 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Methods for Detecting Thermal Runaway Events in Battery Production Lines
Apr 11, 2025
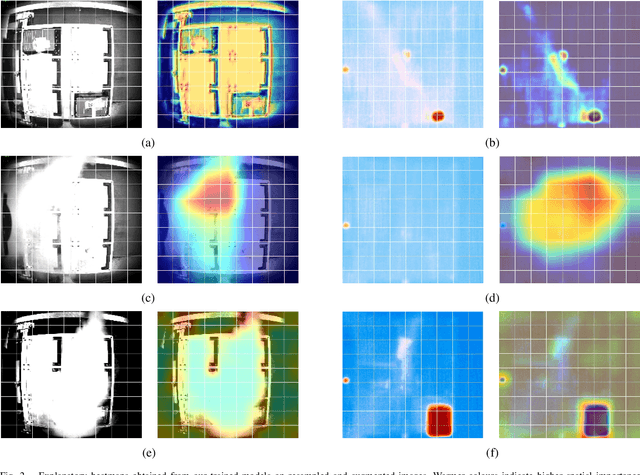
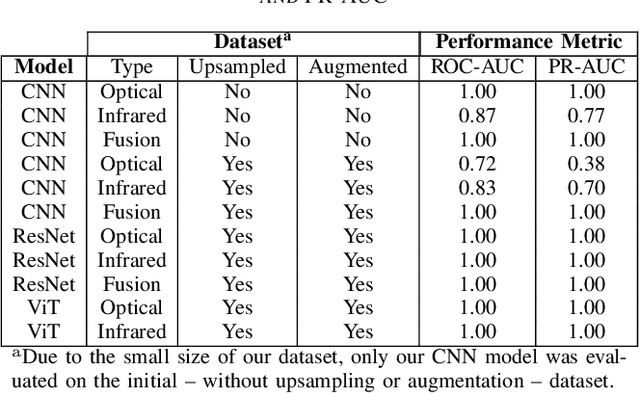
One of the key safety considerations of battery manufacturing is thermal runaway, the uncontrolled increase in temperature which can lead to fires, explosions, and emissions of toxic gasses. As such, development of automated systems capable of detecting such events is of considerable importance in both academic and industrial contexts. In this work, we investigate the use of deep learning for detecting thermal runaway in the battery production line of VDL Nedcar, a Dutch automobile manufacturer. Specifically, we collect data from the production line to represent both baseline (non thermal runaway) and thermal runaway conditions. Thermal runaway was simulated through the use of external heat and smoke sources. The data consisted of both optical and thermal images which were then preprocessed and fused before serving as input to our models. In this regard, we evaluated three deep-learning models widely used in computer vision including shallow convolutional neural networks, residual neural networks, and vision transformers on two performance metrics. Furthermore, we evaluated these models using explainability methods to gain insight into their ability to capture the relevant feature information from their inputs. The obtained results indicate that the use of deep learning is a viable approach to thermal runaway detection in battery production lines.
Predicting the Lifespan of Industrial Printheads with Survival Analysis
Apr 10, 2025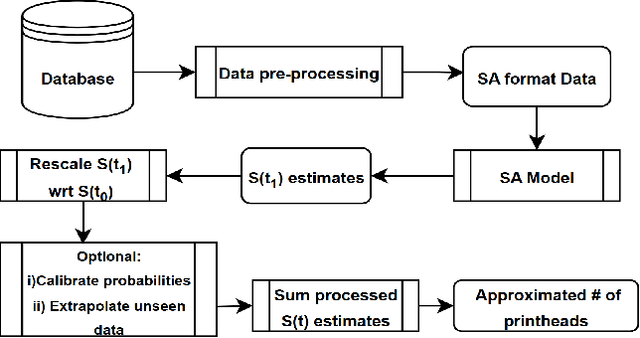
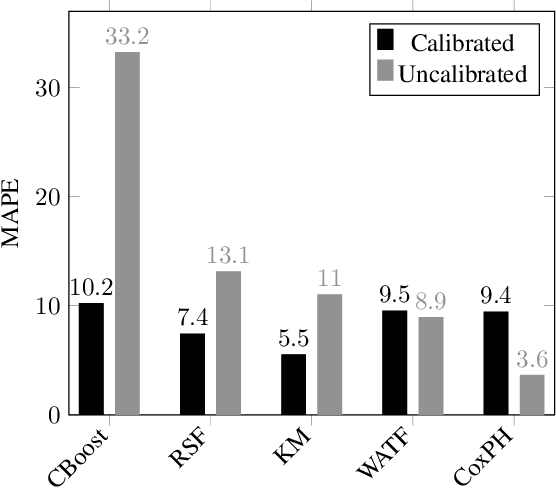
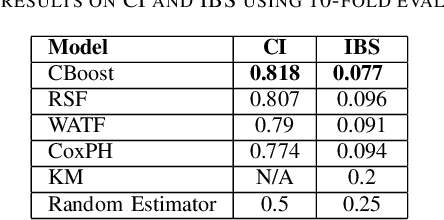
Accurately predicting the lifespan of critical device components is essential for maintenance planning and production optimization, making it a topic of significant interest in both academia and industry. In this work, we investigate the use of survival analysis for predicting the lifespan of production printheads developed by Canon Production Printing. Specifically, we focus on the application of five techniques to estimate survival probabilities and failure rates: the Kaplan-Meier estimator, Cox proportional hazard model, Weibull accelerated failure time model, random survival forest, and gradient boosting. The resulting estimates are further refined using isotonic regression and subsequently aggregated to determine the expected number of failures. The predictions are then validated against real-world ground truth data across multiple time windows to assess model reliability. Our quantitative evaluation using three performance metrics demonstrates that survival analysis outperforms industry-standard baseline methods for printhead lifespan prediction.
