 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapacity Matters: a Proof-of-Concept for Transformer Memorization on Real-World Data
Jun 17, 2025This paper studies how the model architecture and data configurations influence the empirical memorization capacity of generative transformers. The models are trained using synthetic text datasets derived from the Systematized Nomenclature of Medicine (SNOMED) knowledge graph: triplets, representing static connections, and sequences, simulating complex relation patterns. The results show that embedding size is the primary determinant of learning speed and capacity, while additional layers provide limited benefits and may hinder performance on simpler datasets. Activation functions play a crucial role, and Softmax demonstrates greater stability and capacity. Furthermore, increasing the complexity of the data set seems to improve the final memorization. These insights improve our understanding of transformer memory mechanisms and provide a framework for optimizing model design with structured real-world data.
Fully Autonomous Programming using Iterative Multi-Agent Debugging with Large Language Models
Mar 10, 2025Program synthesis with Large Language Models (LLMs) suffers from a "near-miss syndrome": the generated code closely resembles a correct solution but fails unit tests due to minor errors. We address this with a multi-agent framework called Synthesize, Execute, Instruct, Debug, and Repair (SEIDR). Effectively applying SEIDR to instruction-tuned LLMs requires determining (a) optimal prompts for LLMs, (b) what ranking algorithm selects the best programs in debugging rounds, and (c) balancing the repair of unsuccessful programs with the generation of new ones. We empirically explore these trade-offs by comparing replace-focused, repair-focused, and hybrid debug strategies. We also evaluate lexicase and tournament selection to rank candidates in each generation. On Program Synthesis Benchmark 2 (PSB2), our framework outperforms both conventional use of OpenAI Codex without a repair phase and traditional genetic programming approaches. SEIDR outperforms the use of an LLM alone, solving 18 problems in C++ and 20 in Python on PSB2 at least once across experiments. To assess generalizability, we employ GPT-3.5 and Llama 3 on the PSB2 and HumanEval-X benchmarks. Although SEIDR with these models does not surpass current state-of-the-art methods on the Python benchmarks, the results on HumanEval-C++ are promising. SEIDR with Llama 3-8B achieves an average pass@100 of 84.2%. Across all SEIDR runs, 163 of 164 problems are solved at least once with GPT-3.5 in HumanEval-C++, and 162 of 164 with the smaller Llama 3-8B. We conclude that SEIDR effectively overcomes the near-miss syndrome in program synthesis with LLMs.
Empirical Capacity Model for Self-Attention Neural Networks
Jul 22, 2024Large pretrained self-attention neural networks, or transformers, have been very successful in various tasks recently. The performance of a model on a given task depends on its ability to memorize and generalize the training data. Large transformer models, which may have billions of parameters, in theory have a huge capacity to memorize content. However, the current algorithms for the optimization fall short of the theoretical capacity, and the capacity is also highly dependent on the content. In this paper, we focus on the memory capacity of these models obtained using common training algorithms and synthetic training data. Based on the results, we derive an empirical capacity model (ECM) for a generic transformer. The ECM can be used to design task-specific transformer models with an optimal number of parameters in cases where the target memorization capability of the task can be defined.
PhilHumans: Benchmarking Machine Learning for Personal Health
May 04, 2024



The use of machine learning in Healthcare has the potential to improve patient outcomes as well as broaden the reach and affordability of Healthcare. The history of other application areas indicates that strong benchmarks are essential for the development of intelligent systems. We present Personal Health Interfaces Leveraging HUman-MAchine Natural interactions (PhilHumans), a holistic suite of benchmarks for machine learning across different Healthcare settings - talk therapy, diet coaching, emergency care, intensive care, obstetric sonography - as well as different learning settings, such as action anticipation, timeseries modeling, insight mining, language modeling, computer vision, reinforcement learning and program synthesis
Schema-Driven Actionable Insight Generation and Smart Recommendation
Jul 24, 2023


