 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViterbiPlanNet: Injecting Procedural Knowledge via Differentiable Viterbi for Planning in Instructional Videos
Mar 04, 2026Procedural planning aims to predict a sequence of actions that transforms an initial visual state into a desired goal, a fundamental ability for intelligent agents operating in complex environments. Existing approaches typically rely on large-scale models that learn procedural structures implicitly, resulting in limited sample-efficiency and high computational cost. In this work we introduce ViterbiPlanNet, a principled framework that explicitly integrates procedural knowledge into the learning process through a Differentiable Viterbi Layer (DVL). The DVL embeds a Procedural Knowledge Graph (PKG) directly with the Viterbi decoding algorithm, replacing non-differentiable operations with smooth relaxations that enable end-to-end optimization. This design allows the model to learn through graph-based decoding. Experiments on CrossTask, COIN, and NIV demonstrate that ViterbiPlanNet achieves state-of-the-art performance with an order of magnitude fewer parameters than diffusion- and LLM-based planners. Extensive ablations show that performance gains arise from our differentiable structure-aware training rather than post-hoc refinement, resulting in improved sample efficiency and robustness to shorter unseen horizons. We also address testing inconsistencies establishing a unified testing protocol with consistent splits and evaluation metrics. With this new protocol, we run experiments multiple times and report results using bootstrapping to assess statistical significance.
Task Graph Maximum Likelihood Estimation for Procedural Activity Understanding in Egocentric Videos
Feb 26, 2025We introduce a gradient-based approach for learning task graphs from procedural activities, improving over hand-crafted methods. Our method directly optimizes edge weights via maximum likelihood, enabling integration into neural architectures. We validate our approach on CaptainCook4D, EgoPER, and EgoProceL, achieving +14.5%, +10.2%, and +13.6% F1-score improvements. Our feature-based approach for predicting task graphs from textual/video embeddings demonstrates emerging video understanding abilities. We also achieved top performance on the procedure understanding benchmark on Ego-Exo4D and significantly improved online mistake detection (+19.8% on Assembly101-O, +6.4% on EPIC-Tent-O). Code: https://github.com/fpv-iplab/Differentiable-Task-Graph-Learning.
Differentiable Task Graph Learning: Procedural Activity Representation and Online Mistake Detection from Egocentric Videos
Jun 03, 2024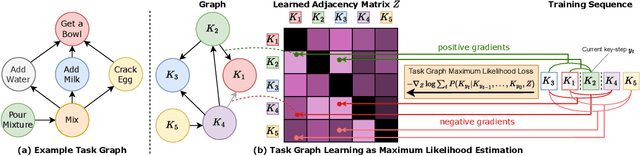
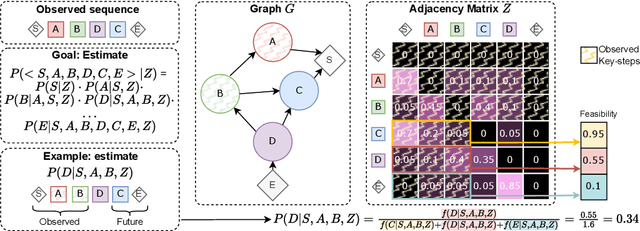
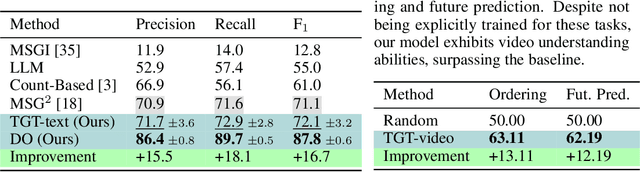

Procedural activities are sequences of key-steps aimed at achieving specific goals. They are crucial to build intelligent agents able to assist users effectively. In this context, task graphs have emerged as a human-understandable representation of procedural activities, encoding a partial ordering over the key-steps. While previous works generally relied on hand-crafted procedures to extract task graphs from videos, in this paper, we propose an approach based on direct maximum likelihood optimization of edges' weights, which allows gradient-based learning of task graphs and can be naturally plugged into neural network architectures. Experiments on the CaptainCook4D dataset demonstrate the ability of our approach to predict accurate task graphs from the observation of action sequences, with an improvement of +16.7% over previous approaches. Owing to the differentiability of the proposed framework, we also introduce a feature-based approach, aiming to predict task graphs from key-step textual or video embeddings, for which we observe emerging video understanding abilities. Task graphs learned with our approach are also shown to significantly enhance online mistake detection in procedural egocentric videos, achieving notable gains of +19.8% and +7.5% on the Assembly101 and EPIC-Tent datasets. Code for replicating experiments is available at https://github.com/fpv-iplab/Differentiable-Task-Graph-Learning.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.