 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SA-FARI Dataset: Segment Anything in Footage of Animals for Recognition and Identification
Nov 19, 2025Automated video analysis is critical for wildlife conservation. A foundational task in this domain is multi-animal tracking (MAT), which underpins applications such as individual re-identification and behavior recognition. However, existing datasets are limited in scale, constrained to a few species, or lack sufficient temporal and geographical diversity - leaving no suitable benchmark for training general-purpose MAT models applicable across wild animal populations. To address this, we introduce SA-FARI, the largest open-source MAT dataset for wild animals. It comprises 11,609 camera trap videos collected over approximately 10 years (2014-2024) from 741 locations across 4 continents, spanning 99 species categories. Each video is exhaustively annotated culminating in ~46 hours of densely annotated footage containing 16,224 masklet identities and 942,702 individual bounding boxes, segmentation masks, and species labels. Alongside the task-specific annotations, we publish anonymized camera trap locations for each video. Finally, we present comprehensive benchmarks on SA-FARI using state-of-the-art vision-language models for detection and tracking, including SAM 3, evaluated with both species-specific and generic animal prompts. We also compare against vision-only methods developed specifically for wildlife analysis. SA-FARI is the first large-scale dataset to combine high species diversity, multi-region coverage, and high-quality spatio-temporal annotations, offering a new foundation for advancing generalizable multianimal tracking in the wild. The dataset is available at $\href{https://www.conservationxlabs.com/sa-fari}{\text{conservationxlabs.com/SA-FARI}}$.
PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021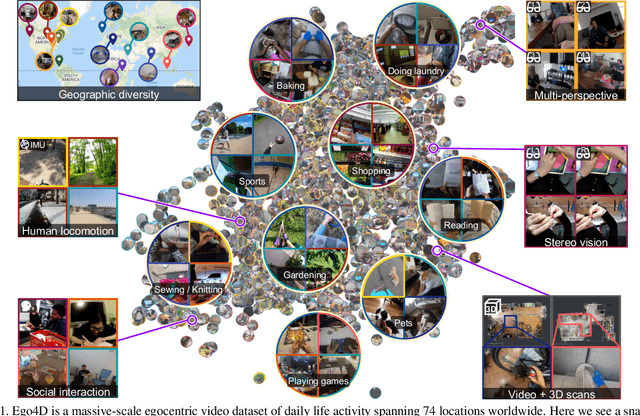
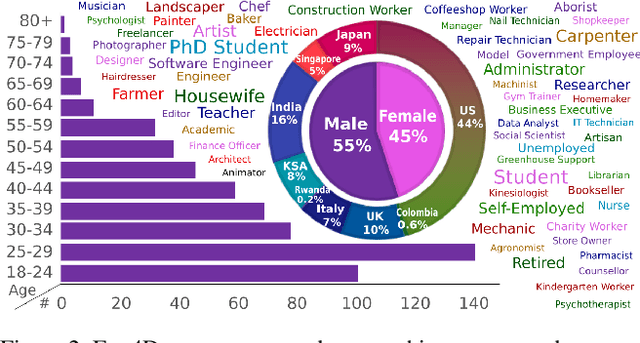

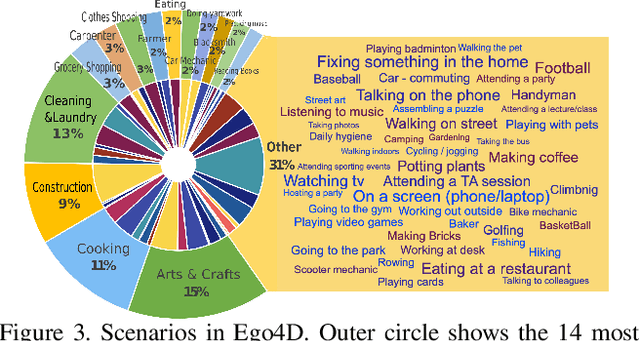
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
Sep 16, 2021

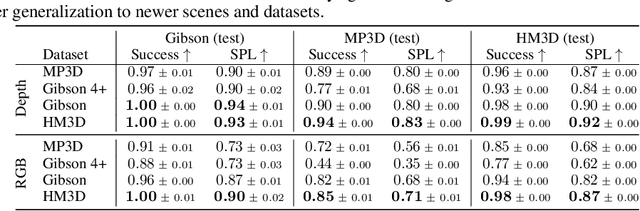
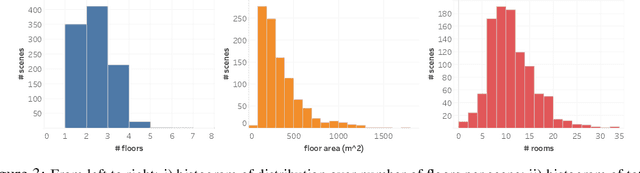
We present the Habitat-Matterport 3D (HM3D) dataset. HM3D is a large-scale dataset of 1,000 building-scale 3D reconstructions from a diverse set of real-world locations. Each scene in the dataset consists of a textured 3D mesh reconstruction of interiors such as multi-floor residences, stores, and other private indoor spaces. HM3D surpasses existing datasets available for academic research in terms of physical scale, completeness of the reconstruction, and visual fidelity. HM3D contains 112.5k m^2 of navigable space, which is 1.4 - 3.7x larger than other building-scale datasets such as MP3D and Gibson. When compared to existing photorealistic 3D datasets such as Replica, MP3D, Gibson, and ScanNet, images rendered from HM3D have 20 - 85% higher visual fidelity w.r.t. counterpart images captured with real cameras, and HM3D meshes have 34 - 91% fewer artifacts due to incomplete surface reconstruction. The increased scale, fidelity, and diversity of HM3D directly impacts the performance of embodied AI agents trained using it. In fact, we find that HM3D is `pareto optimal' in the following sense -- agents trained to perform PointGoal navigation on HM3D achieve the highest performance regardless of whether they are evaluated on HM3D, Gibson, or MP3D. No similar claim can be made about training on other datasets. HM3D-trained PointNav agents achieve 100% performance on Gibson-test dataset, suggesting that it might be time to retire that episode dataset.