In natural language generation (NLG), insight mining is seen as a data-to-text task, where data is mined for interesting patterns and verbalised into 'insight' statements. An 'over-generate and rank' paradigm is intuitively used to generate such insights. The multidimensionality and subjectivity of this process make it challenging. This paper introduces a schema-driven method to generate actionable insights from data to drive growth and change. It also introduces a technique to rank the insights to align with user interests based on their feedback. We show preliminary qualitative results of the insights generated using our technique and demonstrate its ability to adapt to feedback.
Opinion Mining Using Population-tuned Generative Language Models
Jul 24, 2023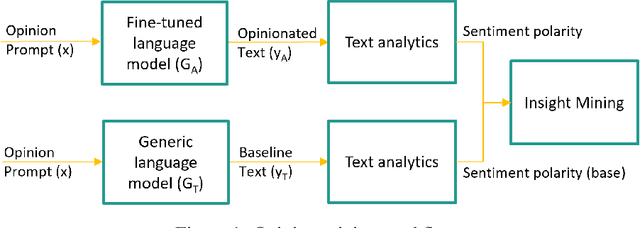



We present a novel method for mining opinions from text collections using generative language models trained on data collected from different populations. We describe the basic definitions, methodology and a generic algorithm for opinion insight mining. We demonstrate the performance of our method in an experiment where a pre-trained generative model is fine-tuned using specifically tailored content with unnatural and fully annotated opinions. We show that our approach can learn and transfer the opinions to the semantic classes while maintaining the proportion of polarisation. Finally, we demonstrate the usage of an insight mining system to scale up the discovery of opinion insights from a real text corpus.
Sensing of inspiration events from speech: comparison of deep learning and linguistic methods
May 19, 2023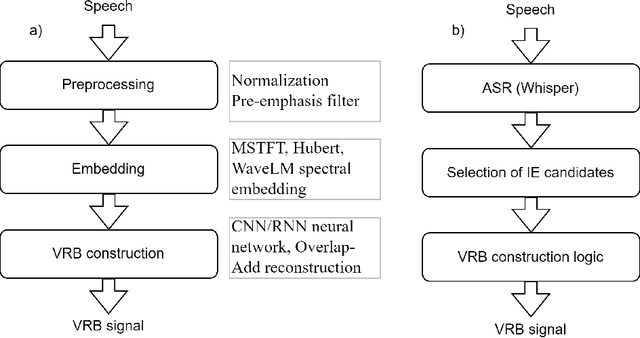

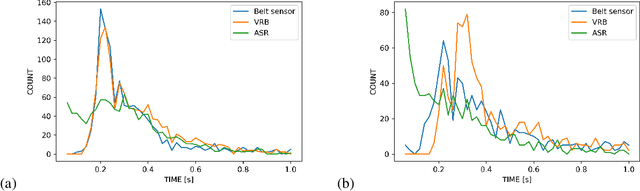

Respiratory chest belt sensor can be used to measure the respiratory rate and other respiratory health parameters. Virtual Respiratory Belt, VRB, algorithms estimate the belt sensor waveform from speech audio. In this paper we compare the detection of inspiration events (IE) from respiratory belt sensor data using a novel neural VRB algorithm and the detections based on time-aligned linguistic content. The results show the superiority of the VRB method over word pause detection or grammatical content segmentation. The comparison of the methods show that both read and spontaneous speech content has a significant amount of ungrammatical breathing, that is, breathing events that are not aligned with grammatically appropriate places in language. This study gives new insights into the development of VRB methods and adds to the general understanding of speech breathing behavior. Moreover, a new VRB method, VRBOLA, for the reconstruction of the continuous breathing waveform is demonstrated.
Fully Autonomous Programming with Large Language Models
Apr 20, 2023



