 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Gaze and Set-of-Mark in VLLMs for Human-Object Interaction Anticipation from Egocentric Videos
Apr 04, 2026The ability to anticipate human-object interactions is highly desirable in an intelligent assistive system in order to guide users during daily life activities and understand their short and long-term goals. Creating systems with such capabilities requires to approach several complex challenges. This work addresses the problem of human-object interaction anticipation in Egocentric Vision using Vision Large Language Models (VLLMs). We tackle key limitations in existing approaches by improving visual grounding capabilities through Set-of-Mark prompting and understanding user intent via the trajectory formed by the user's most recent gaze fixations. To effectively capture the temporal dynamics immediately preceding the interaction, we further introduce a novel inverse exponential sampling strategy for input video frames. Experiments conducted on the egocentric dataset HD-EPIC demonstrate that our method surpasses state-of-the-art approaches for the considered task, showing its model-agnostic nature.
Leveraging Synthetic Data for Enhancing Egocentric Hand-Object Interaction Detection
Mar 31, 2026In this work, we explore the role of synthetic data in improving the detection of Hand-Object Interactions from egocentric images. Through extensive experimentation and comparative analysis on VISOR, EgoHOS, and ENIGMA-51 datasets, our findings demonstrate the potential of synthetic data to significantly improve HOI detection, particularly when real labeled data are scarce or unavailable. By using synthetic data and only 10% of the real labeled data, we achieve improvements in Overall AP over models trained exclusively on real data, with gains of +5.67% on VISOR, +8.24% on EgoHOS, and +11.69% on ENIGMA-51. Furthermore, we systematically study how aligning synthetic data to specific real-world benchmarks with respect to objects, grasps, and environments, showing that the effectiveness of synthetic data consistently improves with better synthetic-real alignment. As a result of this work, we release a new data generation pipeline and the new HOI-Synth benchmark, which augments existing datasets with synthetic images of hand-object interaction. These data are automatically annotated with hand-object contact states, bounding boxes, and pixel-wise segmentation masks. All data, code, and tools for synthetic data generation are available at: https://fpv-iplab.github.io/HOI-Synth/.
ENIGMA-360: An Ego-Exo Dataset for Human Behavior Understanding in Industrial Scenarios
Mar 11, 2026Understanding human behavior from complementary egocentric (ego) and exocentric (exo) points of view enables the development of systems that can support workers in industrial environments and enhance their safety. However, progress in this area is hindered by the lack of datasets capturing both views in realistic industrial scenarios. To address this gap, we propose ENIGMA-360, a new ego-exo dataset acquired in a real industrial scenario. The dataset is composed of 180 egocentric and 180 exocentric procedural videos temporally synchronized offering complementary information of the same scene. The 360 videos have been labeled with temporal and spatial annotations, enabling the study of different aspects of human behavior in industrial domain. We provide baseline experiments for 3 foundational tasks for human behavior understanding: 1) Temporal Action Segmentation, 2) Keystep Recognition and 3) Egocentric Human-Object Interaction Detection, showing the limits of state-of-the-art approaches on this challenging scenario. These results highlight the need for new models capable of robust ego-exo understanding in real-world environments. We publicly release the dataset and its annotations at https://fpv-iplab.github.io/ENIGMA-360/.
ProSkill: Segment-Level Skill Assessment in Procedural Videos
Jan 28, 2026Skill assessment in procedural videos is crucial for the objective evaluation of human performance in settings such as manufacturing and procedural daily tasks. Current research on skill assessment has predominantly focused on sports and lacks large-scale datasets for complex procedural activities. Existing studies typically involve only a limited number of actions, focus on either pairwise assessments (e.g., A is better than B) or on binary labels (e.g., good execution vs needs improvement). In response to these shortcomings, we introduce ProSkill, the first benchmark dataset for action-level skill assessment in procedural tasks. ProSkill provides absolute skill assessment annotations, along with pairwise ones. This is enabled by a novel and scalable annotation protocol that allows for the creation of an absolute skill assessment ranking starting from pairwise assessments. This protocol leverages a Swiss Tournament scheme for efficient pairwise comparisons, which are then aggregated into consistent, continuous global scores using an ELO-based rating system. We use our dataset to benchmark the main state-of-the-art skill assessment algorithms, including both ranking-based and pairwise paradigms. The suboptimal results achieved by the current state-of-the-art highlight the challenges and thus the value of ProSkill in the context of skill assessment for procedural videos. All data and code are available at https://fpv-iplab.github.io/ProSkill/
GlovEgo-HOI: Bridging the Synthetic-to-Real Gap for Industrial Egocentric Human-Object Interaction Detection
Jan 14, 2026Egocentric Human-Object Interaction (EHOI) analysis is crucial for industrial safety, yet the development of robust models is hindered by the scarcity of annotated domain-specific data. We address this challenge by introducing a data generation framework that combines synthetic data with a diffusion-based process to augment real-world images with realistic Personal Protective Equipment (PPE). We present GlovEgo-HOI, a new benchmark dataset for industrial EHOI, and GlovEgo-Net, a model integrating Glove-Head and Keypoint- Head modules to leverage hand pose information for enhanced interaction detection. Extensive experiments demonstrate the effectiveness of the proposed data generation framework and GlovEgo-Net. To foster further research, we release the GlovEgo-HOI dataset, augmentation pipeline, and pre-trained models at: GitHub project.