Hierarchical Blockmodelling for Knowledge Graphs
Aug 28, 2024In this paper, we investigate the use of probabilistic graphical models, specifically stochastic blockmodels, for the purpose of hierarchical entity clustering on knowledge graphs. These models, seldom used in the Semantic Web community, decompose a graph into a set of probability distributions. The parameters of these distributions are then inferred allowing for their subsequent sampling to generate a random graph. In a non-parametric setting, this allows for the induction of hierarchical clusterings without prior constraints on the hierarchy's structure. Specifically, this is achieved by the integration of the Nested Chinese Restaurant Process and the Stick Breaking Process into the generative model. In this regard, we propose a model leveraging such integration and derive a collapsed Gibbs sampling scheme for its inference. To aid in understanding, we describe the steps in this derivation and provide an implementation for the sampler. We evaluate our model on synthetic and real-world datasets and quantitatively compare against benchmark models. We further evaluate our results qualitatively and find that our model is capable of inducing coherent cluster hierarchies in small scale settings. The work presented in this paper provides the first step for the further application of stochastic blockmodels for knowledge graphs on a larger scale. We conclude the paper with potential avenues for future work on more scalable inference schemes.
Empirical Capacity Model for Self-Attention Neural Networks
Jul 22, 2024Large pretrained self-attention neural networks, or transformers, have been very successful in various tasks recently. The performance of a model on a given task depends on its ability to memorize and generalize the training data. Large transformer models, which may have billions of parameters, in theory have a huge capacity to memorize content. However, the current algorithms for the optimization fall short of the theoretical capacity, and the capacity is also highly dependent on the content. In this paper, we focus on the memory capacity of these models obtained using common training algorithms and synthetic training data. Based on the results, we derive an empirical capacity model (ECM) for a generic transformer. The ECM can be used to design task-specific transformer models with an optimal number of parameters in cases where the target memorization capability of the task can be defined.
Path Based Hierarchical Clustering on Knowledge Graphs
Sep 27, 2021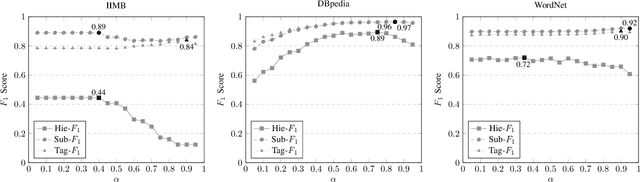
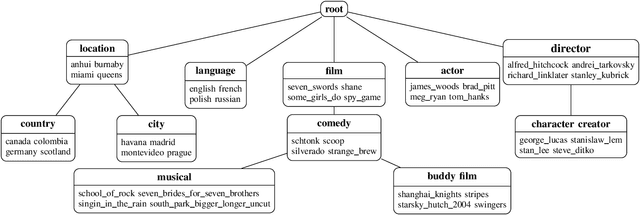
Knowledge graphs have emerged as a widely adopted medium for storing relational data, making methods for automatically reasoning with them highly desirable. In this paper, we present a novel approach for inducing a hierarchy of subject clusters, building upon our earlier work done in taxonomy induction. Our method first constructs a tag hierarchy before assigning subjects to clusters on this hierarchy. We quantitatively demonstrate our method's ability to induce a coherent cluster hierarchy on three real-world datasets.