Current approaches to program synthesis with Large Language Models (LLMs) exhibit a "near miss syndrome": they tend to generate programs that semantically resemble the correct answer (as measured by text similarity metrics or human evaluation), but achieve a low or even zero accuracy as measured by unit tests due to small imperfections, such as the wrong input or output format. This calls for an approach known as Synthesize, Execute, Debug (SED), whereby a draft of the solution is generated first, followed by a program repair phase addressing the failed tests. To effectively apply this approach to instruction-driven LLMs, one needs to determine which prompts perform best as instructions for LLMs, as well as strike a balance between repairing unsuccessful programs and replacing them with newly generated ones. We explore these trade-offs empirically, comparing replace-focused, repair-focused, and hybrid debug strategies, as well as different template-based and model-based prompt-generation techniques. We use OpenAI Codex as the LLM and Program Synthesis Benchmark 2 as a database of problem descriptions and tests for evaluation. The resulting framework outperforms both conventional usage of Codex without the repair phase and traditional genetic programming approaches.
A Survey on Human-aware Robot Navigation
Jun 22, 2021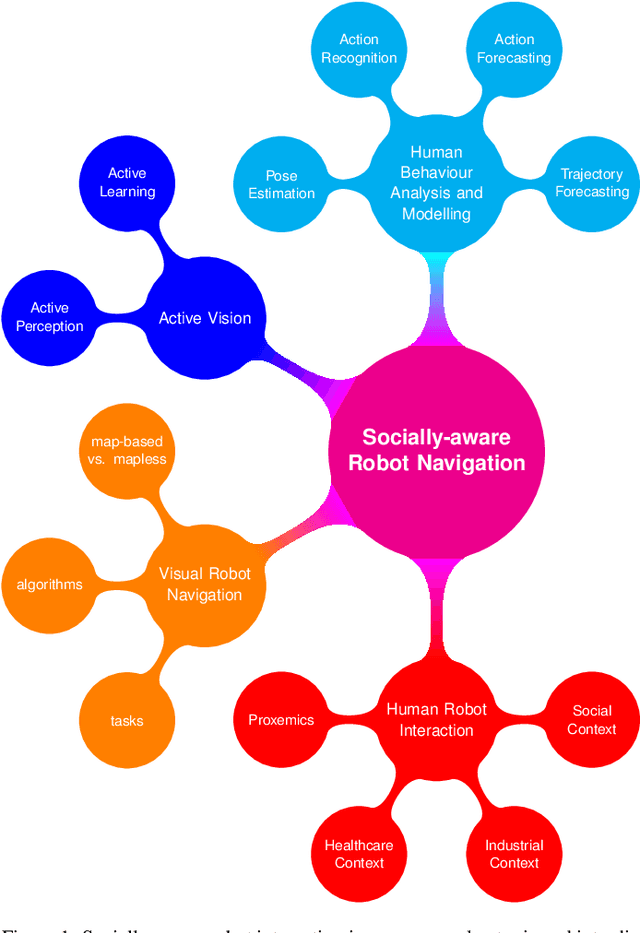
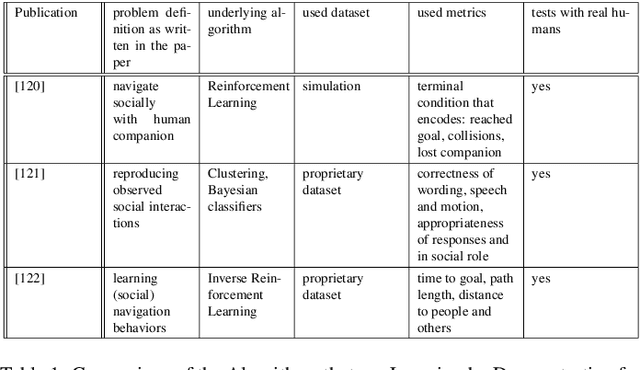

