuromorphic) AI computing is indeed more efficient, but we need to seriously rethink how we train our SNN models, to benefit from it.
Event-based Optical Flow on Neuromorphic Processor: ANN vs. SNN Comparison based on Activation Sparsification
Jul 29, 2024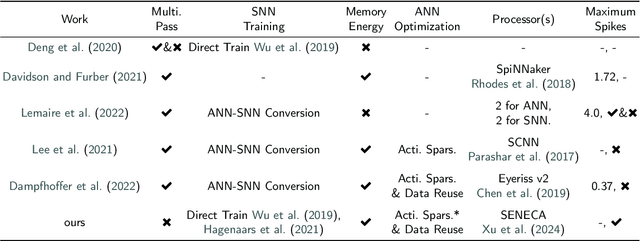
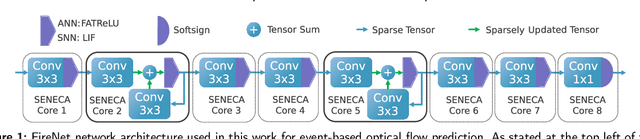
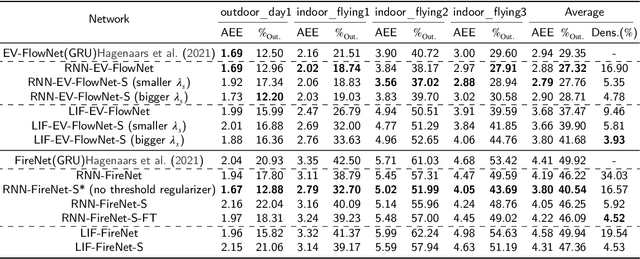
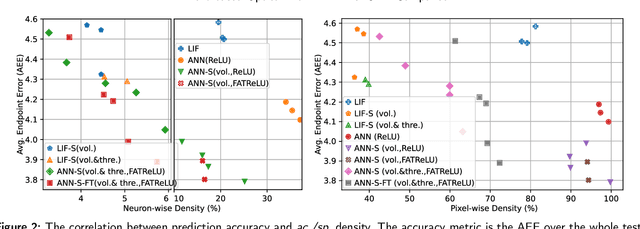
Spiking neural networks (SNNs) for event-based optical flow are claimed to be computationally more efficient than their artificial neural networks (ANNs) counterparts, but a fair comparison is missing in the literature. In this work, we propose an event-based optical flow solution based on activation sparsification and a neuromorphic processor, SENECA. SENECA has an event-driven processing mechanism that can exploit the sparsity in ANN activations and SNN spikes to accelerate the inference of both types of neural networks. The ANN and the SNN for comparison have similar low activation/spike density (~5%) thanks to our novel sparsification-aware training. In the hardware-in-loop experiments designed to deduce the average time and energy consumption, the SNN consumes 44.9ms and 927.0 microjoules, which are 62.5% and 75.2% of the ANN's consumption, respectively. We find that SNN's higher efficiency attributes to its lower pixel-wise spike density (43.5% vs. 66.5%) that requires fewer memory access operations for neuron states.