SignIT: A Comprehensive Dataset and Multimodal Analysis for Italian Sign Language Recognition
Dec 16, 2025In this work we present SignIT, a new dataset to study the task of Italian Sign Language (LIS) recognition. The dataset is composed of 644 videos covering 3.33 hours. We manually annotated videos considering a taxonomy of 94 distinct sign classes belonging to 5 macro-categories: Animals, Food, Colors, Emotions and Family. We also extracted 2D keypoints related to the hands, face and body of the users. With the dataset, we propose a benchmark for the sign recognition task, adopting several state-of-the-art models showing how temporal information, 2D keypoints and RGB frames can be influence the performance of these models. Results show the limitations of these models on this challenging LIS dataset. We release data and annotations at the following link: https://fpv-iplab.github.io/SignIT/.
Ego-EXTRA: video-language Egocentric Dataset for EXpert-TRAinee assistance
Dec 15, 2025We present Ego-EXTRA, a video-language Egocentric Dataset for EXpert-TRAinee assistance. Ego-EXTRA features 50 hours of unscripted egocentric videos of subjects performing procedural activities (the trainees) while guided by real-world experts who provide guidance and answer specific questions using natural language. Following a ``Wizard of OZ'' data collection paradigm, the expert enacts a wearable intelligent assistant, looking at the activities performed by the trainee exclusively from their egocentric point of view, answering questions when asked by the trainee, or proactively interacting with suggestions during the procedures. This unique data collection protocol enables Ego-EXTRA to capture a high-quality dialogue in which expert-level feedback is provided to the trainee. Two-way dialogues between experts and trainees are recorded, transcribed, and used to create a novel benchmark comprising more than 15k high-quality Visual Question Answer sets, which we use to evaluate Multimodal Large Language Models. The results show that Ego-EXTRA is challenging and highlight the limitations of current models when used to provide expert-level assistance to the user. The Ego-EXTRA dataset is publicly available to support the benchmark of egocentric video-language assistants: https://fpv-iplab.github.io/Ego-EXTRA/.
A Real-Time System for Egocentric Hand-Object Interaction Detection in Industrial Domains
Jul 17, 2025Hand-object interaction detection remains an open challenge in real-time applications, where intuitive user experiences depend on fast and accurate detection of interactions with surrounding objects. We propose an efficient approach for detecting hand-objects interactions from streaming egocentric vision that operates in real time. Our approach consists of an action recognition module and an object detection module for identifying active objects upon confirmed interaction. Our Mamba model with EfficientNetV2 as backbone for action recognition achieves 38.52% p-AP on the ENIGMA-51 benchmark at 30fps, while our fine-tuned YOLOWorld reaches 85.13% AP for hand and object. We implement our models in a cascaded architecture where the action recognition and object detection modules operate sequentially. When the action recognition predicts a contact state, it activates the object detection module, which in turn performs inference on the relevant frame to detect and classify the active object.
Calisthenics Skills Temporal Video Segmentation
Jul 16, 2025
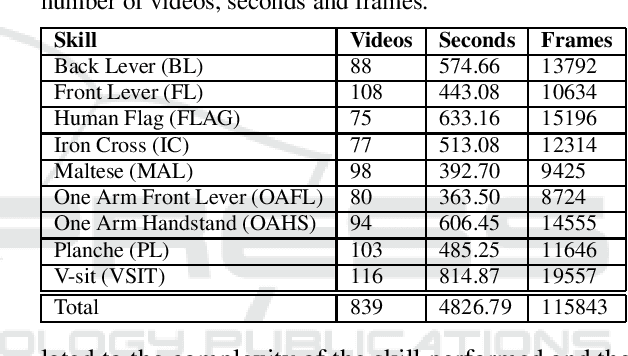

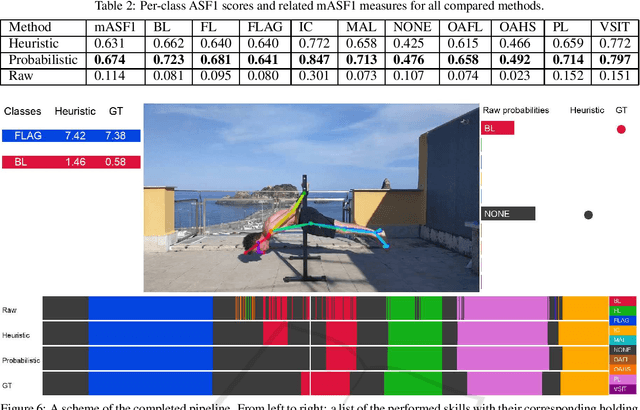
Calisthenics is a fast-growing bodyweight discipline that consists of different categories, one of which is focused on skills. Skills in calisthenics encompass both static and dynamic elements performed by athletes. The evaluation of static skills is based on their difficulty level and the duration of the hold. Automated tools able to recognize isometric skills from a video by segmenting them to estimate their duration would be desirable to assist athletes in their training and judges during competitions. Although the video understanding literature on action recognition through body pose analysis is rich, no previous work has specifically addressed the problem of calisthenics skill temporal video segmentation. This study aims to provide an initial step towards the implementation of automated tools within the field of Calisthenics. To advance knowledge in this context, we propose a dataset of video footage of static calisthenics skills performed by athletes. Each video is annotated with a temporal segmentation which determines the extent of each skill. We hence report the results of a baseline approach to address the problem of skill temporal segmentation on the proposed dataset. The results highlight the feasibility of the proposed problem, while there is still room for improvement.