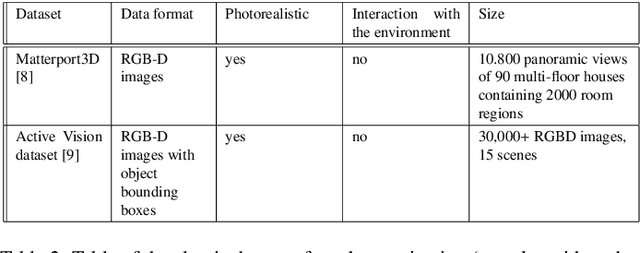
Intelligent systems are increasingly part of our everyday lives and have been integrated seamlessly to the point where it is difficult to imagine a world without them. Physical manifestations of those systems on the other hand, in the form of embodied agents or robots, have so far been used only for specific applications and are often limited to functional roles (e.g. in the industry, entertainment and military fields). Given the current growth and innovation in the research communities concerned with the topics of robot navigation, human-robot-interaction and human activity recognition, it seems like this might soon change. Robots are increasingly easy to obtain and use and the acceptance of them in general is growing. However, the design of a socially compliant robot that can function as a companion needs to take various areas of research into account. This paper is concerned with the navigation aspect of a socially-compliant robot and provides a survey of existing solutions for the relevant areas of research as well as an outlook on possible future directions.
BF++: a language for general-purpose program synthesis
Feb 18, 2021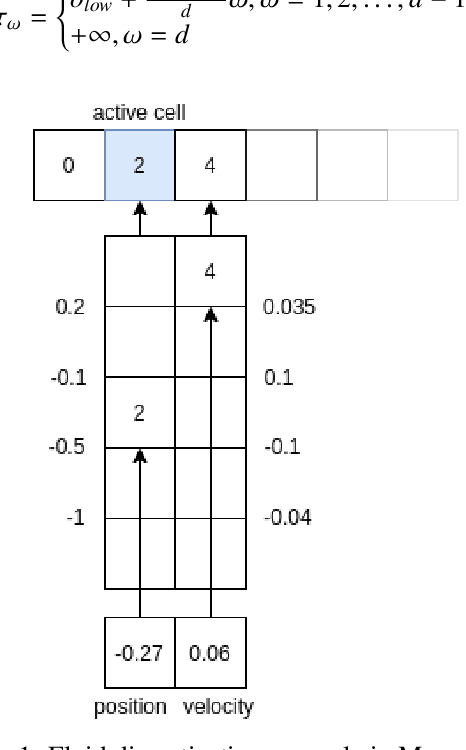
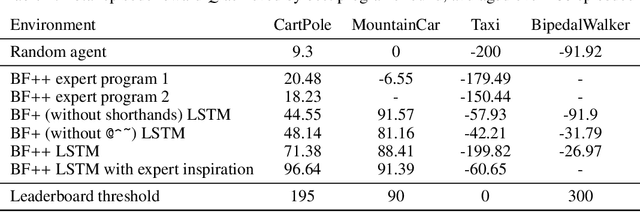
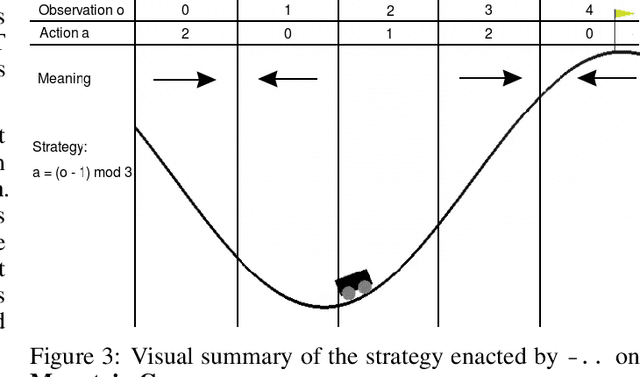
Most state of the art decision systems based on Reinforcement Learning (RL) are data-driven black-box neural models, where it is often difficult to incorporate expert knowledge into the models or let experts review and validate the learned decision mechanisms. Knowledge-insertion and model review are important requirements in many applications involving human health and safety. One way to bridge the gap between data and knowledge driven systems is program synthesis: replacing a neural network that outputs decisions with a symbolic program generated by a neural network or by means of genetic programming. We propose a new programming language, BF++, designed specifically for automatic programming of agents in a Partially Observable Markov Decision Process (POMDP) setting and apply neural program synthesis to solve standard OpenAI Gym benchmarks.