Fragmentation Coagulation Based Mixed Membership Stochastic Blockmodel
Jan 17, 2020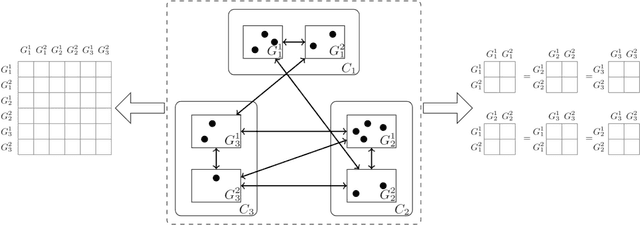
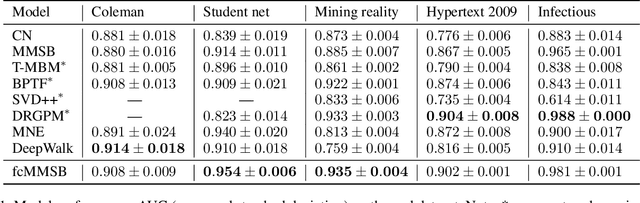
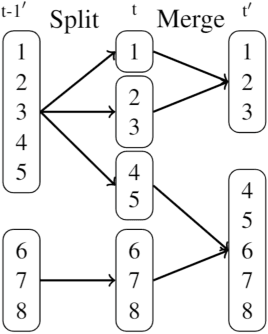
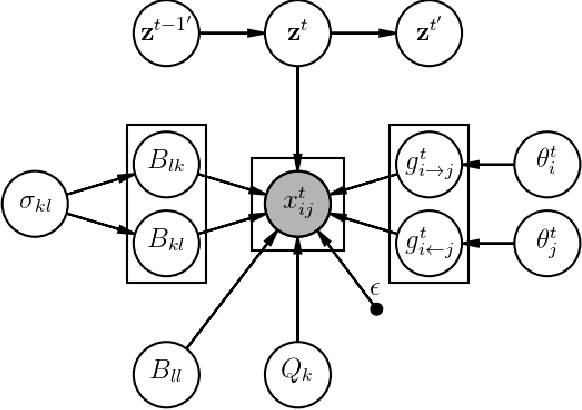
The Mixed-Membership Stochastic Blockmodel~(MMSB) is proposed as one of the state-of-the-art Bayesian relational methods suitable for learning the complex hidden structure underlying the network data. However, the current formulation of MMSB suffers from the following two issues: (1), the prior information~(e.g. entities' community structural information) can not be well embedded in the modelling; (2), community evolution can not be well described in the literature. Therefore, we propose a non-parametric fragmentation coagulation based Mixed Membership Stochastic Blockmodel (fcMMSB). Our model performs entity-based clustering to capture the community information for entities and linkage-based clustering to derive the group information for links simultaneously. Besides, the proposed model infers the network structure and models community evolution, manifested by appearances and disappearances of communities, using the discrete fragmentation coagulation process (DFCP). By integrating the community structure with the group compatibility matrix we derive a generalized version of MMSB. An efficient Gibbs sampling scheme with Polya Gamma (PG) approach is implemented for posterior inference. We validate our model on synthetic and real world data.
Animal Detection in Man-made Environments
Oct 24, 2019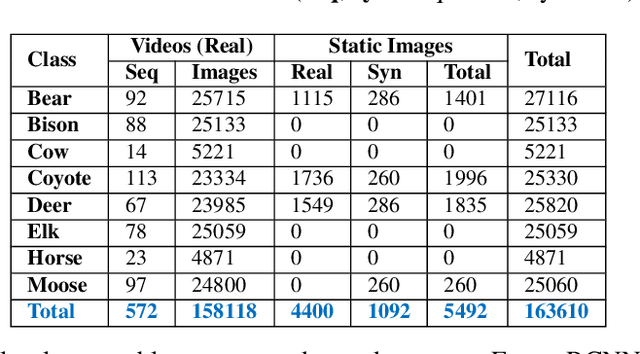


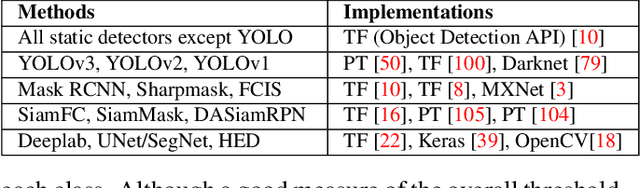
Automatic detection of animals that have strayed into human inhabited areas has important security and road safety applications. This paper attempts to solve this problem using deep learning techniques from a variety of computer vision fields including object detection, tracking, segmentation and edge detection. Several interesting insights are elicited into transfer learning while adapting models trained on benchmark datasets for real world deployment. Empirical evidence is presented to demonstrate the inability of detectors to generalize from training images of animals in their natural habitats to deployment scenarios of man-made environments. A solution is also proposed using semi-automated synthetic data generation for domain specific training. Code and data used in the experiments are made available to facilitate further work in this domain.