Efficient Calisthenics Skills Classification through Foreground Instance Selection and Depth Estimation
Jul 16, 2025
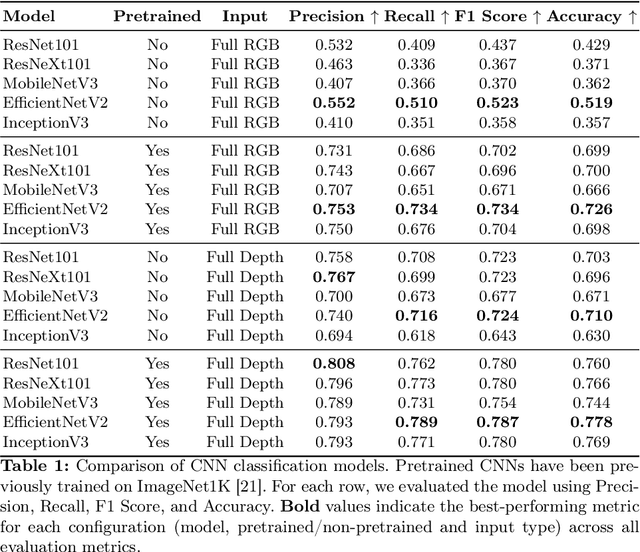
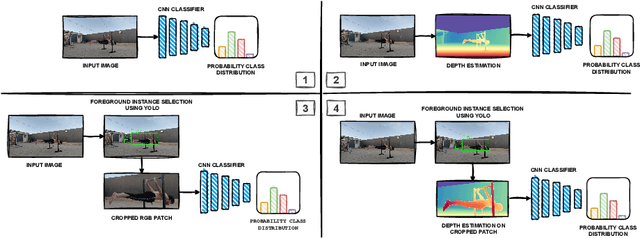
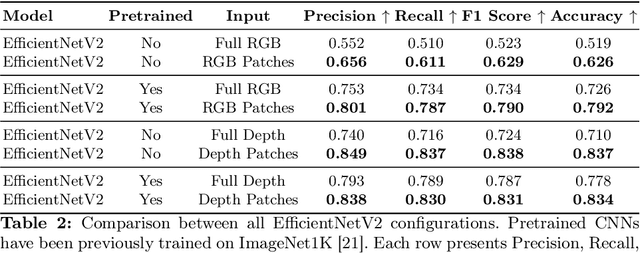
Calisthenics skill classification is the computer vision task of inferring the skill performed by an athlete from images, enabling automatic performance assessment and personalized analytics. Traditional methods for calisthenics skill recognition are based on pose estimation methods to determine the position of skeletal data from images, which is later fed to a classification algorithm to infer the performed skill. Despite the progress in human pose estimation algorithms, they still involve high computational costs, long inference times, and complex setups, which limit the applicability of such approaches in real-time applications or mobile devices. This work proposes a direct approach to calisthenics skill recognition, which leverages depth estimation and athlete patch retrieval to avoid the computationally expensive human pose estimation module. Using Depth Anything V2 for depth estimation and YOLOv10 for athlete localization, we segment the subject from the background rather than relying on traditional pose estimation techniques. This strategy increases efficiency, reduces inference time, and improves classification accuracy. Our approach significantly outperforms skeleton-based methods, achieving 38.3x faster inference with RGB image patches and improved classification accuracy with depth patches (0.837 vs. 0.815). Beyond these performance gains, the modular design of our pipeline allows for flexible replacement of components, enabling future enhancements and adaptation to real-world applications.